Spark Standalone HA:ZooKeeper实现Master高可用与重启策略
157 浏览量
更新于2024-08-27
收藏 216KB PDF 举报
在Spark的Standalone部署模式中,Master节点的单点故障(SPOF)是一个常见的问题。为了提高可用性(High Availability, HA),Spark引入了ZooKeeper作为解决方案。ZooKeeper提供了Leader Election机制,确保集群中的Master节点只有一个处于活跃状态(Active),其余为备用(Standby)。一旦活跃Master发生故障,备用Master将通过选举被提升为新的活跃节点,同时保持对Worker、Driver和Application信息的持久化管理。
ZooKeeper的集成使得集群信息存储在分布式文件系统中,这允许在主备Master切换时,仅对新提交的Job产生影响,而不会中断正在执行的任务。Master节点的重启策略分为三种:
1. **ZOOKEEPER实现HA**:在这种模式下,Master在启动时将恢复信息持久化到ZooKeeper中,确保数据的一致性和可用性。当Master重启时,会从ZooKeeper获取恢复状态,并恢复持久化的Worker、Driver和Application信息。
2. **FILESYSTEM**:另一种策略是将数据保存在本地或网络文件系统,提供无数据丢失的重启能力。当Master重启时,它会从指定目录加载恢复数据,继续服务已存在的Job。
3. **丢弃所有数据重启**:这是最保守的策略,Master在重启时会丢弃所有原有的数据,这意味着所有未完成的Job可能会受到影响。
`Master::preStart()`方法是实现这些重启策略的关键部分,根据配置参数(如`RECOVERY_MODE`),系统会选择合适的持久化引擎来处理重启过程。通过这种方式,Spark Master实现了高可用性,提高了整个集群的可靠性和稳定性。理解并掌握这些原理和代码实现,有助于开发者在实际项目中更好地处理Spark集群的故障恢复和HA需求。
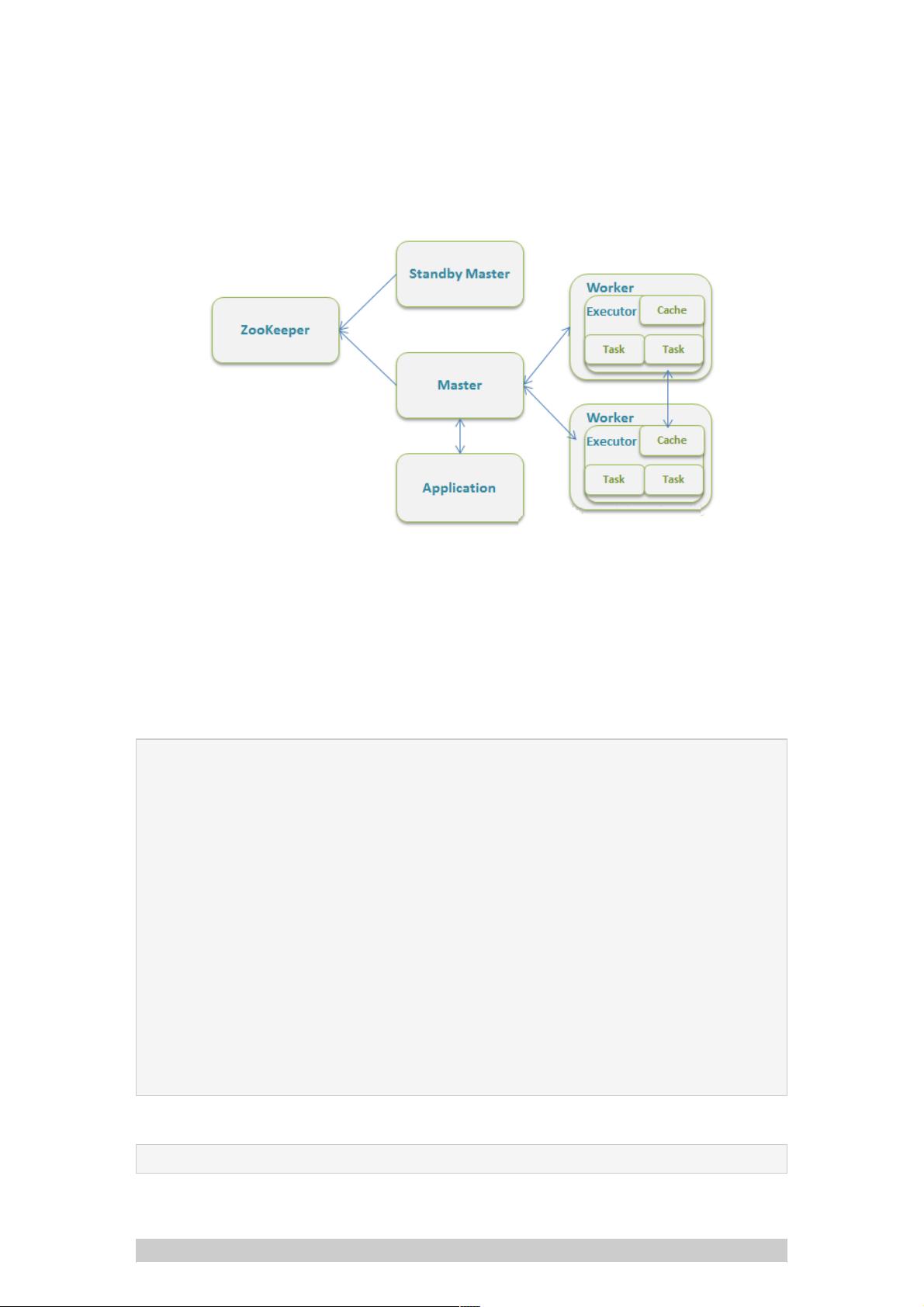
Master基于基于ZooKeeper的的HighAvailability源码实现源码实现
如果Spark的部署方式选择Standalone,一个采用Master/Slaves的典型架构,那么Master是有SPOF(单点故
障,Single Point of Failure)。Spark可以选用ZooKeeper来实现HA。
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master但是只有一个是Active
的,其他的都是Standby,当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信
息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,
对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。
1. Master的重启策略
Master在启动时,会根据启动参数来决定不同的Master故障重启策略:
1.ZOOKEEPER实现HA
2.FILESYSTEM:实现Master无数据丢失重启,集群的运行时数据会保存到本地/网络文件系统上
3.丢弃所有原来的数据重启
Master::preStart()可以看出这三种不同逻辑的实现。
override def preStart() {
logInfo("Starting Spark master at " + masterUrl)
