深入解析Raft共识协议:领导选举与日志复制
需积分: 10 180 浏览量
更新于2024-07-15
收藏 400KB PDF 举报
"Raft协议是一种共识算法,用于在分布式系统中复制日志,从而实现状态机的复制。它由Diego Ongaro和John Ousterhout在斯坦福大学提出,旨在解决分布式环境中的一致性问题。Raft算法的核心机制包括领导者选举、日志复制和安全性保证,能够确保系统在多数服务器正常运行的情况下保持进步,同时假设故障模型为非拜占庭式,即仅考虑服务器停止故障和消息延迟或丢失的情况。"
在深入分析Raft协议之前,我们首先需要理解共识算法在分布式系统中的重要性。共识算法是确保多个节点在处理同一任务时达成一致性的基础,尤其是在分布式数据库和分布式计算中。Raft通过引入领导者的概念,将共识问题分解为两个部分:正常操作和领导者变更,这使得协议更易于理解和实现。
**领导者选举**
在Raft中,系统中的节点分为领导者、跟随者和候选人三种角色。领导者负责接收客户端的请求,复制日志到其他节点,并协调整个集群的操作。当领导者失效或者超过一定时间没有收到领导者的心跳信息,跟随者和候选人会进行选举,最终选出新的领导者。这个过程保证了系统的高可用性和一致性。
**日志复制**
日志复制是Raft的核心机制之一,所有服务器按照相同的顺序执行相同命令,确保状态机的一致性。领导者接收客户端的命令,将其添加到自己的日志中,然后向其他节点发送这些条目,直到大多数节点确认接收,这个过程被称为日志复制。一旦日志条目被多数节点复制,该条目就被认为是确定的,可以被提交到状态机执行。
**安全性保证**
Raft通过一系列规则来保证日志的安全性。例如,领导者只会向其日志后面追加新的条目,不会覆盖已有的条目,这避免了日志冲突。此外,只有拥有最新确定日志条目的节点才能成为领导者,确保了领导者总是持有最新的状态信息。
**容错与恢复**
在故障模型中,Raft假设服务器可能停止工作,但不考虑恶意行为(即拜占庭故障)。即使有服务器出现故障,只要集群中过半数的节点正常运行,系统仍然可以继续工作。当故障服务器恢复时,它们会通过与当前领导者同步日志来重新加入集群。
**客户端交互**
在Raft中,客户端只与当前的领导者通信,这简化了系统设计,避免了多节点间的复杂同步问题。如果领导者失效,客户端会自动重试并找到新的领导者,保证服务的连续性。
Raft协议通过引入领导者角色,实现了简单且高效的共识机制,适用于多种分布式系统,如etcd这样的键值存储系统。它的设计目标是易理解和实现,同时保证了系统的可用性和一致性。
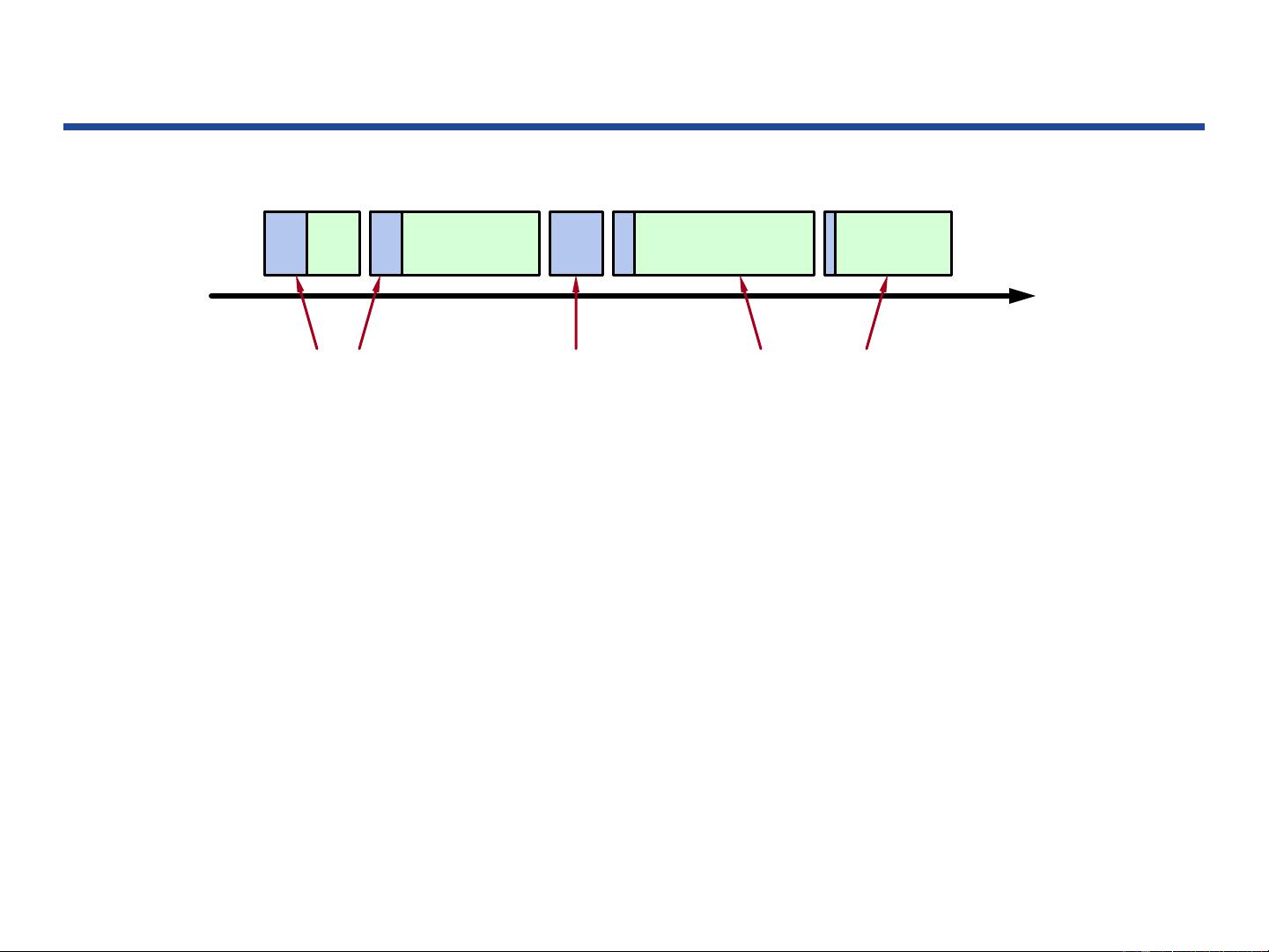
● Time divided into terms:
Election
Normal operation under a single leader
● At most 1 leader per term
● Some terms have no leader (failed election)
● Each server maintains current term value
● Key role of terms: identify obsolete information
March 3, 2013 Raft Consensus Algorithm Slide 6
Terms
Term 1 Term 2 Term 3 Term 4 Term 5
time
Elections Normal Operation Split Vote

剩余30页未读,继续阅读
2020-07-04 上传
2016-09-01 上传
2023-05-19 上传
2023-05-23 上传
2023-03-20 上传
2023-05-31 上传
2023-05-17 上传
2023-05-19 上传
2023-03-06 上传
2023-05-31 上传

yangfeiblog
- 粉丝: 155
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
