线性分类器:原理与决策超平面解析
"线性分类器"
线性分类器是一种广泛应用的机器学习模型,它通过在特征空间中构建一个线性的决策边界来对样本进行分类。这类分类器的基础在于找到一组参数,使得根据这些参数定义的分类规则在给定的准则下达到最优。线性分类器的设计通常涉及到线性判别函数和决策超平面的概念。
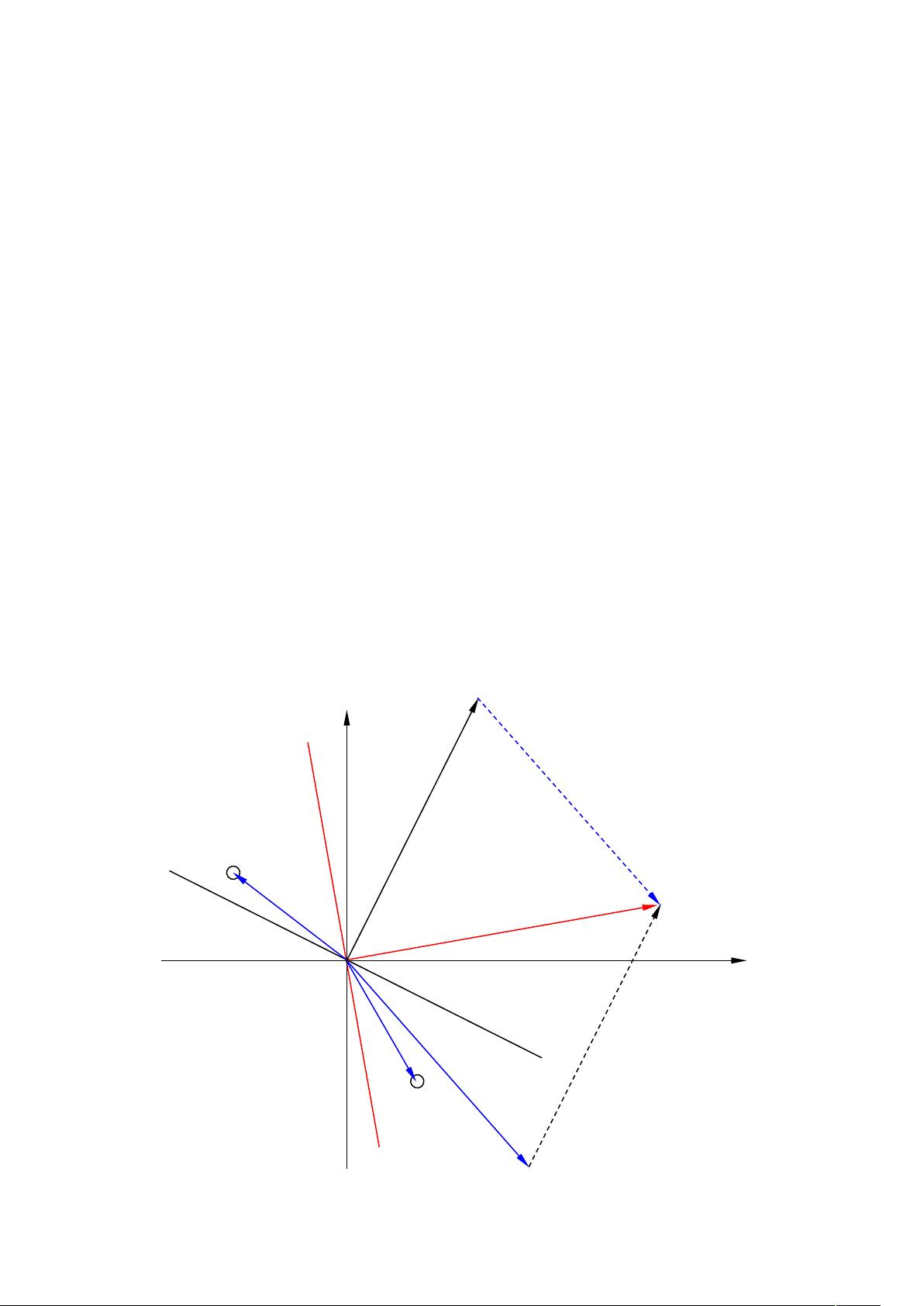
线性判别函数是决定样本所属类别的数学表达式。对于二维空间中的两类问题,线性决策超平面可以表示为一个直线方程,例如 \( w_1x_1 + w_2x_2 + b = 0 \),其中 \( w_1, w_2 \) 是权重向量的分量,\( b \) 是阈值,\( x_1, x_2 \) 是特征坐标。决策超平面将特征空间划分为两部分,使得来自不同类别的样本分别位于超平面的两侧。权值向量 \( w \) 对应于超平面的法向量,其方向决定了分类的方向,而阈值 \( b \) 决定了超平面的位置。
线性分类器的一个显著特点是其简洁性和计算效率。然而,由于决策边界是线性的,当数据不是线性可分时,线性分类器可能无法达到很高的分类精度。为了适应非线性数据,可以采用一些策略,比如特征工程来创造新的线性可分特征,或者使用核技巧,如支持向量机(SVM)中的核函数,将数据映射到更高维度的特征空间,使得在那个空间中数据变得线性可分。
在多类分类问题中,线性分类器的决策规则可能会变得更复杂。对于K类分类问题,决策超平面不再是简单的线性边界,而是由多个线性边界构成的决策区域。每个类别都有一个与之对应的线性决策边界,样本会根据这些边界被分配到最近的类别。
线性分类器的一个关键特性是它们通常执行线性变换,这意味着它们能够捕获特征之间的线性关系,但无法捕捉非线性关系。尽管如此,线性分类器在许多实际应用中仍然表现出色,特别是在处理大规模数据集时,因为它们通常比非线性模型更快且更容易解释。
线性分类器的性能可以通过不同的评估指标来衡量,例如准确率、召回率、F1分数等。同时,优化算法如梯度下降法或正规化方法(如L1或L2正则化)可以用来寻找最优的权重向量和阈值,以降低分类错误并防止过拟合。
