YOLOv6:工业应用的单阶段目标检测框架
需积分: 0 109 浏览量
更新于2024-06-26
收藏 1.03MB PDF 举报
本文档探讨了名为"YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications"的论文,该研究旨在为工业应用提供一个高效的单阶段目标检测框架。YOLOv6是YOLO系列的最新版本,继承了YOLO(You Only Look Once)的传统,即一次前向传播就能完成物体检测,从而在速度和准确性上寻求平衡。论文的核心关注点在于工业场景下的性能优化,这包括对实时性和资源利用率的需求。
YOLOv6的设计目标是在保持较高检测精度的同时,减少模型复杂度和计算开销,使之适应于资源有限的工业设备。为了实现这一目标,作者可能采用了先进的架构改进,如更深层次的网络结构、特征融合技术、以及量化技术来减小模型大小,提高在如Tesla T4 GPU上的运行效率。在图1中,作者展示了YOLOv6与其他当前最先进的高效对象检测器(如YOLOv5、YOLOv7、YOLOX和PP-YOLOE)在延迟(ms)和吞吐量(FPS)方面的对比,其中在保持32批次输入时,YOLOv6展示出出色的性能,尤其是在较低的延迟下仍能保持较高的平均精度(COCO AP%)。
论文可能深入分析了YOLOv6的具体组成部分,例如不同规模的模型(N、T、S、M、L),以及量化版YOLOv6-S的表现,这些模型大小各异,以适应不同的硬件配置和部署环境。此外,可能会讨论如何通过调整模型的深度和宽度、优化算法或采用混合精度(如FP16)来优化模型在工业级应用中的实际运行情况。
为了满足工业环境的挑战,论文可能还涉及到了模型的部署策略、推理时的内存管理和能耗分析,这些都是衡量一个目标检测框架是否真正实用的关键因素。同时,由于标题中的“毕业设计”标签,可以推测这可能是某个学生的研究成果,因此论文也可能包含了方法论、实验设计、结果验证以及对未来研究方向的讨论。
这篇论文深入研究了YOLOv6作为一款面向工业应用的单阶段目标检测框架,其在速度、准确性和适应性方面的优势,以及与同类技术的比较,对于那些关注工业级计算机视觉任务的开发者和研究人员具有重要的参考价值。
utilizes the computing power of the hardware, resulting in
a significant decrease in inference latency while enhancing
the representation ability in the meantime.
However, we notice that with the model capacity further
expanded, the computation cost and the number of param-
