华中科技大学机器学习课件:从入门到深度
需积分: 9 186 浏览量
更新于2024-07-15
收藏 1.58MB PDF 举报
"华中科技大学的机器学习课程课件,由HongHuang教授编写,涵盖了机器学习的基础概念、设置、损失函数、泛化以及训练与测试等核心内容。"
在机器学习领域,这个课件首先介绍了机器学习与传统计算机科学的区别。机器学习是一种让计算机通过数据学习规律和模式的方法,而非依赖于明确的编程指令。传统计算机科学侧重于算法和程序设计,而机器学习则更注重模型的构建和优化,使计算机能够自我适应和改进。
历史上的人工智能(AI)是机器学习发展的重要背景。从早期的符号主义方法到后来的连接主义,再到现代的深度学习,AI的发展推动了机器学习技术的不断进步。机器学习被分为多个类别,包括监督学习、无监督学习、半监督学习、强化学习等,每种类型都有其特定的应用场景和学习方式。
在设置部分,课件讲解了监督学习的基本框架,这是最常见的机器学习类型。监督学习中,数据集包含特征向量和对应的标签,用于训练模型。例如,特征向量可以是图像的像素值,而标签可能是图像中的物体类别。特征向量的选择对模型性能至关重要。
接着,课件提到了几种常见的损失函数,如零一损失(0-1 Loss)、平方损失(Squared Loss)和绝对损失(Absolute Loss)。损失函数衡量了模型预测结果与真实值之间的差异,是优化模型的关键。零一损失仅在预测完全正确或错误时给出非零值,平方损失则对误差敏感,而绝对损失介于两者之间。
泛化能力是机器学习模型的重要指标,表示模型对未见过的数据的预测能力。过度拟合(Overfitting)是模型在训练数据上表现良好,但在新数据上表现较差的现象,通常由于模型过于复杂或者训练数据不足导致。为了防止过拟合,通常会使用交叉验证和正则化等技术。
在训练与测试环节,课件讨论了如何划分数据集,比如使用训练集和测试集进行模型训练和评估。训练集用于训练模型,而测试集用于验证模型的泛化性能。最后,将所有这些概念和步骤结合在一起,形成完整的机器学习流程。
这份机器学习课件是理解这一领域的基础概念和实践方法的良好资源,对于初学者和深入研究者都具有很高的参考价值。
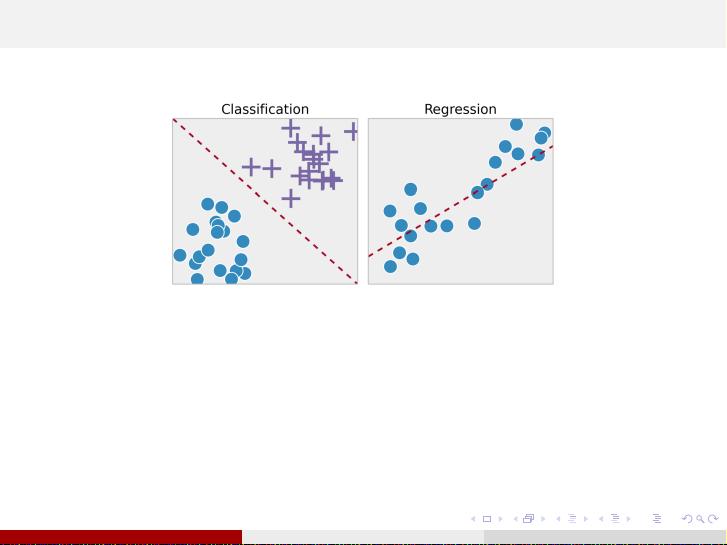
Supervised Learning
Supervised learning, an algorithm learns from a training dataset. We know the correct
answers or desired output, the algorithm makes predictions using the given dataset and is
corrected by the ”supervisor”. The learning stops as and when the algorithm achieves a
level of performance which is acceptable. There are two types of supervised learning-
regression and classification. Regression models are applied to solve various problems;
e.g. predicting stock price. (https://towardsdatascience.com/stock-prediction-in-python-
b66555171a2,https://www.analyticsvidhya.com/blog/2018/10/predicting-stock-price-
machine-learningnd-deep-learning-techniques-python/)
Hong Huang (HUST) Machine Learning 2019-04-28 6 / 30
剩余29页未读,继续阅读
点击了解资源详情
105 浏览量
点击了解资源详情
159 浏览量
405 浏览量
209 浏览量
132 浏览量
2021-10-18 上传
163 浏览量

南隹
- 粉丝: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易酷免费影视系统:开源网站代码与简易后台管理
- Coursera美国人口普查数据集及使用指南解析
- 德加拉6800卡监控:性能评测与使用指南
- 深度解析OFDM关键技术及其在通信中的应用
- 适用于Windows7 64位和CAD2008的truetable工具
- WM9714声卡与DW9000网卡数据手册解析
- Sqoop 1.99.3版本Hadoop 2.0.0环境配置指南
- 《Super Spicy Gun Game》游戏开发资料库:Unity 2019.4.18f1
- 精易会员浏览器:小尺寸多功能抓包工具
- MySQL安装与故障排除及代码编写全攻略
- C#与SQL2000实现的银行储蓄管理系统开发教程
- 解决Windows下Pthread.dll缺失问题的方法
- I386文件深度解析与oki5530驱动应用
- PCB涂覆OSP工艺应用技术资源下载
- 三菱PLC自动调试台程序实例解析
- 解决OpenCV 3.1编译难题:配置必要的库文件
