基于过完备独立成分分析的动作识别框架
42 浏览量
更新于2024-08-29
收藏 1.68MB PDF 举报
“基于过完备独立成分分析的动作识别”
在当前的计算机视觉领域,动作识别是研究的热点之一,主要用于理解视频中的动态行为。传统的动作识别方法通常分为两个阶段:(1)设计或学习手工艺品特征,这可能包括颜色、纹理、运动等;(2)使用分类器(如支持向量机SVM或Adaboost)对提取的特征进行分类。然而,这些方法往往依赖于复杂的特征工程,并且可能无法充分利用视频数据的内在特性。
基于两个关键观察,本文提出了一种新的、简单但有效的动作识别框架——利用过完备独立成分分析(Overcomplete Independent Component Analysis, OICA)。首先,观察到独立成分分析(ICA)能够从视频数据中编码内在的、本质的特征。这些内在特征通常包含有关动作的最重要信息,例如运动模式、物体交互和时空结构。其次,注意到不同动作之间的主要区别往往在于它们的内在特征。因此,OICA模型被用来代替传统的方法,以自动学习视频的这些关键特征。
过完备表示是该方法的核心概念。在传统的ICA中,数据被表示为有限个独立成分的线性组合,而在过完备ICA中,这个基础集合是“过完备”的,即基础的数量多于数据的维度。这样的设置允许模型以更灵活的方式捕获数据的复杂性,特别是对于具有高维度和复杂时间序列结构的视频数据。
在文章中,作者首先通过训练过完备的ICA基函数来学习视频的内在表示。这一过程涉及最小化重构误差,以确保所学习的基函数能有效地代表原始数据。随后,这些内在特征用于构建一个分类器,可以区分不同的动作类别。由于这些特征是由数据驱动的,而不是人为设计的,因此它们更可能捕捉到与动作识别相关的关键信息。
实验部分,作者可能在各种基准数据集上验证了提出的框架,如UCF101、HMDB51等,以评估其性能。通过与其他方法的比较,展示了OICA在动作识别任务上的优势,可能包括更高的准确率和更好的泛化能力。
这篇论文提供了一个新颖的视角来处理动作识别问题,利用过完备的独立成分分析进行特征学习,简化了传统方法的复杂性,并提高了识别效果。这种方法的潜在应用范围广泛,可以应用于监控系统、社交媒体分析、人机交互等多个领域。
2.1. Hand-designed features for action recognition
Extracting local features for action recognition usually consists of two steps: detecting features with a detector and rep-
resenting features with a descriptor. Both the detector and descriptor are usually extended from 2D image domain to 3D
video domain, inspired by their success in object recognition. Laptev and Linderberg [25] extends the Harris detector [15]
and proposes the Harris3D detector. Dollar et al. [11] proposes the Cuboid detector, which first computes the temporal Gabor
filters responses and then locates the interest points by finding the maximal responses in a local range. Inspired by the suc-
cess of the Hessian saliency measure used in blob detection in images, Willems et al. [53] proposes the Hessian detector as a
spatio-temporal extension of the Hessian saliency measure. In addition to these sparse interest point detector, dense sam-
pling can also be considered as a special detector which extracts video patches at regular positions and scales.
After detecting an interest point, a feature descriptor is used to extract local features around the interest point. Dollar
et al. [11] proposes the Cuboid descriptor. To characterize the local motion and appearance features, Laptev et al. [26] com-
putes histograms of spatial gradient and optical flow accumulated in space–time neighborhoods of the detected interest
points. Klaser et al. [24] proposes the HOG3D descriptor, which is based on histograms of 3D gradient orientations and there-
fore can be seen as an extension of the popular SIFT descriptor [33]. Similarly, Willems et al. [53] extends the SURF descriptor
[4] to extract features from a video.
2.2. Learning based features for action recognition
Recently, feature learning methods have been introduced in action recognition. Taylor et al. [46] proposes a novel con-
volutional GRBM method for learning spatio-temporal features, which can be considered as an extension of convolutional
RBMs from 2D images to 3D videos. Because the objective function is intractable and thus sampling is required, their method
has high computational cost and takes 2–3 days to train the model on the Hollywood2 dataset. This disadvantage limits their
applications for large scale problems. Ji et al. [22] extends convolutional neural networks from 2D spatial domain to 3D spa-
tio-temporal domain to learn features for action recognition. This method extracts features from both the spatial and tem-
poral dimensions by performing 3D convolutions, thereby capturing the motion information encoded in multiple adjacent
frames. Similar to Taylor et al. [46], Le et al. [29] proposes a hierarchical invariant spatio-temporal feature learning frame-
work based on independent subspace analysis. Their model consists of two layers. The first layer vectorizes the sampled 3D
patches into column vectors and then uses ICA to learn a set of ICA basis functions. The second layer uses the subspace ICA to
encode the responses of the first layers. Finally the responses of the first and second layers are combined to form the final
features vector using the bag-of-word model [27]. The feature vectors are then fed into a SVM classifier to perform
classification.
