C语言链表深度解析:从基础到Linux内核实现
9 浏览量
更新于2024-09-02
收藏 166KB PDF 举报
"C语言的链表基础知识,包括单链表和双链表的介绍,以及Linux内核链表的特殊性。"
链表是计算机科学中一种重要的数据结构,尤其在C语言中,它是实现复杂数据操作的基础。链表与数组不同,它不连续存储数据,而是通过节点间的指针链接来维护数据的逻辑顺序。这种非顺序的存储方式使得链表在插入和删除操作上相比数组具有更高的灵活性。
单链表是链表的一种基本形式,每个节点包含两部分:数据域用于存储实际的数据,指针域则保存下一个节点的地址。节点间的连接形成一个线性的序列,通常从头节点开始,通过每个节点的指针域指向下一个节点。如果最后一个节点的指针域指向头节点,那么这个链表就形成了一个循环链表。
双链表是单链表的扩展,它在每个节点中增加了另一个指针域,用于存储直接前驱节点的地址。这样一来,双向链表可以方便地向前和向后遍历,不仅能够快速访问当前节点的后续节点,也能迅速找到前一个节点,这对于需要频繁进行前向和后向操作的场景非常有用。在双向链表中,节点的结构通常包含数据域、指向前一个节点的指针(prev)和指向后一个节点的指针(next)。
Linux内核中的链表实现有其特殊之处,它通常更为高效且适应内核环境的需求。例如,内核链表可能包含了额外的锁机制来保证多线程环境下的安全性,或者采用自旋锁来避免在等待锁时发生上下文切换。此外,内核链表可能还包含了一些优化,如头节点的合并或特定的API设计,以提高操作的效率。
在理解和使用链表时,开发者需要注意内存管理和指针操作的正确性,防止悬空指针和内存泄漏。同时,链表操作通常比数组慢,因为它们涉及到指针的查找和更新,但在处理动态变化的数据集时,链表的灵活性往往弥补了这一性能上的差距。
通过深入理解和熟练运用链表,开发者可以解决许多复杂的数据组织问题,特别是在需要动态调整数据结构的场合。无论是单链表还是双链表,它们都是C语言编程中不可或缺的数据结构工具,对于学习和掌握C语言以及更高级别的系统级编程至关重要。
C语言的那些小秘密之链表(一)语言的那些小秘密之链表(一)
链表,一个对于学习过C语言的人都是再熟悉不过的概念了,可能很多学习过链表的人都觉得链表没什么值得太
在意的地方,可是如果你走进linux内核,去看看linux内核里面链表的实现方式,你不得不为之惊叹。本文就主
要讲述链表的使用。
链表,一个对于学习过C语言的人都是再熟悉不过的概念了,可能很多学习过链表的人都觉得链表没什么值得太在意的地方,
可是如果你走进linux内核,去看看linux内核里面链表的实现方式,你不得不为之惊叹。可能有人会觉得linux内核链表实现方
式仅此而已,但是你要知道,如果你没有见到这样的实现方式之前,能写出那样的链表嘛?所以在写链表的文章时,我深知自
己不可能用一篇文章来讲解完链表的知识点,所以我特地分为三个部分(单链表、双链表、linux内核链表,而其中linux内核链
表单独拿出来讲是因为它的特殊性,在后面的博客中我们再来细谈它)来进行讲解,尽可能用简短的文字描述加上简单易懂的
代码来向读者讲解我所理解的链表,希望我所讲的链表能都对你有所帮助。接下来言归正传,开始我们的链表之旅。
那么什么是链表呢?链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次
