掌握Hive内置函数:SQL查询增强神器
需积分: 5 165 浏览量
更新于2024-06-28
2
收藏 1.96MB PDF 举报
在大数据学习的道路上,Hive函数是不可或缺的一部分。Hive作为一个开源的数据仓库工具,其强大的功能使得数据处理更加高效。本资源《Hive数据仓库》的主要目标是帮助读者深入理解并掌握Hive内置函数的使用,以便在HiveQL(Hive查询语言)中进行高效的数据操作。
首先,章节涵盖了六个关键部分,包括Hive内置函数的全面应用。在"01 Hive内置函数"中,学习者将被引导学习如何灵活运用各种函数:
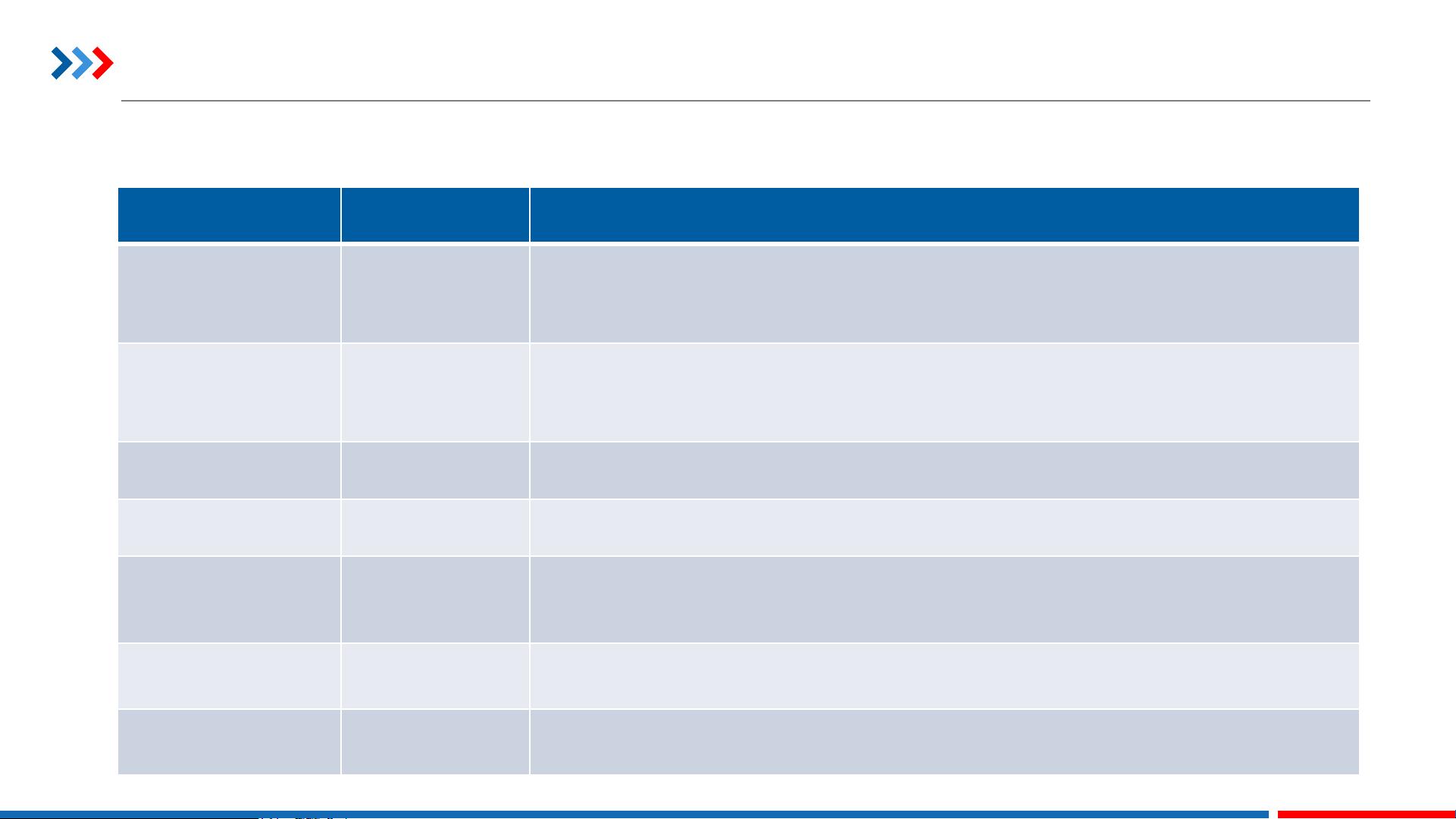
1. 聚合函数 - 聚合函数是Hive的核心组成部分,它们用于汇总数据。例如:
- COUNT():返回指定列或所有行的非空值数量,以及DISTINCT列的唯一值数量。
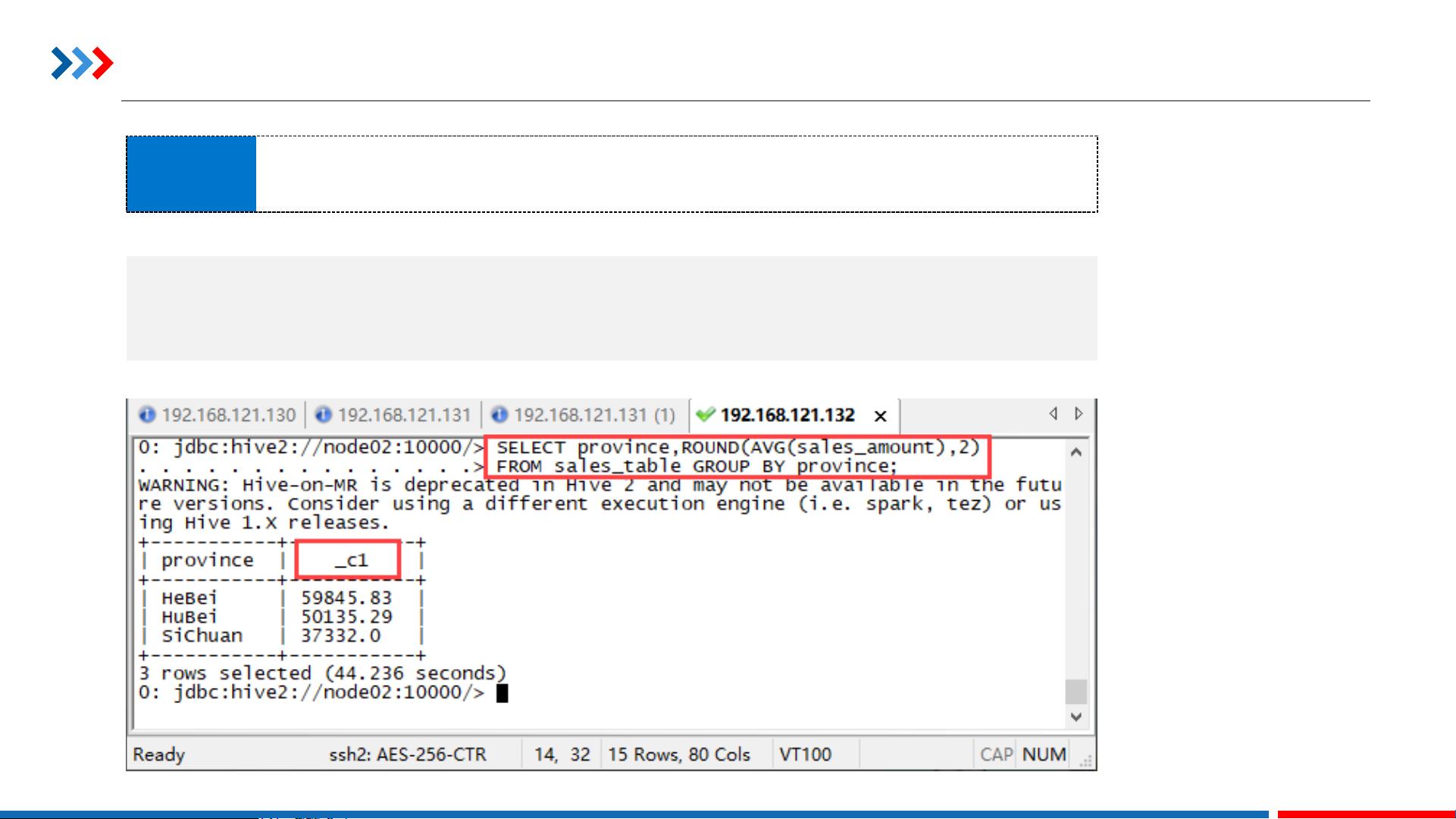
- SUM():计算指定列的总和,区分或不区分重复值。
- AVG():计算指定列的平均值,同样可以处理DISTINCT值。
- COLLECT_SET():将数据转化为数组,去除重复项,返回不重复的集合。
- MAX():找出指定列的最大值。
2. 数学函数:这些函数包括基本的算术运算,如加减乘除等,但具体未在提供的部分内容中列出。
