MapReduce编程模型与大数据处理
版权申诉
194 浏览量
更新于2024-07-10
收藏 1.05MB DOCX 举报
“大数据处理技术的讲解,主要聚焦于MapReduce编程模型,由科信办刘伟分享。内容涵盖了MapReduce的背景、概念以及其在大数据处理中的重要性。”
MapReduce是大数据处理领域的一种核心编程模型,由谷歌在2004年提出,对学术界和工业界产生了深远影响。这一模型的出现,主要是为了解决大规模数据处理时面临的复杂性问题,比如分布式计算、容错处理、数据分发和负载均衡等。在传统的并行计算中,这些都需要程序员具备深厚的分布式系统知识。而MapReduce则提供了一个抽象的层次,让普通程序员可以专注于业务逻辑,而不用过多关注底层实现的细节。
MapReduce模型的核心由两部分组成:Map和Reduce。Map阶段是数据的分解,它将原始输入数据分割成多个小数据块,并对每个数据块独立应用一个函数,生成中间键值对。这一过程实现了任务的并行化,使得计算可以在多台机器上同时进行。Reduce阶段则是结果的汇总,它接收Map阶段产生的中间结果,根据相同的键进行聚合,最终得到所需的输出结果。这一过程实现了数据的整合,确保了计算的正确性。
Hadoop是MapReduce模型的开源实现,它提供了一个可靠的分布式文件系统(HDFS)和MapReduce计算框架,成为了大数据处理的事实标准。围绕Hadoop,已经发展出一个庞大的生态系统,包括HBase、Spark、YARN等工具,它们共同构成了处理大数据的基础设施。
MapReduce的成功在于其简单易用的编程模型。开发者只需要定义Map函数和Reduce函数,系统会自动处理数据的分布、任务调度、容错以及负载均衡等问题。这种抽象使得非专业分布式计算的程序员也能处理大规模数据,极大地推动了大数据分析的普及。
然而,尽管MapReduce在处理批处理任务上表现出色,但其在实时处理和迭代计算方面存在局限。因此,后续出现了像Spark这样的系统,它在保持并行计算能力的同时,优化了内存计算,提高了处理速度,进一步扩展了大数据处理的技术边界。MapReduce作为大数据处理的基础,对现代数据科学的发展起到了关键作用。
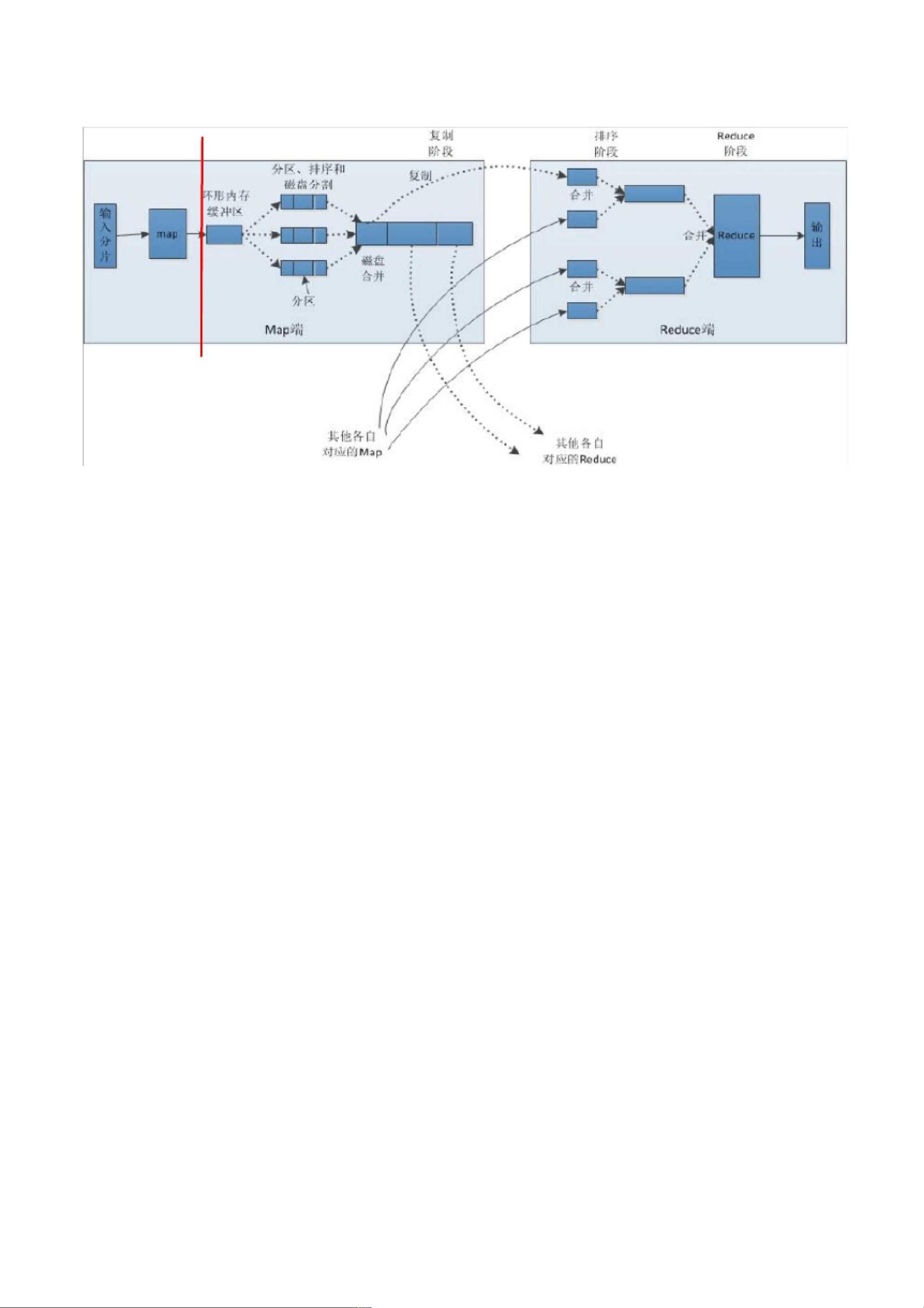
5 / 24
红线中间部分是 shuffle 部分,计算机自动完成,但是我们必须理解 shuffle 做了什么, 我们才能
正确的理解 map 的结果和 reduce 的输入之间的关系。
Map 阶段:数据经过分片化成 M 个数据集,每个数据集由一个 maper 节点经过 map 函数
处理成 key-value 对形式的数据集。
Shuffle 阶段:map 输出的结果放在 maper 节点本地内存缓存区,缓存区先按照 key 进