序实现的。链表由一系列结点组成,即链表中的每个元素,结点可以在运行时动态生成。每个结点均由两个部分所组成:一个
是存储数据元素的数据域,另一个是存储相邻结点地址的指针域。相比于线性表顺序结构,链表比较方便插入和删除操作。
对于链表我们可以将其分为单链表、双向链表和循环链表等。首先我们先讲讲单链表。
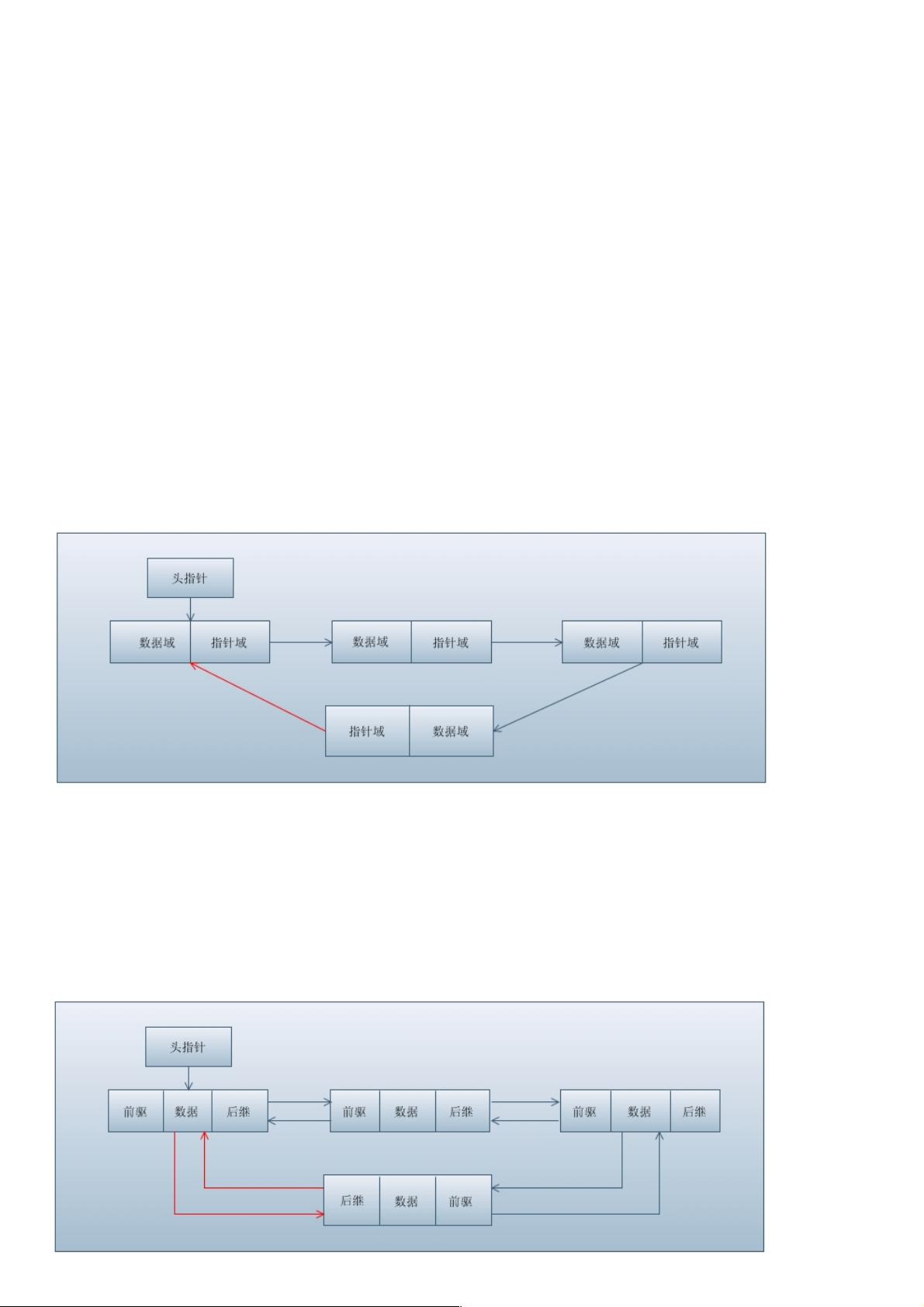
所谓单链表,是指数据结点是单向排列的。一个单链表结点,其结构类型分为两部分:
1、数据域:用来存储本身数据
2、指针域:用来存储下一个结点地址或者说指向其直接后继的指针。
如下图所示:
注意:如果有图中的红色箭头部分,则变为了单向循环链表。
那什么又是双链表呢?双向链表其实是单链表的改进。当我们对单链表进行操作时,有时你要对某个结点的直接前驱进行操作
时,又必须从表头开始查找。这是由单链表结点的结构所限制的。因为单链表每个结点只有一个存储直接后继结点地址的链
域,那么能不能定义一个既有存储直接后继结点地址的链域,又有存储直接前驱结点地址的链域的这样一个双链域结点结构
呢?这就是双向链表。
在双向链表中,结点除含有数据域外,还有两个链域,一个存储直接后继结点地址,一般称之为右链域;一个存储直接前驱结
点地址,一般称之为左链域。
如下图所示:
下载后可阅读完整内容,剩余9页未读,立即下载
2020-08-10 上传
2020-08-10 上传
点击了解资源详情
2011-08-22 上传
2009-11-08 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38690545
- 粉丝: 4
- 资源: 927
 我的内容管理
展开
我的内容管理
展开







最新资源
- FiniteDifferencePricing:Crank Nicolson方案的C ++应用程序通过Green函数对付红利的美国期权定价
- es6-jest-ramda-样板
- WindowsTerminalHere:右击.inf文件的Windows终端的资源管理器“此处的Windows终端”,直到直接支持它为止
- IAAC_Cloud-Based-Management_FR:该存储库是IAAC(MaCAD计划)的基于云的管理研讨会的最终提交内容的一部分
- 实现界面放大镜功能ios源码下载
- 电子功用-基于应用统计方法和嵌入式计算的智能电子闹钟设定方法
- 汉堡建筑商
- infogram-java-samples
- ct-ng-toolchains:适用于Altera SoCFPGA和NXP LPC32xx目标的裸机ARM工具链
- StudyMegaParsec:研究megaparsec的用法
- vercelly-app:React Native应用程序,用于管理Vercel项目和部署
- 一个很漂亮的VC++登录窗体界面
- hackontrol-frontend:一个React JS前端应用程序Hackontrol
- 基于micropython的ESP32血压、血氧、心率、体温的传感系统(python)
- crispy-couscous
- Echarts商业级数据图表库模块v1.6.0.241.rar