3. Proposed method
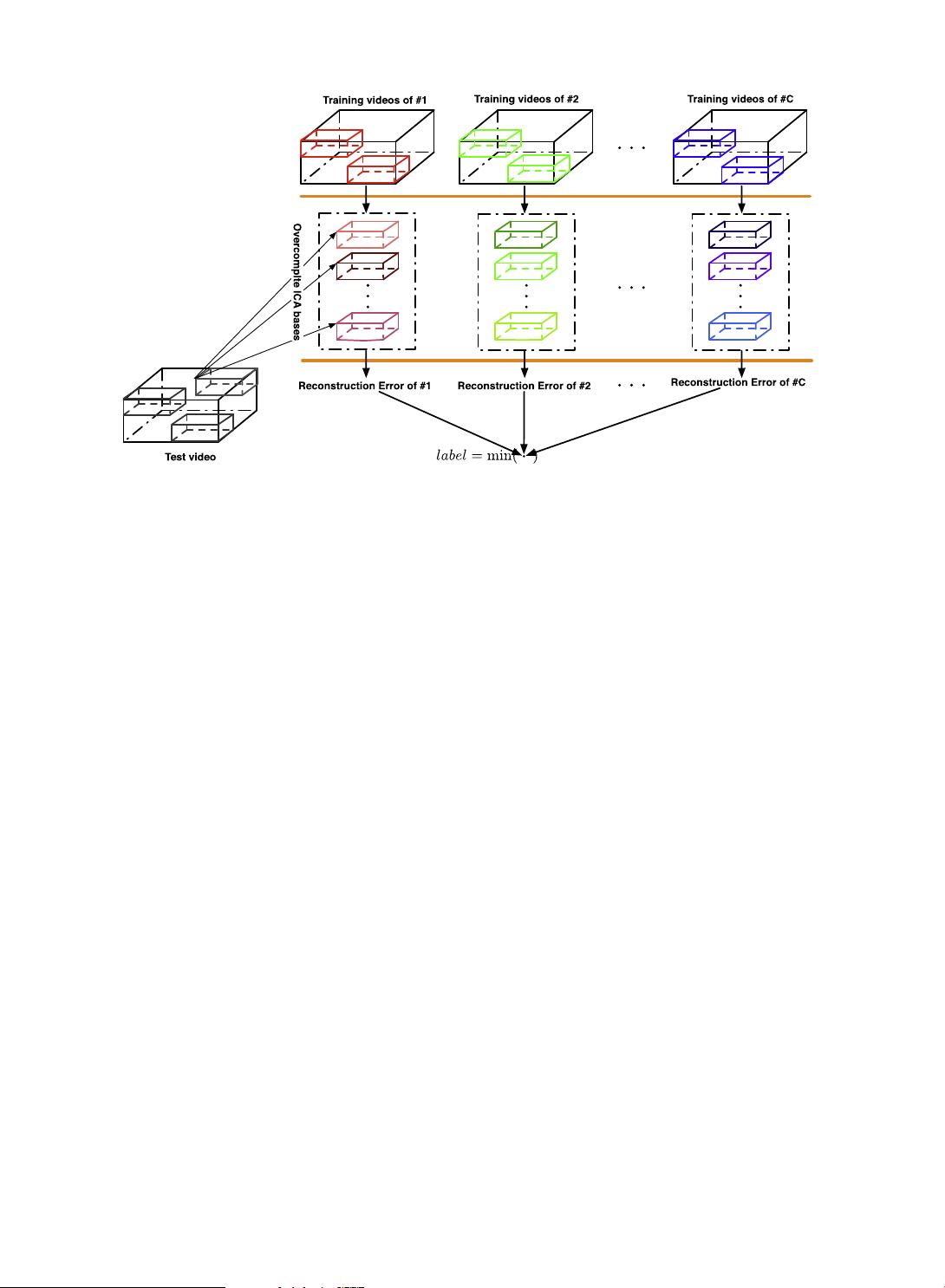
The proposed action recognition framework based on overcomplete ICA is illustrated in Fig. 1. At the training stage, after
densely sampling a set of 3D patches from training videos of each class, a set of overcomplete ICA basis functions are learned.
Fig. 1. A conceptual diagram of the proposed action recognition framework.
S. Zhang et al. / Information Sciences 281 (2014) 635–647
637
剩余12页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-20 上传
2011-03-15 上传
2021-02-09 上传
2021-02-09 上传
2019-08-16 上传
2021-02-07 上传

等你下课⊙▽⊙
- 粉丝: 291
- 资源: 962
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
