Spark框架详解:理念、生态与应用潜力
需积分: 9 83 浏览量
更新于2024-07-18
收藏 34.27MB PDF 举报
Spark框架核心技术是大数据处理领域的重要一环,由加州大学伯克利分校AMP实验室开发的通用内存并行计算框架。这篇博客集合主要分为两大部分:Spark简介及其生态圈。
1. **Spark简介**:
- Spark最初由AMP实验室于2013年6月引入Apache,并在短短八个月内晋升为顶级项目,显示出其强大的技术潜力和社区接纳度。
- 该框架的设计理念先进,旨在成为大数据处理的高效解决方案,通过一系列组件如SparkSQL、SparkStreaming、MLLib和GraphX等,构建了BDAS(伯克利数据分析栈),将大数据处理推向一站式服务。
- Spark使用Scala语言编写,Scala是一种支持面向对象和函数式编程的现代化语言,其核心特性包括Actor模型,这种模型基于SharedNothing架构,使得数据操作更为高效且避免了共享数据带来的问题。
2. **Spark与HADOOP的差异**:
- Spark强调内存计算,相比于Hadoop的磁盘I/O密集型处理,它在实时分析和迭代计算方面具有优势,提高了处理速度。
- Spark的设计更注重易用性和通用性,提供了更快的开发和迭代周期,适合处理大规模数据的快速迭代分析。
3. **生态系统的组成部分**:
- **SparkCore**:是Spark的基础模块,负责任务调度和数据存储管理。
- **SparkStreaming**:专注于实时流处理,支持持续的数据流计算。
- **SparkSQL**:提供了SQL查询接口,便于对结构化数据进行分析。
- **BlinkDB**:一种用于交互式查询的列式数据库,与Spark集成,提高查询性能。
- **MLBASE/MLLIB**:Spark的机器学习库,包含大量的机器学习算法和工具。
- **GRAPHX**:专为图计算设计,支持图数据的分析和处理。
- **SparkR**:提供了R语言接口,便于R用户与Spark集成。
- **Tachyon**:一个内存计算系统,支持快速数据交换,增强Spark的性能。
4. **应用与目标**:
- Spark期望挑战Hadoop的地位,成为大数据处理的主流标准,但目前还在发展阶段,尚未经历大规模商业项目的充分验证。
Spark框架的核心技术包括其设计理念、语言特性、与Hadoop的区别、以及丰富的生态系统组件,这些都为其在大数据处理领域的广泛应用打下了坚实基础。通过博客集合,读者可以深入了解Spark的工作原理、使用方法以及其在大数据处理领域的前景。
第 16 页 共 18 页 出自石山园,博客地址:http://www.cnblogs.com/shishanyuan
