定制异步并行批处理框架解决海量数据挑战
12 浏览量
更新于2024-07-15
收藏 836KB PDF 举报
本文主要探讨了在海量数据时代下,如何设计异步并行批处理框架以应对数据处理挑战。作者提到了当前可用的几种解决方案,包括Hadoop的MapReduce框架,适用于离线数据挖掘;Storm分布式计算框架,用于实时流式数据处理;以及面向批处理的企业级框架SpringBatch。文章指出,尽管有这些现成的框架,但可能需要根据特定企业的数据处理需求定制自己的框架。
在描述的场景中,作者服务于一家移动公司,面对数千万级别的用户数据,这些数据存储在Oracle数据库中,并按照地市进行分区。计费结算系统根据用户余额触发停复机操作,由业务处理系统执行。然而,现有的C++多进程后台处理程序在数据量激增时(如月初)处理效率低下,导致延迟和用户投诉,从而影响客户满意度和运营商的客户保留。
作者识别出几个关键问题:
1. 所有用户数据集中在一个数据库表中,顶级小型机配置可能也无法应对月初的数据处理高峰。
2. C++后台程序的处理能力不足,无法实时响应大量请求。
3. 数据库查询性能可能成为瓶颈,尤其是在处理大范围用户数据时。
4. 系统扩展性有限,无法快速适应数据量的变化。
在设计异步并行批处理框架时,需要考虑以下几个关键点:
1. **分布式处理**:借鉴MapReduce的思想,将大任务拆分为小任务,分散到多个节点上并行处理,以提高处理速度。
2. **异步处理**:通过消息队列或事件驱动架构,将数据处理任务放入队列,由后台工作线程异步执行,避免阻塞主线程。
3. **负载均衡**:动态调整任务分配,确保负载均衡,防止某个节点过载。
4. **数据分区与分片**:类似数据库分区,将数据合理分割,减少单个查询的复杂性和处理时间。
5. **缓存优化**:利用缓存机制,如Redis,快速处理常见查询,减少对数据库的依赖。
6. **监控与报警**:建立完善的监控系统,实时监控处理速度、错误率等指标,及时发现并解决问题。
7. **弹性伸缩**:通过云服务或容器化技术,实现计算资源的动态扩展,应对流量高峰。
8. **容错机制**:设计健壮的错误处理和重试机制,确保任务的最终一致性。
通过以上策略,可以构建一个更适应大数据量、高并发场景的异步并行批处理框架,提高数据处理的实时性和可靠性,减少用户投诉,提升客户满意度,帮助企业应对市场的激烈竞争。同时,这样的框架也能为企业节省硬件成本,提高资源利用率。
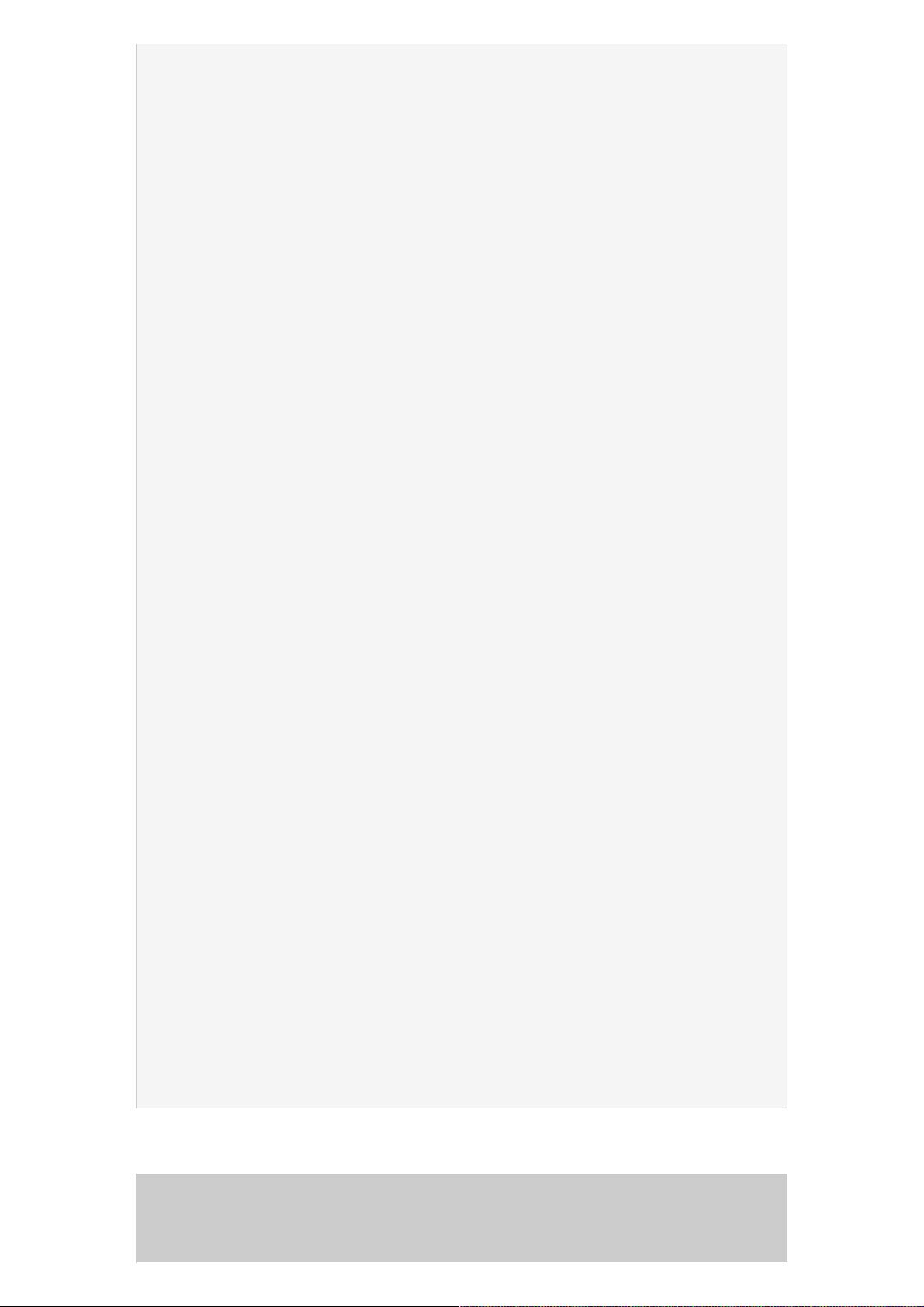
private int corePoolSize;
private int maxPoolSize;
private int keepAliveTime;
private int workQueueSize;
public void setName(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
public int getCorePoolSize() {
return corePoolSize;
}
public void setCorePoolSize(int corePoolSize) {
this.corePoolSize = corePoolSize;
}
public int getMaxPoolSize() {
return maxPoolSize;
}
public void setMaxPoolSize(int maxPoolSize) {
this.maxPoolSize = maxPoolSize;
}
public int getKeepAliveTime() {