eters in the single-path plain network grow exponentially.
To achieve a better trade-off between the computation bur-
den and accuracy, we revise a CSPStackRep Block to build
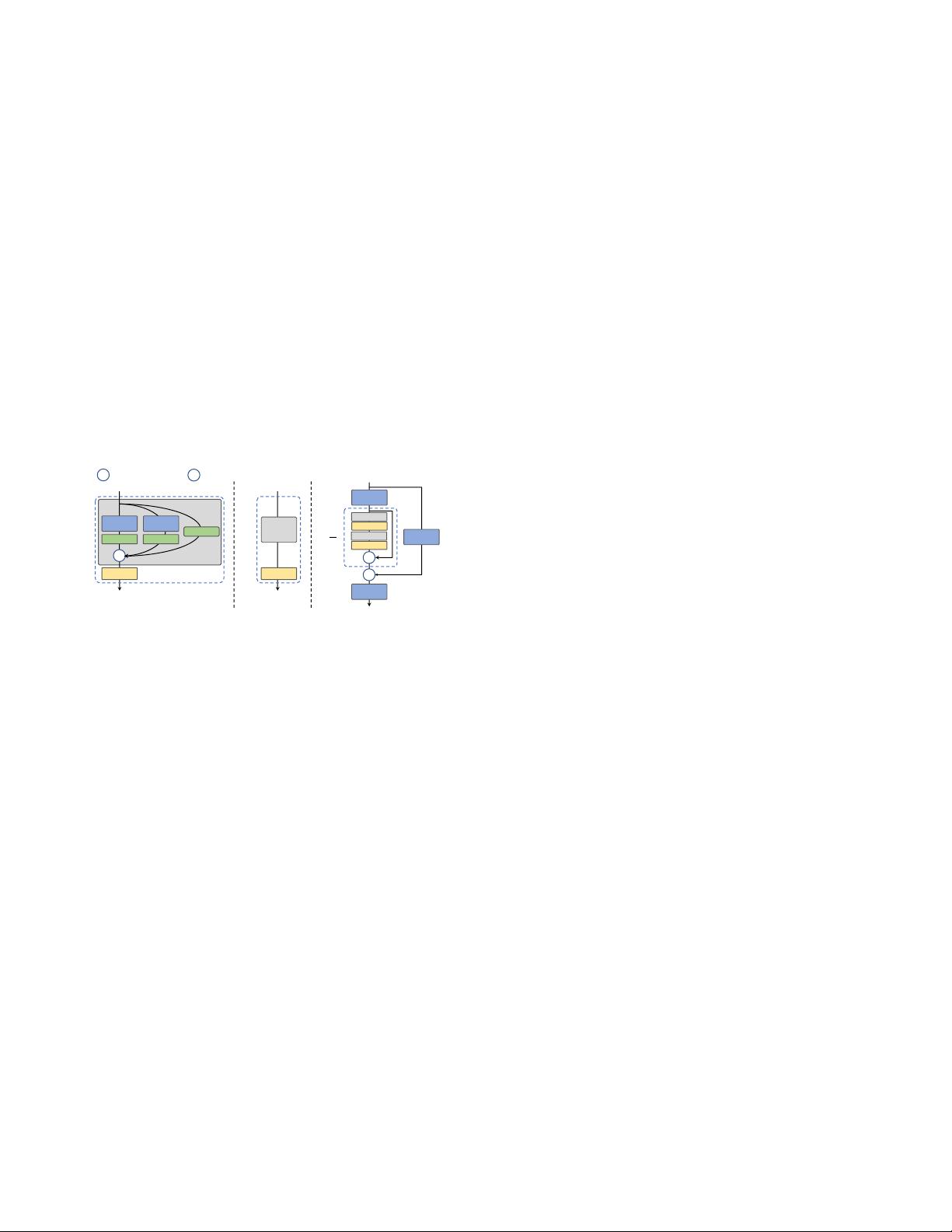
the backbone of medium and large networks. As shown
in Fig. 3 (c), CSPStackRep Block is composed of three 1×1
convolution layers and a stack of sub-blocks consisting of
two RepVGG blocks [3] or RepConv (at training or infer-
ence respectively) with a residual connection. Besides, a
cross stage partial (CSP) connection is adopted to boost
performance without excessive computation cost. Com-
pared with CSPRepResStage [45], it comes with a more
succinct outlook and considers the balance between accu-
racy and speed.
RepConv
𝟏×𝟏
Conv
RepConv
+
𝑁
2
×
C
𝟏×𝟏
Conv
𝟏×𝟏
Conv
(a)
(c)
+
: Element-wise add
C
: Concatenation over channel dimension
ReLU
+
BN
𝟏×𝟏
Conv
𝟑×𝟑
Conv
BN
ReLU
𝑁×
RepVGG block
𝑁×
(b)
RepConv
ReLU
ReLU
BN
Figure 3: (a) RepBlock is composed of a stack of RepVGG
blocks with ReLU activations at training. (b) During infer-
ence time, RepVGG block is converted to RepConv. (c)
CSPStackRep Block comprises three 1×1 convolutional
layers and a stack of sub-blocks of double RepConvs fol-
lowing the ReLU activations with a residual connection.
