探索 Neo4j 图形数据库的应用与概念对比
需积分: 15 139 浏览量
更新于2024-09-12
收藏 291KB PDF 举报
"《图数据库应用与概念:Neo4j详解》是一篇发表于2013年南方信息系统协会会议的论文,作者是Justin J. Miller,他来自乔治亚南方大学。文章探讨了图数据库(GDB)作为关系数据库系统(RDBMS)的一种可行替代方案,特别是在化学、生物学、语义网、社交网络和推荐引擎等领域的应用。论文将重点比较Oracle、MySQL等传统RDBMS与Neo4j这样的图数据库在数据结构、数据模型特性以及查询功能方面的异同。
首先,作者强调了图数据库在处理复杂关系数据时的优势,如化学分子结构中的原子间连接,社交网络中的人际关系网络,或者推荐系统中用户与商品之间的多对多关联。在这些场景中,图数据库能够以更自然的形式存储和查询数据,因为它们的基础是节点(node)、边(edge)和关系(relation),而非传统的表格和行。
文章详细介绍了Neo4j的数据模型——属性图模型(property graph),其中每个节点和边都可以携带属性,这使得数据更加灵活。与关系数据库的ACID属性(原子性、一致性、隔离性和持久性)相比,图数据库可能牺牲一部分严格的事务处理一致性,但其非关系型的特性允许在处理大规模数据和实时查询时表现出色。
此外,论文还讨论了图数据库在数据局部性、协作过滤(collaborative filtering)和内容过滤(content-based filtering)等场景中的优势。数据局部性意味着在图中查找相邻节点或路径通常更快,这对于搜索引擎和推荐系统至关重要。而在推荐系统中,图数据库可以通过遍历(traversal)找到用户兴趣相似的其他用户或商品,从而实现个性化推荐。
然而,论文也指出当前图数据库的一些局限性,包括可能的性能瓶颈、缺乏成熟的备份和恢复机制,以及在某些特定场景下可能不如关系数据库的查询效率。这篇论文为读者提供了深入理解图数据库特别是Neo4j在实际应用中的优势和挑战,帮助技术人员在选择合适的数据存储技术时作出明智决策。"
Miller Graph Database Applications and Concepts
Proceedings of the Southern Association for Information Systems Conference, Atlanta, GA, USA March 23
rd
-24
th
, 2013
141
Graph Database Applications and Concepts with Neo4j
Justin J. Miller
Georgia Southern University
jm10197@georgiasouthern.edu
ABSTRACT
Graph databases (GDB) are now a viable alternative to Relational Database Systems (RDBMS). Chemistry, biology,
semantic web, social networking and recommendation engines are all examples of applications that can be represented in a
much more natural form. Comparisons will be drawn between relational database systems (Oracle, MySQL) and graph
databases (Neo4J) focusing on aspects such as data structures, data model features and query facilities. Additionally, several
of the inherent and contemporary limitations of current offerings comparing and contrasting graph vs. relational database
implementations will be explored.
Keywords
Graph database, relational database, data model, property graph, vertex, edge, node, relation, traversal, attribute, ACID,
locality, collaborative filtering, content based filtering
INTRODUCTION
The relational database model has been around since the late 1960s [4]. It has proven to consistently provide persistence,
concurrency control, and integration mechanisms. Relational databases maintain tables which are defined by sets of rows and
columns. A row can be perceived as an object while columns would be attributes/properties of that objects [15]. One of the
weaknesses of the relational model is its limited ability to explicitly capture requirement semantics [14]. Big data problems
involving complex interconnected information have become increasingly common in the sciences. Storing, retrieving, and
manipulating such complex data becomes onerous when using traditional RDBMS approaches. Schema based data models by
their very definition put in place limits on how information will be stored. There is an involved manual process to redesign
the schema in order to adapt to new data. Where the RDBMS is optimized for aggregated data, graph databases such as
Neo4j are optimized for highly connected data.
A graph is a data structure composed of edges and vertices [2]. Graph database technology is an effective tool for modeling
data when a focus on the relationship between entities is a driving force in the design of a data model [3]. Modeling objects
and the relationships between them means almost anything can be represented in a corresponding graph. A common graph
type supported by most systems is the property graph. Property graphs are attributed, labeled, directed multi-graphs [2].