return keepAliveTime;
}
public void setKeepAliveTime(int keepAliveTime) {
this.keepAliveTime = keepAliveTime;
}
public int getWorkQueueSize() {
return workQueueSize;
}
public void setWorkQueueSize(int workQueueSize) {
this.workQueueSize = workQueueSize;
}
public int hashCode() {
return new HashCodeBuilder(1, 31).append(name).toHashCode();
}
public String toString() {
return new ToStringBuilder(this, ToStringStyle.SHORT_PREFIX_STYLE)
.append("name", name).append("corePoolSize", corePoolSize)
.append("maxPoolSize", maxPoolSize)
.append("keepAliveTime", keepAliveTime)
.append("workQueueSize", workQueueSize).toString();
}
public boolean equals(Object o) {
boolean res = false;
if (o != null
&& BatchTaskConfiguration.class.isAssignableFrom(o.getClass())) {
BatchTaskConfiguration s = (BatchTaskConfiguration) o;
res = new EqualsBuilder().append(name, s.getName()).isEquals();
}
return res;
}
}
当然了,你进行参数配置的时候,还可以指定多个线程池,于是要设计一个:批处理线程池工厂类
BatchTaskThreadFactoryConfiguration,来依次循环保存若干个线程池的参数配置

剩余48页未读,继续阅读
2021-05-29 上传
2024-03-13 上传
165 浏览量
2021-02-13 上传
103 浏览量
点击了解资源详情
110 浏览量
107 浏览量
点击了解资源详情

weixin_38728360
- 粉丝: 4
- 资源: 926
 我的内容管理
展开
我的内容管理
展开







最新资源
- 英语常用3500词音频+PDF文件(含音频).zip
- 老板计时器
- Honey Boo Boo的算法和功能分解
- ember-addon-config
- 1.8wUA库.zip
- reading-notes:在这里您可以找到我的阅读资料库,主要用于总结我在编程方面的学习历程,希望您能找到一些有用的信息<3
- 视频播放可弹出弹幕,关闭弹幕
- simple-spawner:生成一个命令并将输出通过管道返回到 std{in,out,err}
- CSS_Assignment_2
- 使用注释将JDBC结果集映射到对象
- curious-blindas-api:CuriousCat克隆
- PRO-C21-BULLETS-AND-WALLS
- ff35mm:Flickr 的全画幅 (35mm) 焦距
- C#解析HL7消息的库
- 将Java System.out定向到文件和控制台的快速简便方法
- 库索逻辑-葡萄牙语