3. 集合函数:虽然没有详细说明,但可能涉及操作集合的函数,比如交集、并集等。
4. 类型转换函数:用于在不同数据类型之间转换,这对于数据清洗和预处理至关重要。
5. 日期函数:处理日期和时间数据,可能包括日期范围计算、格式转换等。
6. 条件函数:这部分可能涉及到CASE WHEN等逻辑表达式,用于根据特定条件执行不同的操作。
7. 字符串函数:包括文本处理函数,如字符串连接、截取、替换等,用于处理文本数据。
8. 表生成函数:允许创建新表或视图,通过现有数据动态生成结构。
此外,章节还介绍了Hive自定义函数,即用户定义函数(UDF)、用户定义表生成函数(UDTF)和用户定义聚合函数(UDAF)。这些函数允许用户根据特定需求编写定制的处理逻辑,增强了Hive的灵活性和扩展性。
学习这个章节的目标是使读者能够熟练地在Hive环境中利用内置和自定义函数来处理大规模数据,提高数据分析和管理的能力。通过实践和理解这些函数,读者可以在HiveQL中构建复杂的查询,优化数据处理过程,提升工作效率。


2020-08-25 上传
2022-12-07 上传
2020-02-20 上传
2021-08-18 上传
2022-11-19 上传
2022-06-20 上传
2022-12-24 上传

梁辰兴
- 粉丝: 10w+
- 资源: 37
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