2.1.2 Neck
In practice, the feature integration at multiple scales has
been proved to be a critical and effective part of object de-
tection [9, 21, 24, 40]. We adopt the modified PAN topol-
ogy [24] from YOLOv4 [1] and YOLOv5 [10] as the base
of our detection neck. In addition, we replace the CSP-
Block used in YOLOv5 with RepBlock (for small models)
or CSPStackRep Block (for large models) and adjust the
width and depth accordingly. The neck of YOLOv6 is de-
noted as Rep-PAN.
2.1.3 Head
Efficient decoupled head The detection head of
YOLOv5 is a coupled head with parameters shared be-
tween the classification and localization branches, while its
counterparts in FCOS [41] and YOLOX [7] decouple the
two branches, and additional two 3×3 convolutional layers
are introduced in each branch to boost the performance.
In YOLOv6, we adopt a hybrid-channel strategy to build
a more efficient decoupled head. Specifically, we reduce
the number of the middle 3×3 convolutional layers to only
one. The width of the head is jointly scaled by the width
multiplier for the backbone and the neck. These modifica-
tions further reduce computation costs to achieve a lower
inference latency.
Anchor-free Anchor-free detectors stand out because of
their better generalization ability and simplicity in decod-
ing prediction results. The time cost of its post-processing
is substantially reduced. There are two types of anchor-
free detectors: anchor point-based [7, 41] and keypoint-
based [16, 46, 53]. In YOLOv6, we adopt the anchor point-
based paradigm, whose box regression branch actually pre-
dicts the distance from the anchor point to the four sides of
the bounding boxes.
2.2. Label Assignment
Label assignment is responsible for assigning labels to
predefined anchors during the training stage. Previous work
has proposed various label assignment strategies ranging
from simple IoU-based strategy and inside ground-truth
method [41] to other more complex schemes [5, 7, 18, 48,
51].
SimOTA OTA [6] considers the label assignment in ob-
ject detection as an optimal transmission problem. It defines
positive/negative training samples for each ground-truth ob-
ject from a global perspective. SimOTA [7] is a simpli-
fied version of OTA [6], which reduces additional hyper-
parameters and maintains the performance. SimOTA was
utilized as the label assignment method in the early version
of YOLOv6. However, in practice, we find that introducing
SimOTA will slow down the training process. And it is not
rare to fall into unstable training. Therefore, we desire a
replacement for SimOTA.
Task alignment learning Task Alignment Learning
(TAL) was first proposed in TOOD [5], in which a unified
metric of classification score and predicted box quality is
designed. The IoU is replaced by this metric to assign object
labels. To a certain extent, the problem of the misalignment
of tasks (classification and box regression) is alleviated.
The other main contribution of TOOD is about the task-
aligned head (T-head). T-head stacks convolutional layers to
build interactive features, on top of which the Task-Aligned
Predictor (TAP) is used. PP-YOLOE [45] improved T-
head by replacing the layer attention in T-head with the
4
剩余16页未读,继续阅读
320 浏览量
172 浏览量
2670 浏览量
137 浏览量
1633 浏览量
2023-05-22 上传
236 浏览量

福尔摩星儿
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 初学者入门必备!Visual C++开发的连连看小程序
- C#实现SqlServer分页存储过程示例分析
- 西门子工业网络通信例程解读与实践
- JavaScript实现表格变色与选中效果指南
- MVP与Retrofit2.0相结合的登录示例教程
- MFC实现透明泡泡效果与文件操作教程
- 探索Delphi ERP框架的核心功能与应用案例
- 爱尔兰COVID-19案例数据分析与可视化
- 提升效率的三维石头制作插件
- 人脸C++识别系统实现:源码与测试包
- MishMash Hackathon:Python编程马拉松盛事
- JavaScript Switch语句练习指南:简洁注释详解
- C语言实现的通讯录管理系统设计教程
- ASP.net实现用户登录注册功能模块详解
- 吉时利2000数据读取与分析教程
- 钻石画软件:从设计到生产的高效解决方案
