尚硅谷大数据技术高频面试题解析
版权申诉
"尚硅谷大数据技术之高频面试题8.0.2.pdf" 是一份针对大数据技术面试的综合指南,由尚硅谷大数据研发部编撰,涵盖了Linux、Hadoop、Zookeeper、Flume和Kafka等多个关键领域的核心知识点。
### Linux & Shell
- **Linux常用高级命令**: 包括但不限于文件管理、权限操作、进程控制等,这些是系统管理员和开发人员日常工作中必备的技能。
- **Shell常用工具及脚本**: 提到Shell脚本编写,包括如何编写和执行脚本,以及如何在Shell中管理和控制进程。
- **Shell中kill进程**: 当忘记进程号时,可以通过`ps`命令查找或`pgrep`匹配进程名来找到并杀死进程。
- **单引号和双引号的区别**: 单引号内的变量不会被解析,而双引号内的变量会被解析。
### Hadoop
- **Hadoop常用端口号**: 涉及Namenode、Datanode、ResourceManager等服务的默认端口。
- **Hadoop配置文件与集群搭建**: 深入理解Hadoop的配置文件内容以及集群的部署和初始化。
- **HDFS读写流程**: 分析数据在HDFS中的存取过程,包括NameNode、DataNode的角色。
- **HDFS小文件处理**: 解决大量小文件导致的性能问题,如使用Har、SequenceFile等方法。
- **Shuffle优化**: 提升MapReduce的Shuffle阶段效率,包括减少网络传输、合并Map输出等策略。
- **Yarn工作机制**: 描述Container、ApplicationMaster和ResourceManager的工作原理。
- **Yarn调度器**: 如FIFO、CapacityScheduler、FairScheduler等调度策略及其适用场景。
- **基准测试**: 在项目中进行性能测试,评估和调优Hadoop集群性能。
- **Hadoop宕机处理**及**数据倾斜解决**: 针对Hadoop集群的故障恢复和数据分布不均问题的解决方法。
- **集群资源分配参数**:了解如何根据实际需求调整Hadoop集群的资源配置。
### Zookeeper
- **选举机制**: 介绍Zookeeper的Leader选举过程,如ZAB协议。
- **常用命令**: 如`zkCli.sh`客户端的操作,如创建节点、查看数据等。
- **Paxos算法**:解释一致性算法Paxos在Zookeeper中的应用。