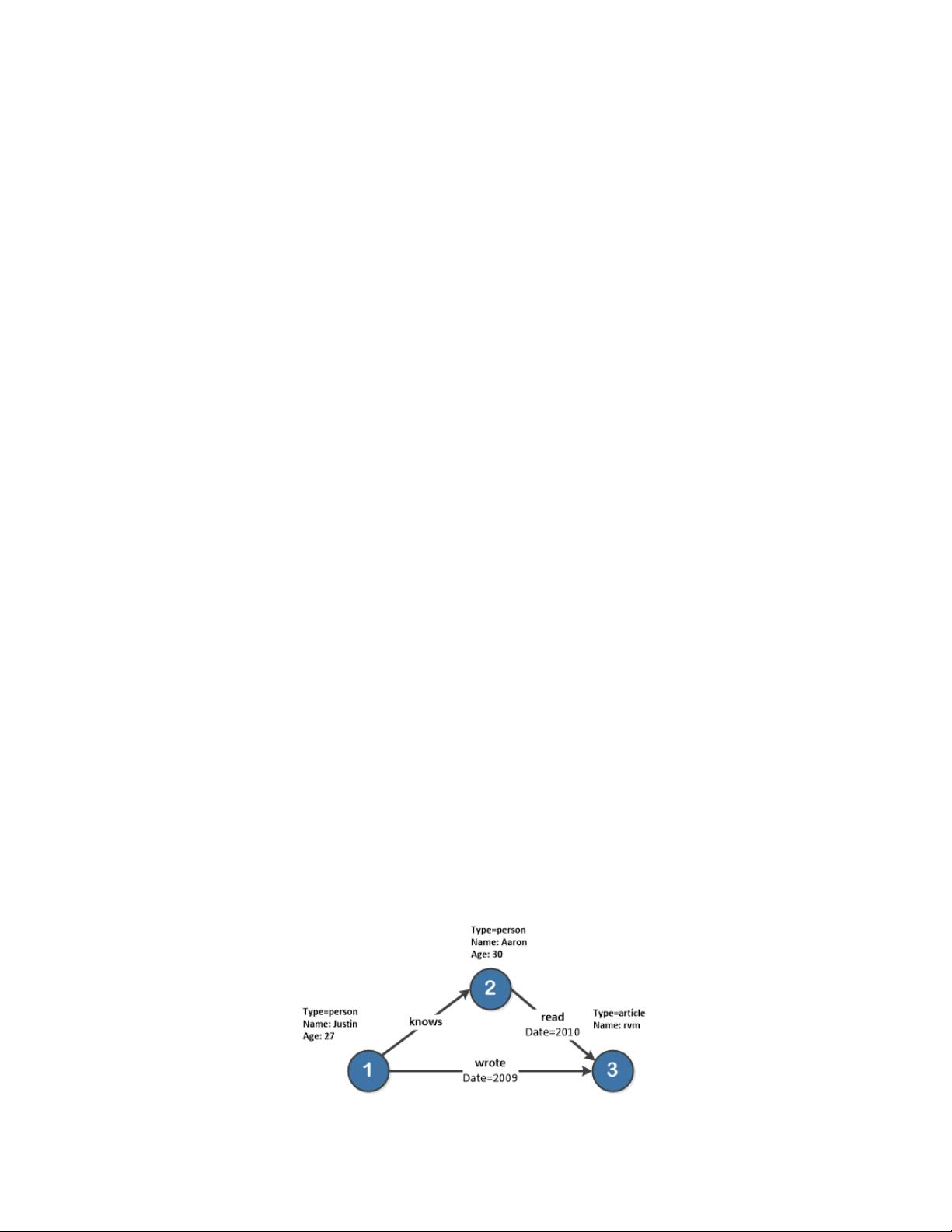
Figure 1 provides a visual example of a property graph which represents interactions between people and objects. A benefit
to the multi graph is that it is the most complex implementation because every other type of graph consists of subsets of the
property graph implementation. This means a property graph can effectively model all other graph types. The graph database
is optimized for the efficient processing of dense, interrelated datasets [2]. This design allows the construction of predictive
models, and detection of correlations and patterns [3]. This highly dynamic data model in which all nodes are connected by
relations allows for fast traversals along the edges between vertices. A particular benefit is the fact that traversals are
localized and do not have to take into account sets of unrelated data. A problem that is inherent in SQL [15].
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-06-28 上传
2019-07-17 上传
2019-07-17 上传
2019-07-17 上传
2019-11-12 上传
2016-02-16 上传


134678098
- 粉丝: 7
- 资源: 71
 我的内容管理
展开
我的内容管理
展开







最新资源
- PROTEL99SE.pdf
- 谭浩强c语言 pdf版(带书签)
- Div+CSS 布局大全.pdf
- 写给大家看的面向对象编程书 第3版 (最通俗易懂的面向对象著作)
- 遗传算法源程序(c语言)
- java 图书馆管理系统论文
- netbackup_unix 中文命令手册
- mini2440 root_qtopia 文件系统启动过程分析
- 电子秤标定方法 各种电子称 大全
- postfix权威指南
- Weblogic管理指南
- [游戏编程书籍].2_OpenGL.Extensions.-.Nvidia.pdf
- 毕业设计(物流配送管理)
- 游程编码 matlab实现
- 你必须知道的.NET(PDF文档)
- Android+eclipse环境配置