线性分类器是一种基本且重要的机器学习工具,它的理解与应用对于机器学习初学者和专家来说都至关重要。尽管它们在处理复杂非线性问题时可能表现有限,但在许多实际场景中,线性模型提供了足够的预测能力,并且具备易于理解和实施的优点。

,这是过坐标原点的超维平面。对一般方程 ,
只需令 、 即可。设
为错分样本的集合,则误差函数为
其中, 与样本是否被错分有关。判别规则为
设样本 的类别为已知(当然来自于训练集),但
为了确定一组最佳的 ,对(3-12)求偏导,则有
根据梯度下降算法,有
式中,
为学习率,或称之为步长,
为迭代次数。
特别地,设
=1,只有来自
1
的样本 和来自
2
的样本 被错分,
(3.16)变为
42
剩余32页未读,继续阅读
2022-08-03 上传
2021-05-05 上传
2022-05-09 上传
2021-09-29 上传
2023-04-07 上传
2021-10-04 上传

zhangyuan1985
- 粉丝: 36
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索AVL树算法:以Faculdade Senac Porto Alegre实践为例
- 小学语文教学新工具:创新黑板设计解析
- Minecraft服务器管理新插件ServerForms发布
- MATLAB基因网络模型代码实现及开源分享
- 全方位技术项目源码合集:***报名系统
- Phalcon框架实战案例分析
- MATLAB与Python结合实现短期电力负荷预测的DAT300项目解析
- 市场营销教学专用查询装置设计方案
- 随身WiFi高通210 MS8909设备的Root引导文件破解攻略
- 实现服务器端级联:modella与leveldb适配器的应用
- Oracle Linux安装必备依赖包清单与步骤
- Shyer项目:寻找喜欢的聊天伙伴
- MEAN堆栈入门项目: postings-app
- 在线WPS办公功能全接触及应用示例
- 新型带储订盒订书机设计文档
- VB多媒体教学演示系统源代码及技术项目资源大全
