分布式因式分解机在Apache Spark上的实现与参数服务器
需积分: 5 170 浏览量
更新于2024-07-17
收藏 2.11MB PDF 举报
"这篇PDF文件是IBM首席工程师Nick Pentreath在2017年SPARK SUMMIT上发表的演讲,主题是《在Apache Spark上使用参数服务器扩展因子分解机》。Nick Pentreath是Apache Spark项目管理委员会成员,同时也是《Spark机器学习》一书的作者。演讲内容涵盖了因子分解机的基础知识,以及如何在Spark和Glint框架下实现分布式FM,还涉及了实验结果、挑战和未来的工作方向。"
因子分解机(Factorization Machines, FM)是一种强大的机器学习模型,它能够处理高维稀疏数据并捕获特征之间的交互作用。传统的线性模型无法充分表达特征间的复杂关系,而FM通过引入因子化交互项解决了这个问题。
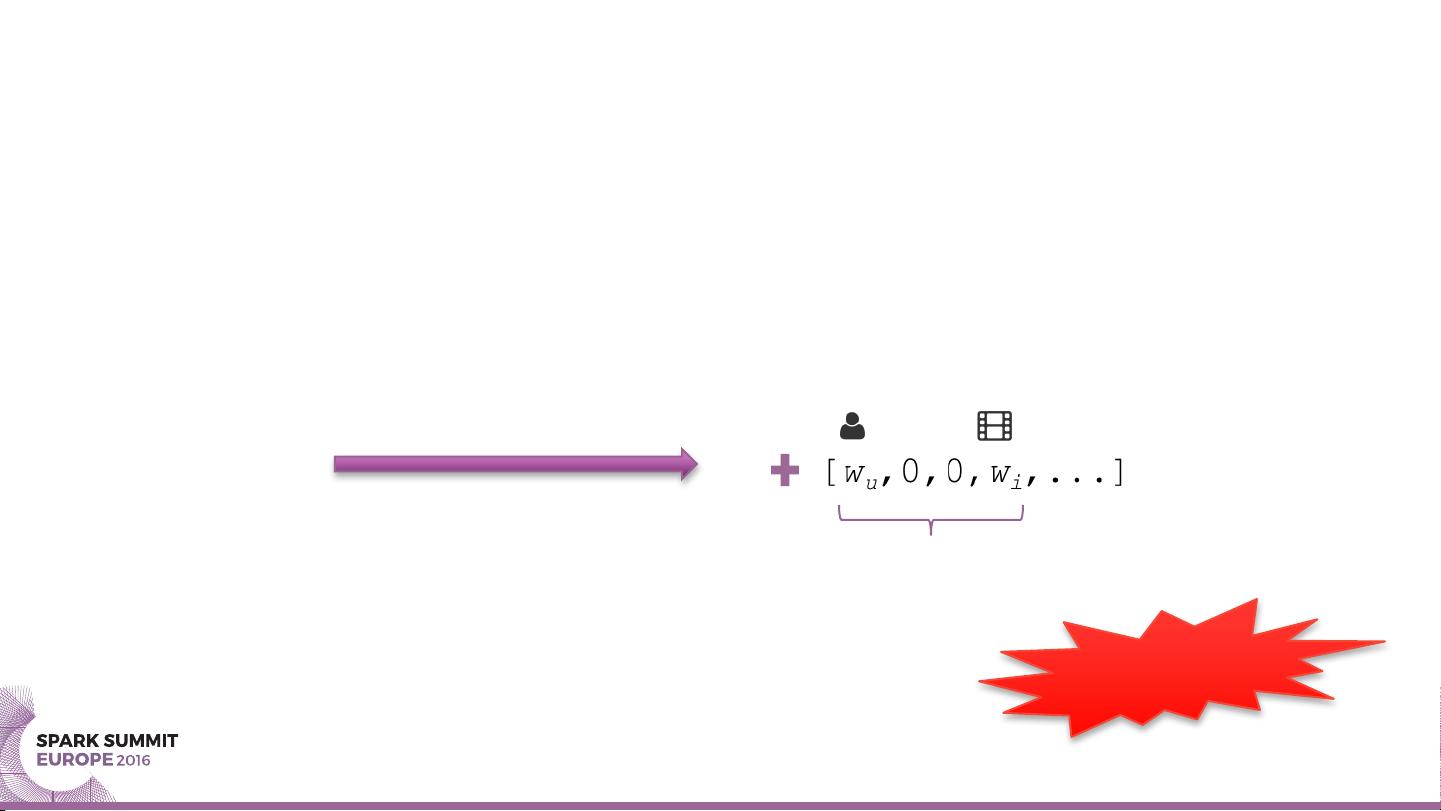
线性模型仅包含特征的加权和,如wijxj,但不能表达特征间的相互作用。相比之下,多项式回归可以捕获二阶交互项,如wijxixj,但这会导致模型复杂度随着特征数量d的平方增长,对于大数据集来说,这可能是不可行的。
FM则在保留线性模型的基础上引入了一个因子化交互项,即wijxixj = vkukxixj,其中v和u是低秩的因子向量,k远小于d。这样,FM的复杂度降为了O(d2k),大大减少了存储和计算的需求。虽然模型的优化问题不再是凸优化,但可以通过随机梯度下降(SGD)、协同下降或马尔可夫链蒙特卡洛(MCMC)等方法进行有效训练。
在Spark和Glint这样的分布式计算框架中实现FM,可以充分利用集群计算能力,处理大规模数据集。Spark提供了高效的分布式内存计算,Glint则可能用于提供实时预测或在线学习的能力。演讲中可能会讨论如何利用参数服务器来进一步提高分布式环境下的训练效率和模型性能。
演讲的结果部分可能展示了在不同数据集上应用分布式FM的性能,包括预测准确度、训练时间等方面的比较。挑战部分可能涵盖了数据分布不均、通信开销、模型并行化等问题。未来工作可能会探讨如何改进FM模型,优化分布式训练策略,或者将FM与其他机器学习技术结合,以提升整体的预测能力和应用范围。
这个演讲对理解如何在大规模环境下利用Spark和参数服务器实现因子分解机有重要价值,对于从事云计算和分布式机器学习领域的专业人士来说,是一个深入学习和实践的宝贵资源。
Factorization Machines
Linear Models
!
"
#
$
!
%
&
%
'
%()
Not expressive
enough!
w
0
Bias terms

剩余30页未读,继续阅读
2024-10-14 上传
2024-10-14 上传
2024-10-15 上传
2024-10-14 上传
2024-10-14 上传
2024-10-14 上传

weixin_38744435
- 粉丝: 373
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