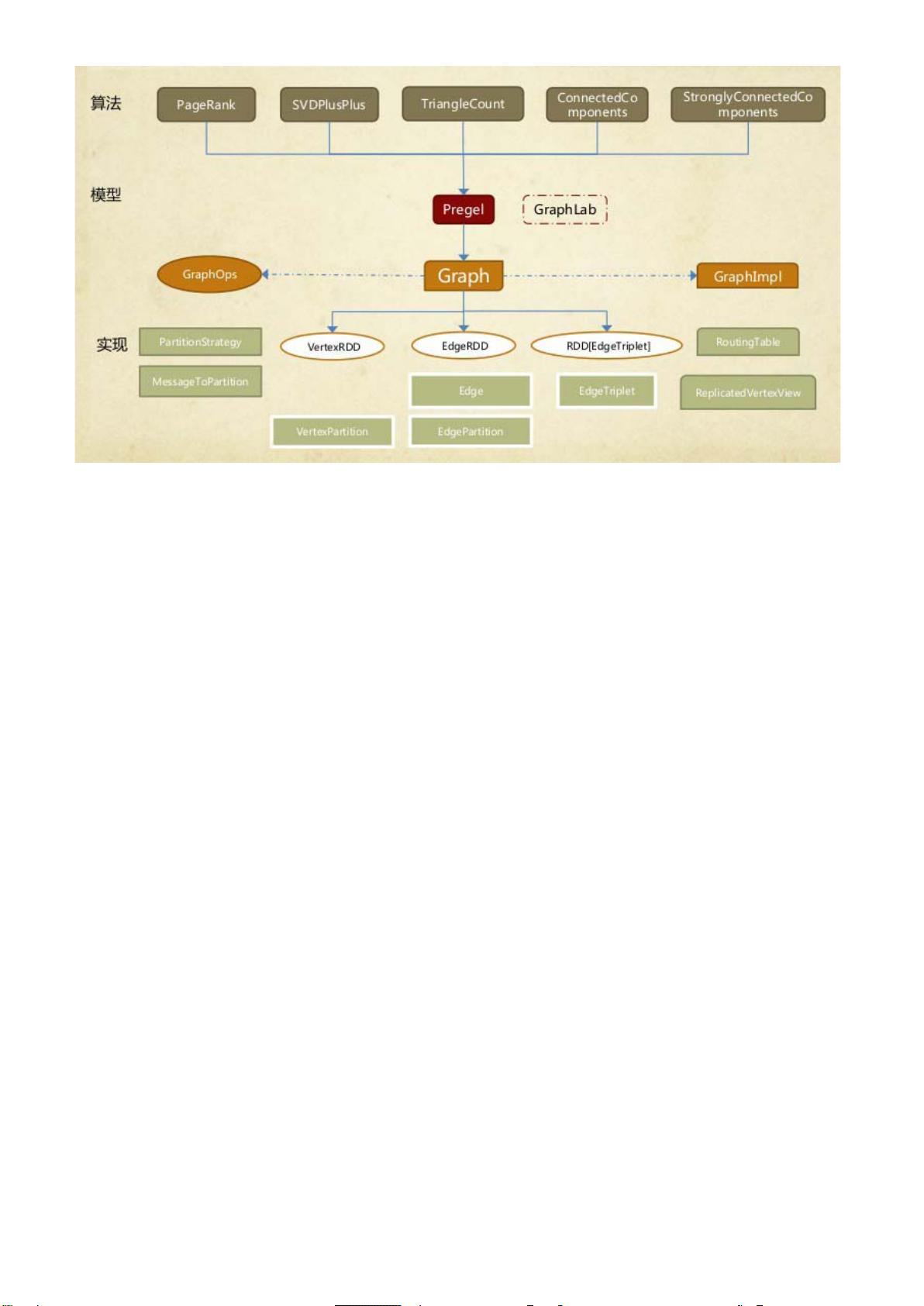
GraphX 的底层设计有以下几个关键点。
1. 对 Graph 视图的所有操作,最终都会转换成其关联的 Table 视图的 RDD 操作来完成。这样
对一个图的计算,最终在逻辑上,等价于一系列 RDD 的转换过程。因此,Graph 最终具备
了 RDD 的 3 个关键特性:Immutable、Distributed 和 Fault-Tolerant。其中最关键的是
Immutable(不变性)。逻辑上,所有图的转换和操作都产生了一个新图;物理上,GraphX
会有一定程度的不变顶点和边的复用优化,对用户透明。
2. 两种视图底层共用的物理数据,由 RDD[Vertex-Partition]和 RDD[EdgePartition]这两个
RDD 组成。点和边实际都不是以表 Collection[tuple] 的形式存储的,而是由
VertexPartition/EdgePartition 在内部存储一个带索引结构的分片数据块,以加速不同视
图下的遍历速度。不变的索引结构在 RDD 转换过程中是共用的,降低了计算和存储开销。
3. 图的分布式存储采用点分割模式,而且使用 partitionBy 方法,由用户指定不同的划分策略
(PartitionStrategy)。划分策略会将边分配到各个 EdgePartition,顶点 Master 分配到各
个 VertexPartition,EdgePartition 也会缓存本地边关联点的 Ghost 副本。划分策略的不
同会影响到所需要缓存的 Ghost 副本数量,以及每个 EdgePartition 分配的边的均衡程度,
需要根据图的结构特征选取最佳策略。目前有 EdgePartition2d、EdgePartition1d、
RandomVertexCut 和 CanonicalRandomVertexCut 这四种策略。在淘宝大部分场景下,
EdgePartition2d 效果最好。
2.7 SparkR
SparkR 是 AMPLab 发布的一个 R 开发包,使得 R 摆脱单机运行的命运,可以作为 Spark
的 job 运行在集群上,极大得扩展了 R 的数据处理能力。



剩余456页未读,继续阅读
2019-07-23 上传
2024-04-02 上传
2024-01-20 上传
2023-12-26 上传
2023-06-06 上传
2023-04-06 上传
2023-03-16 上传
2023-06-07 上传
2023-08-11 上传

third_zhang
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