行分区(如果有 R 个 reducer , hash (key ) mod R 分成 R 个分区,初步划分, 的,
分区内对 key 排序(排序后可附加 combiner 合并操作,减少写磁盘数据量) 要溢出时,
溢写文件,多个溢写文件合并,合并过程再次排序(排序后可附加 并操作),最后形
成一个已经分区的、已经排序(对 key 的排序)的文件。
Reduce 端会把属于本区的数据取(fetch )到内存,进行合并,合并过程再次排序,缓 冲区快
要溢出时,溢写文件,多个溢写文件合并, 合并过程再次排序, 合并为更大的排序文
件,最终实现 reduce 输入数据是经过排序(对 key 的排序)的数据。
其实不管在 map 端还是 reduce 端,MapReduce 都是反复地执行排序,合并操作,所以 说:排
序是 mapreduce 的灵魂。
Reduce 阶段:最后一次合并的数据总是直接送到 Reduce 函数那里,Reduce 函数
会作用在排序输入的每一个 key-list (value )上,最后的输出 key-value 对被直接写到
HDFS 上(分布式文件系统)。 有 R 个 reduce 任务,就会有 R 个最终结果,很多情况下
任务的输入,开始另一个并行计算任务。这就形成了上面图中多个输出数据片段( 本)
。
5.mapreduce 的局限
分区是排序 ,
缓冲区快
combiner 合
这 R 个最终结果并不需要合并成一个最终结果,因为这
R 个最终结果可以作为另一个计算
HDFS 副

剩余25页未读,继续阅读
186 浏览量
304 浏览量
2023-08-07 上传

songyunc
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多技术领域源码集锦:园林绿化官网企业项目
- 定制特色井字游戏Tic Tac Toe开源发布
- TechNowHorse:Python 3编写的跨平台RAT生成器
- VB.NET实现程序自动更新的模块设计与应用
- ImportREC:强大输入表修复工具的介绍
- 高效处理文件名后缀:脚本批量添加与移除教程
- 乐phone 3GW100体验版ROM深度解析与优化
- Rust打造的cursive_table_view终端UI组件
- 安装Oracle必备组件libaio-devel-0.3.105-2下载
- 探索认知语言连接AI的开源实践
- 微软SAPI5.4实现的TTSApp语音合成软件教程
- 双侧布局日历与时间显示技术解析
- Vue与Echarts结合实现H5数据可视化
- KataSuperHeroesKotlin:提升Android开发者的Kotlin UI测试技能
- 正方安卓成绩查询系统:轻松获取课程与成绩
- 微信小程序在保险行业的应用设计与开发资源包