...
//persistenceEngine是持久化Worker,Driver和Application信息的,这样在Master重新启动时不会影响
//已经提交Job的运行
persistenceEngine = RECOVERY_MODE match {
case "ZOOKEEPER" =>
logInfo("Persisting recovery state to ZooKeeper")
new ZooKeeperPersistenceEngine(SerializationExtension(context.system), conf)
case "FILESYSTEM" =>
logInfo("Persisting recovery state to directory: " + RECOVERY_DIR)
new FileSystemPersistenceEngine(RECOVERY_DIR, SerializationExtension(context.system))
case _ =>
new BlackHolePersistenceEngine()
}
//leaderElectionAgent负责Leader的选取。
leaderElectionAgent = RECOVERY_MODE match {
case "ZOOKEEPER" =>
context.actorOf(Props(classOf[ZooKeeperLeaderElectionAgent], self, masterUrl, conf))
case _ => // 仅仅有一个Master的集群,那么当前的Master就是Active的
context.actorOf(Props(classOf[MonarchyLeaderAgent], self))
}
}
RECOVERY_MODE是一个字符串,可以从spark-env.sh中去设置。
val RECOVERY_MODE = conf.get("spark.deploy.recoveryMode", "NONE")
如果不设置spark.deploy.recoveryMode的话,那么集群的所有运行数据在Master重启是都会丢失,这个结论是从
BlackHolePersistenceEngine的实现得出的。
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
325 浏览量
2021-01-31 上传
229 浏览量
1126 浏览量
924 浏览量
2021-04-15 上传

weixin_38665629
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Lotus Domino服务器高级管理:监控、安全与优化
- 面向对象编程:抽象类、多态与接口解析
- Exchange 2007服务器安装教程:图形与命令行部署
- VS2005常用控件详解:进度条与按钮实例
- UI测试用例设计:ATM取款机系统UI测试用例设计指南
- 操作系统原理与应用:期末考试卷A卷解析
- 操作系统原理与应用:期末考试精华总结
- 新手指南:一步步教你编写测试用例实战
- C#入门指南:从基础到面向对象
- 陈启申主讲:制造企业MRP信息化建设关键课程
- 实战EJB:从入门到高级开发与部署
- Linux基础:60个必学命令详解
- 深入探索:嵌入式Linux应用程序开发——第4章解析
- DB2 SQLSTATE详解:错误与异常代码解析
- 《嵌入式Linux应用程序开发详解》第三章:Linux C编程基础
- 嵌入式Linux应用开发:第二章,掌握Shell与系统命令
