深度学习教程:稀疏自编码器与神经网络
"这篇教程是关于深度学习的,特别是集中在稀疏自编码器(Sparse Autoencoder)的学习上。教程由UFLDL提供,旨在教授无监督特征学习和深度学习的基本概念,并通过实践让读者理解并掌握这些算法,学会如何在新问题上应用和适应。教程要求读者具有基本的机器学习知识,特别是对有监督学习、逻辑回归和梯度下降的了解。如果读者不熟悉这些概念,推荐先完成斯坦福大学的在线机器学习课程的相关部分。
稀疏自编码器(Sparse Autoencoder)是神经网络的一种变体,其目标是学习数据的高效压缩表示。这种编码器能在保持输入数据大部分信息的情况下,将输入数据编码成一个更小的维度,然后通过解码器尝试重构原始输入。稀疏性是关键,意味着编码层的神经元激活应该尽可能地稀疏,即大部分神经元处于非激活状态,以此鼓励模型学习到更有意义的特征。
神经网络的反向传播算法(Backpropagation Algorithm)是训练自编码器的关键步骤。它通过计算损失函数相对于每个权重的梯度,然后用这个梯度更新权重来最小化损失,从而优化网络性能。梯度检查(Gradient checking)是一种用于验证反向传播算法正确性的技术,通过比较数值方法和符号方法计算的梯度来确保计算的准确性。
在优化过程中,除了基本的梯度下降,还有高级优化算法,如随机梯度下降(SGD)、动量(Momentum)、Adagrad、RMSprop和Adam等。这些算法可以加速收敛,避免局部最优,并在不同类型的优化问题中表现得更为稳健。
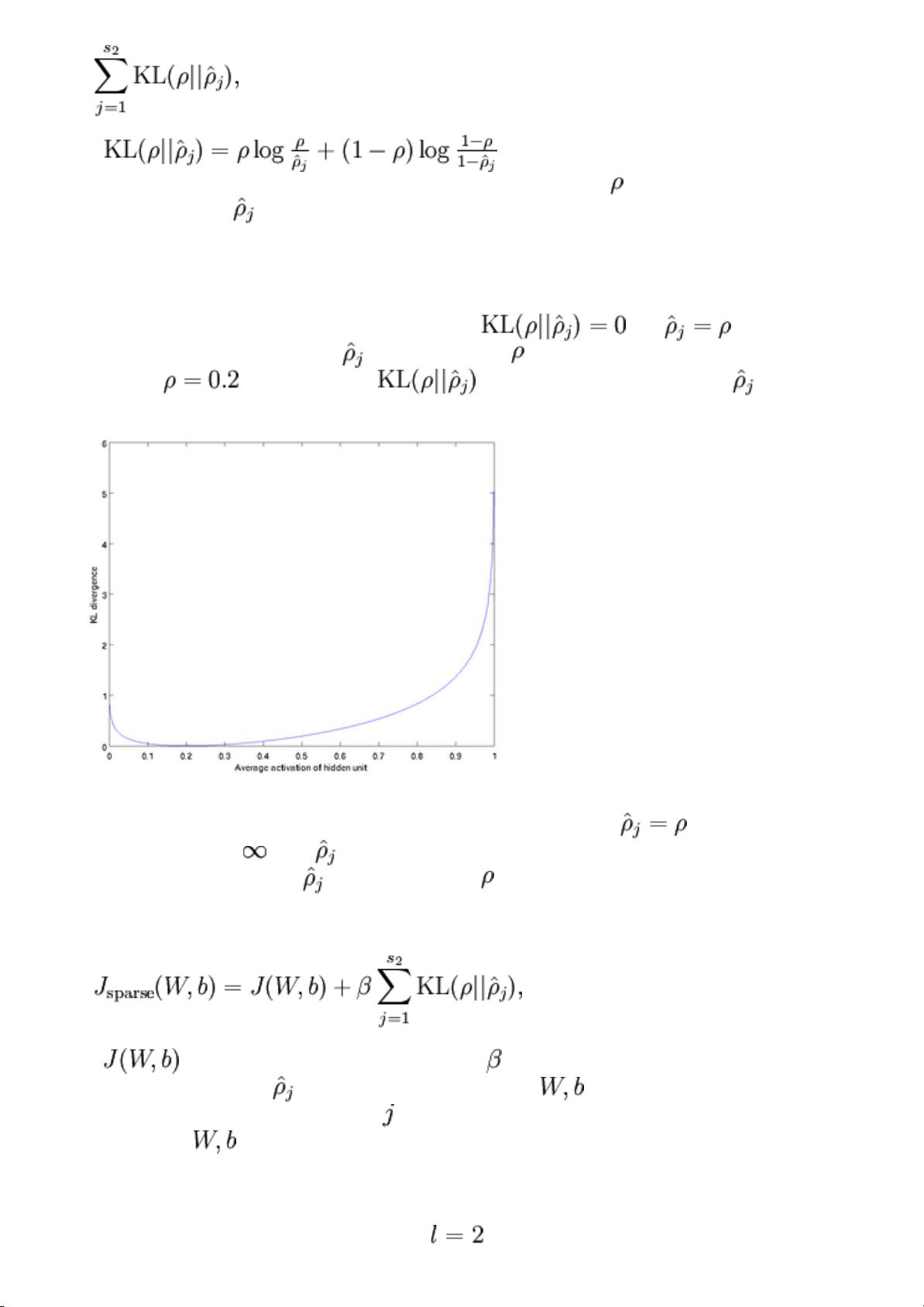
稀疏自编码器与一般的自编码器相比,特别强调了编码层的稀疏性约束。这通常通过在损失函数中添加正则项来实现,如KL散度,使得编码后的表示更加稀疏。理解并可视化训练好的自编码器可以帮助我们更好地理解模型学习到的特征。