- **CAP法则**:分析Zookeeper如何在一致性、可用性和分区容忍性之间权衡。
### Flume
- **Flume组件**:包含Source、Sink和Channel,以及它们在数据流中的作用。
- **Put事务与Take事务**:理解Flume数据传输的原子性操作。
- **Flume拦截器**:用于数据预处理,如过滤、转换等。
- **Channel选择器**:如何配置和选择数据通道策略。
- **Flume监控器**:监控Flume数据采集的稳定性和性能。
- **防止数据丢失的机制**:探讨Flume如何保证数据传输的可靠性。
### Kafka
- **Kafka架构**:包括生产者、消费者、 broker 和 Topic 的结构。
- **机器数量与副本数设定**:讨论集群规模和副本复制策略对容错性和性能的影响。
- **Kafka压测**:进行性能测试,确定集群的承载能力。
- **日志保存时间**:配置和管理Kafka消息的生命周期。
- **数据量计算**:估算Kafka存储需求,避免硬盘空间不足。
- **Kafka监控**:通过JMX、Prometheus或其他工具监控Kafka的运行状态。
- **分区数**:讨论分区数对并发度和查询性能的影响。
这份面试题集全面覆盖了大数据领域的重要技术和实践,是准备大数据面试或提升自身技术能力的宝贵资源。
尚硅谷大数据技术之高频面试题
—————————————————————————————
15
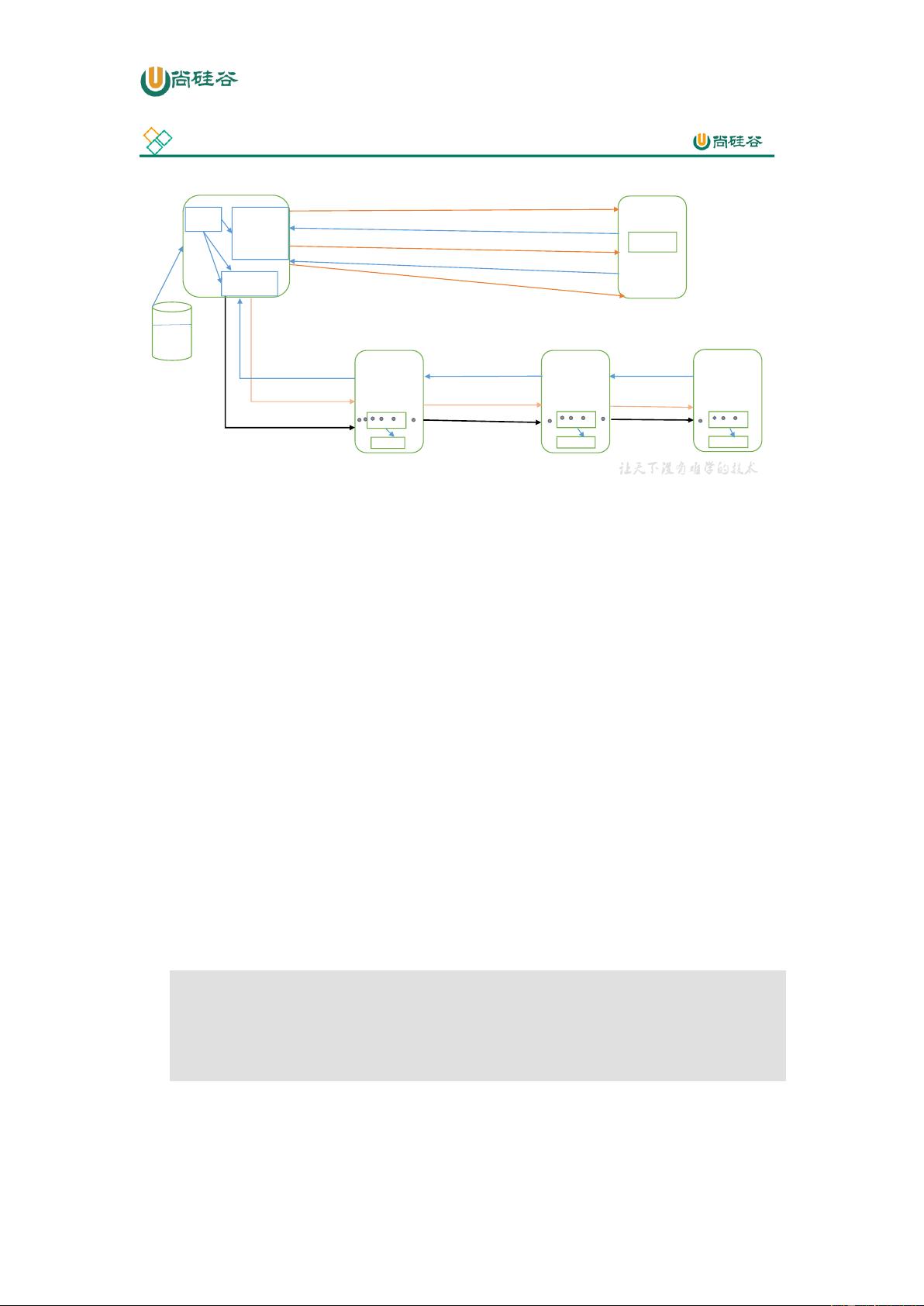
1 向NameNode请求上传文件/user/atguigu/ss.avi
2 响应可以上传文件
3 请求上传第一个Block(0-128M),请返回DataNode
4返回dn1,dn2,dn3节点,表示采用这三个节点存储数据
NameNode
客户端
元数据
DataNode1
DataNode2
DataNode3
ss.avi
0-128m
200m
5 请求建立Block传输通道
Bytebuffer
Bytebuffer Bytebuffer
6 dn1应答成功
6 dn3应答成功
6 dn2应答成功
5 请求建立通道
5 请求建立通道
7 传输数据 Packet
7 blk_1
7 blk_1
7 blk_1
HDFS的写数据流程
8 传输数据完成
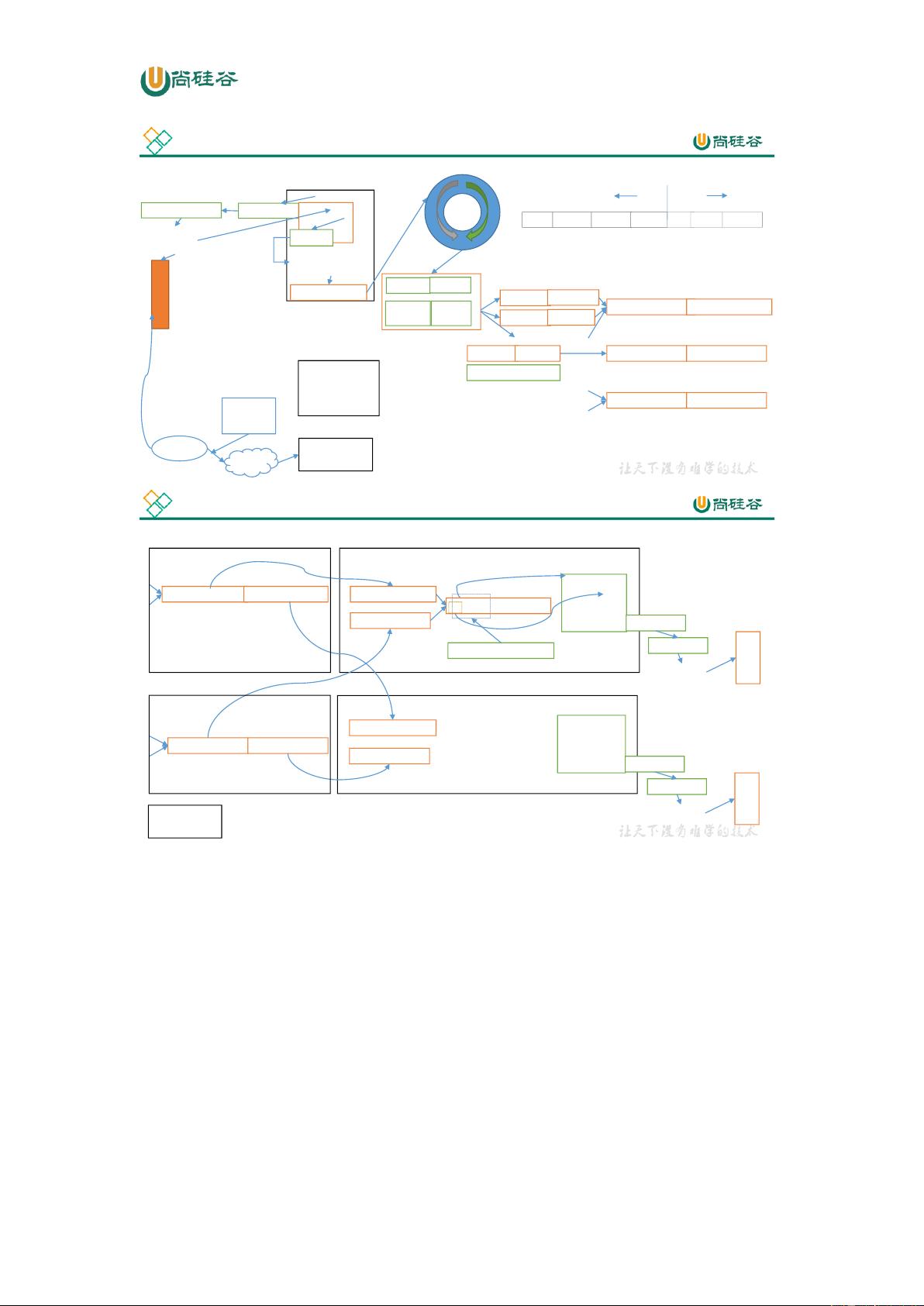
Distributed
FileSystem
FSDataOu
tputStream
HDFS
client
create
write
