HDFS读写流程与NameNode、DataNode详解:分布式存储与操作
HDFS(Hadoop Distributed File System)是一种专为大规模数据处理设计的分布式文件系统,其核心理念是“分而治之”,将大文件和大批量数据分散到多台服务器上,便于分布式计算框架(如MapReduce、Spark、Tez等)进行高效的数据存储和分析。以下是HDFS的主要组成部分和工作原理:
1. **设计思想**:
- 分布式存储:HDFS通过将文件分割成固定大小的块(block),每个块会在多个DataNode服务器上保存多个副本,提供数据冗余和高可用性。
- 名称节点(NameNode)与数据节点(DataNode):NameNode是整个HDFS集群的主节点,负责全局命名空间的管理和元数据存储,包括目录树结构和文件块信息。DataNode负责实际的数据存储,执行读写请求。
2. **关键概念**:
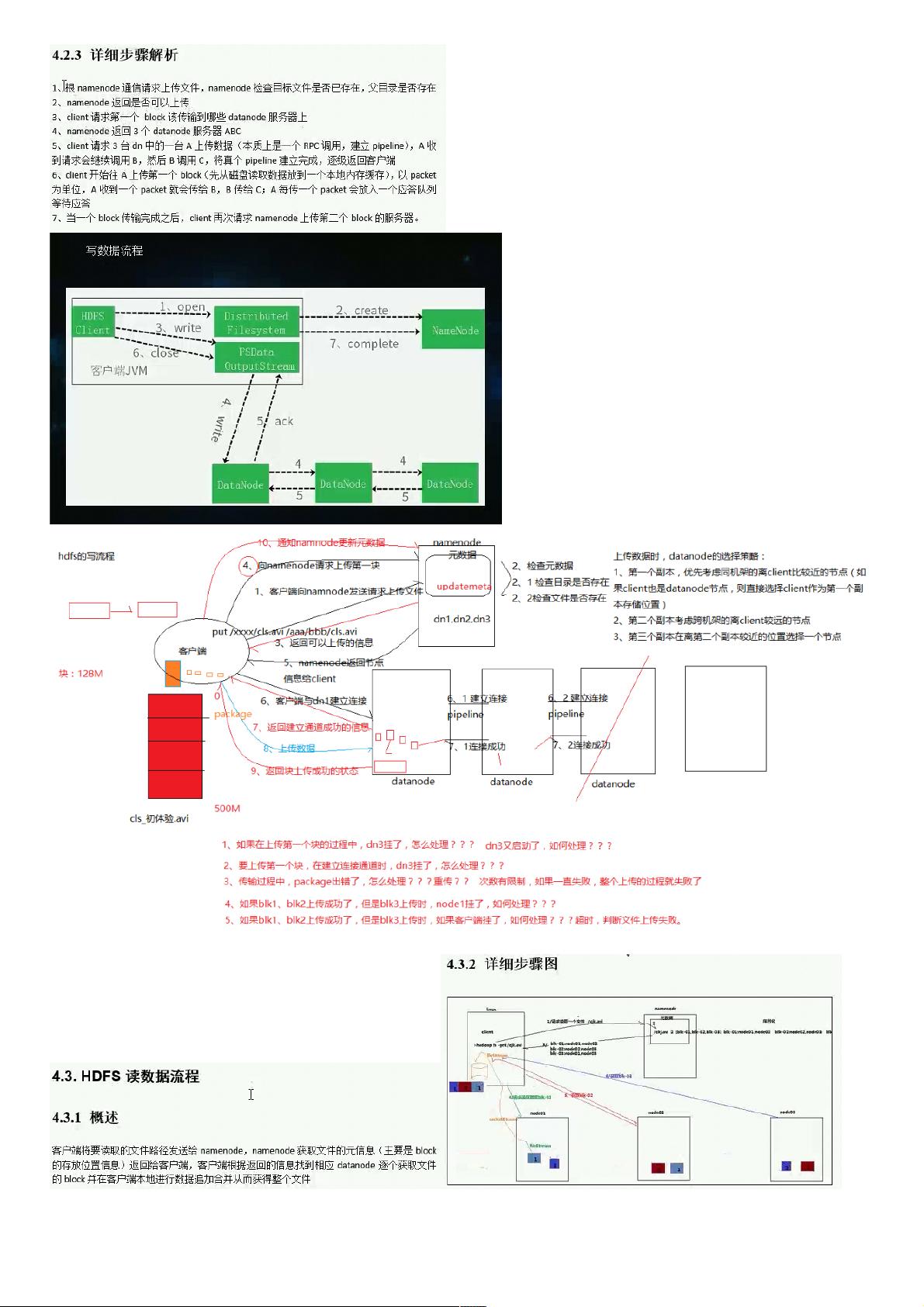
- **文件块**(Block):文件被划分为固定大小的块,大小可通过`dfs.blocksize`参数配置,默认值在Hadoop 2.x版本中为128MB,在早期版本中为64MB。
- **副本存放**:为了容错和性能优化,每个文件块都有多个副本,副本数量可通过`dfs.replication`参数设置。
- **元数据**:包括文件名、目录结构和块信息,由NameNode管理。
3. **文件系统接口**:
- 客户端访问:用户通过路径(如`hdfs://namenode:port/dir-a/dir-b/dir-c/file.data`)来访问文件,这个路径提供了统一的抽象目录树。
- 不支持修改:HDFS设计用于一次写入,多次读取的场景,不支持文件的修改操作。
4. **命令行工具**:
- HDFS命令行客户端(hdfs dfs)提供了丰富的操作选项,如复制文件(`copyFromLocal`和`copyToLocal`)、查看文件信息(`-cat`)、更改权限(`chmod`)、检查文件校验和(`-checksum`)等。
通过学习HDFS的工作机制,开发人员可以更好地理解和利用这个强大的分布式文件系统,进行高效的数据存储和处理,同时保持数据的高可用性和容错性。在实际应用中,熟练掌握HDFS的命令行工具对于日常运维和数据管理至关重要。
剩余11页未读,继续阅读
2022-07-11 上传
2020-04-03 上传
2021-09-29 上传
2023-05-26 上传
2024-10-27 上传
2023-03-09 上传
2023-05-25 上传
2023-05-29 上传
2023-06-10 上传

weixin_38743737
- 粉丝: 376
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