在实践中,为了提高效率,通常会使用向量化实现(Vectorized Implementation)来构建和训练自编码器。这涉及到将批量数据同时传递给网络,使得计算过程并行化,显著提高了训练速度。
总结这部分教程,我们将学习如何构建和训练稀疏自编码器,理解其背后的数学和优化策略,并通过实际的编程练习来加深对稀疏自编码器的理解。这将为我们进一步探索深度学习的其他领域,如卷积神经网络(CNN)和递归神经网络(RNN)等打下坚实的基础。"
13-3-22 A utoencoders and S parsity - U fldl
1/4deeplearning.stanford.edu/w iki/index.php/A utoencoders_and_S parsity
Autoencoders and Sparsity
From Ufldl
So far, we have described the application of neural networks to supervised learning,
in which we have labeled training examples. Now suppose we have only a set of
unlabeled training examples , where . An autoencoder
neural network is an unsupervised learning algorithm that applies backpropagation,
setting the target values to be equal to the inputs. I.e., it uses .
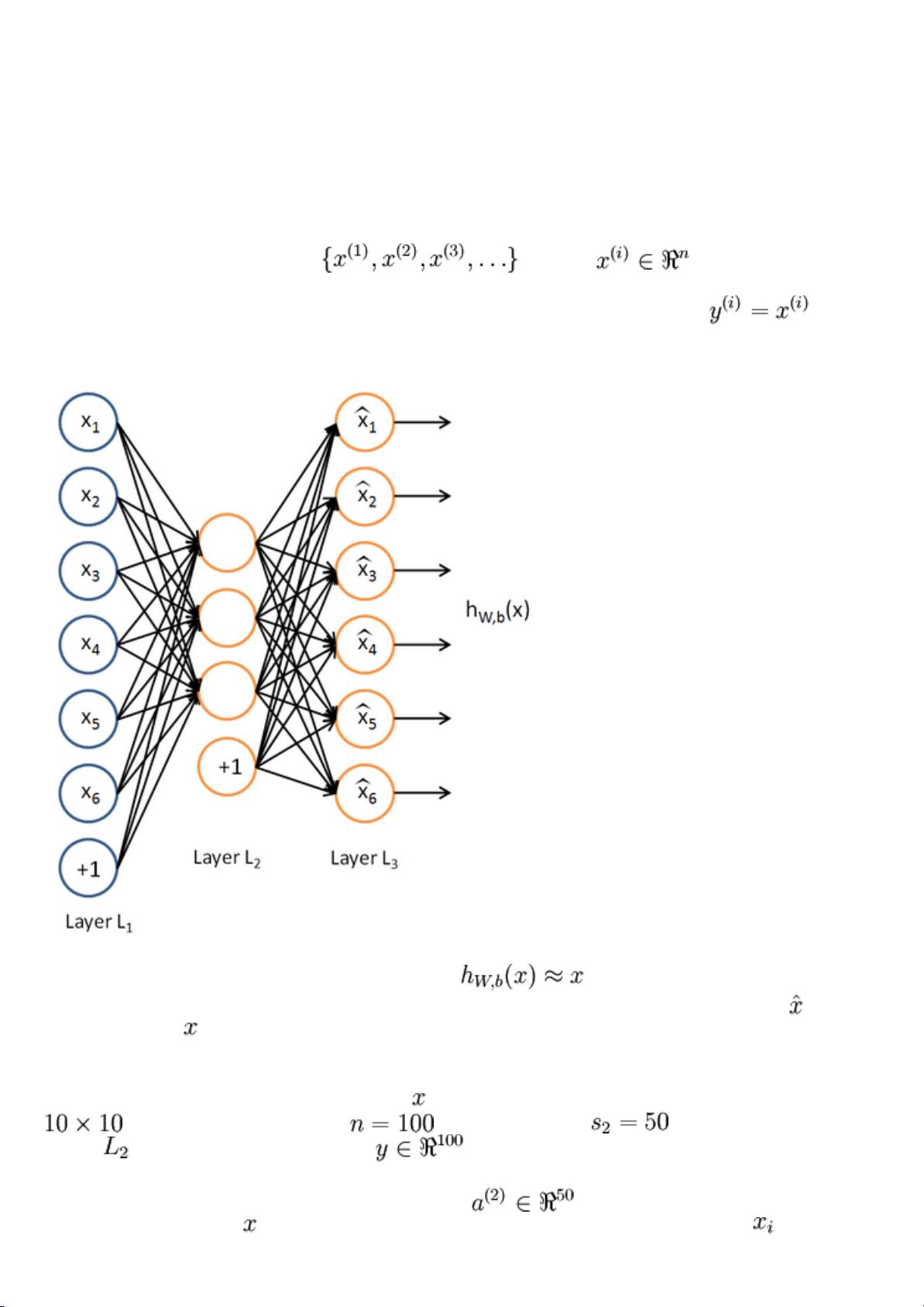
