Kettle 5.3:HDFS与HBase连接及5.2源码编译指南
本文档主要介绍了如何在Kettle 5.3版本中连接HDFS(Hadoop分布式文件系统)和ICTBase,以及如何对Kettle 5.2源码进行编译。作者李雪梅在2015年5月26日发布此内容,提供了针对Hadoop 2.2.0版本的指南,其中Hadoop的安装是通过Ambari完成的,HDFS的访问端口设定为8020。
Kettle 5.3与Hadoop 2.x的集成依赖于相应的shim包,这里推荐使用hdp21包。为了配置Kettle以连接HDFS,用户需要在data-integration/plugins/pentaho-big-data-plugin/plugin.properties文件中将active.hadoop.configuration属性值设置为hdp21。确保JDK 1.7版本已经正确配置,因为Kettle需要它来运行。此外,还需检查NameNode、DataNode和SecondaryNameNode是否已启动,因为这些是HDFS的核心组件。
连接Kettle到HDFS的具体步骤包括创建新的作业(Job),在设计模式下添加START组件作为起点,然后添加HadoopCopyFiles组件来实现数据复制。执行后,可以在指定的URL(如http://10.1.111.13:50070)上查看传输过来的目录。
对于ICTBase的连接,文档提到使用的是HBase 0.94.13版本。用户需要将hbase-site.xml配置文件从ICTBase的默认位置拷贝到Kettle插件的特定目录,并可能需要对hadoop-configurations/hdp21下的配置进行调整以适应HBase的连接需求。
同时,文章还提到了对Kettle 5.2源码编译的过程,虽然具体内容没有详述,但可以推测这部分内容可能涉及源代码的获取、构建环境的设置、编译选项的选择以及可能的定制化需求,以便在需要时对Kettle进行自定义开发或扩展。
本文档提供了实用的指导,帮助Kettle用户在处理大数据存储和处理时,有效地配置和利用Hadoop和HBase,并展示了如何处理不同组件之间的集成,以及源码编译的基本流程。
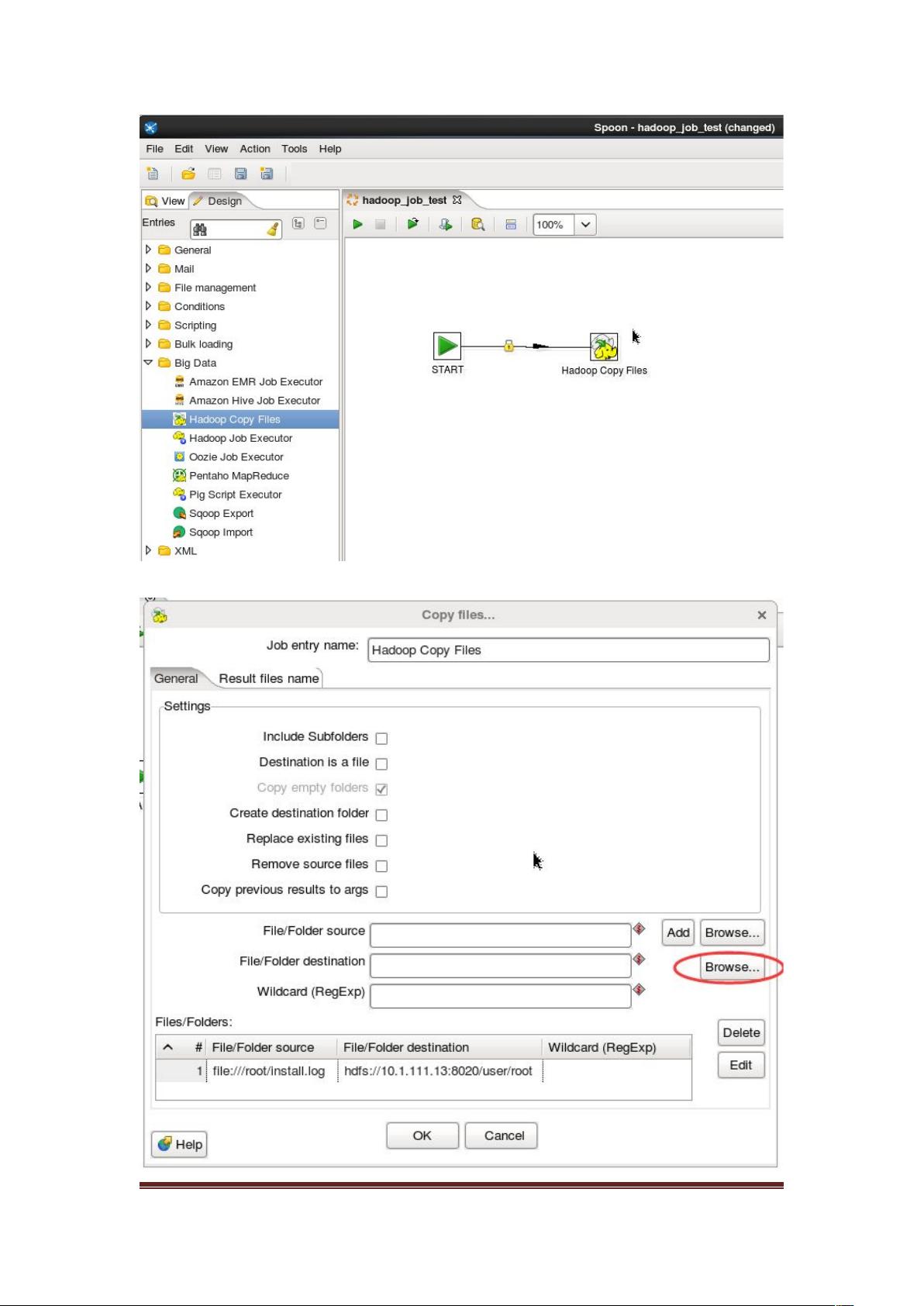
、 配置 ( 如下:
版权所有©中国科学院计算技术研究所烟台分所 5
剩余21页未读,继续阅读
285 浏览量
423 浏览量
367 浏览量
646 浏览量
129 浏览量
2019-05-07 上传