close
1.2.4 HDFS 小文件处理
1)会有什么影响
(1)1 个文件块,占用 namenode 多大内存 150 字节
1 亿个小文件*150 字节
1 个文件块 * 150 字节
128G 能存储多少文件块? 128 * 1024*1024*1024byte/150 字节 = 9 亿文件块
2)怎么解决
(1)采用 har 归档方式,将小文件归档
(2)采用 CombineTextInputFormat
(3)有小文件场景开启 JVM 重用;如果没有小文件,不要开启 JVM 重用,因为会一
直占用使用到的 task 卡槽,直到任务完成才释放。
JVM 重用可以使得 JVM 实例在同一个 job 中重新使用 N 次,N 的值可以在 Hadoop 的
mapred-site.xml 文件中进行配置。通常在 10-20 之间
<property>
<name>mapreduce.job.jvm.numtasks</name>
<value>10</value>
<description>How many tasks to run per jvm,if set to -
1 ,there is no limit</description>
</property>
1.2.5 Shuffle 及优化
1、Shuffle 过程


剩余214页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-12-25 上传
2023-02-07 上传
2024-05-15 上传
2024-05-13 上传
2021-05-22 上传


智慧化智能化数字化方案
- 粉丝: 1346
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java编程规范(上课的课件,写得很详细)分享下
- Matlab6.0图形图像处理函数
- proteus常用元件中英文对照表
- C#程序设计必看书籍
- 很不错的制作安装程序详解
- 高级SQL查询语言(适合有基础的sql程序员)
- IEEE802.15.4协议安全模式的软硬件协同设计
- Linux的shell好比DOS的COMMAND.COM,
- Oracle9i Database Administration
- CAN总线协议与总线分析.doc
- OracleProc编程
- ubuntu部落-ubuntu使用入门
- 数据结构单链表4个函数
- can_intro.pdf
- linux 虚拟内存
- 飞思卡尔BDM for S12(TTBDM)