Here is an autoencoder:
The autoencoder tries to learn a function . In other words, it is
trying to learn an approximation to the identity function, so as to output that
is similar to . The identity function seems a particularly trivial function to be
trying to learn; but by placing constraints on the network, such as by limiting the
number of hidden units, we can discover interesting structure about the data. As a
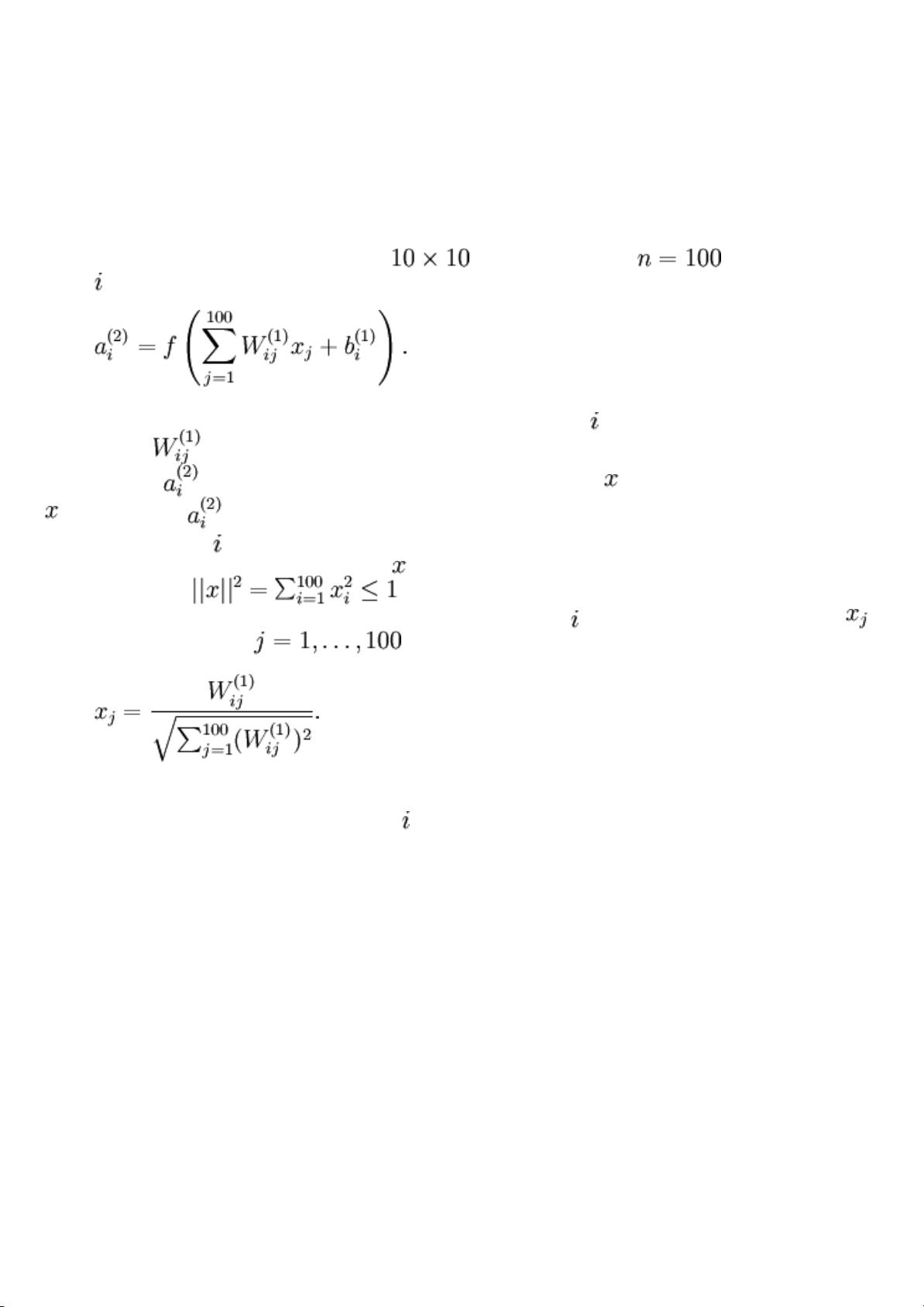
concrete example, suppose the inputs are the pixel intensity values from a
image (100 pixels) so , and there are hidden units in
layer . Note that we also have . Since there are only 50 hidden units,
the network is forced to learn a compressed representation of the input. I.e., given
only the vector of hidden unit activations , it must try to reconstruct
the 100-pixel input . If the input were completely random---say, each comes
from an IID Gaussian independent of the other features---then this compression task


剩余152页未读,继续阅读
相关推荐




NUAA_041060218
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 提升效率:网页成批阅读器v2.1官方免费版
- 修复java.lang.RuntimeException的bcprov-jdk15on-154.jar文件
- 学习Java编程的全新视角:learnPlayV2
- 掌握Destini项目:通过Swift实践Auto Layout与MVC模式
- IntelliJ IDEA Markdown插件:Multimarkdown Navigator
- 使用ForceBindIP软件强制指定应用走特定网卡上网
- ThinkPHP V3.3.7版本的微信支付类实现指南
- 电脑端心电图分析软件介绍
- 青少年上网行为管理软件新版本发布
- 响应式自助建站解决方案,定制开发五金电器app小程序
- 在字典中扩展您的好友位置 —— Gullible-crx插件解析
- Django实践指南:深入开发环境与图像处理
- PHP依赖管理工具Composer安装指南
- VB6.0与C# Dll互操作性解决方案详解
- Redmine插件实现自定义字段求和功能
- C#实现东芝B-EX4T打印机TCP/USB打印功能











