Java实现堆排序算法详解
版权申诉
11 浏览量
更新于2024-08-07
收藏 67KB DOCX 举报
"java的选择排序之堆排序"
堆排序是一种高效的排序算法,它的基本思想是将待排序的序列构建成一个大顶堆(或小顶堆),使得堆顶元素(最大值或最小值)总是位于序列的起始位置。然后通过交换堆顶元素与末尾元素并重新调整堆的过程,逐步将无序序列转换为有序序列。
在堆排序的过程中,大顶堆的特点是每个父节点的值都大于或等于其子节点的值。用数组表示时,如果i是父节点的位置,则其左子节点为2i+1,右子节点为2i+2,且满足条件arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]。相反,小顶堆则是每个父节点的值小于或等于其子节点的值,满足arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]。
堆排序的基本步骤如下:
1. 构建初始堆:从最后一个非叶子节点(即数组长度除以2减1的下标处)开始,自底向上调整每个节点,确保其满足大顶堆或小顶堆的性质。这个过程通常被称为heapify或调整堆。
2. 交换堆顶元素与末尾元素:将最大值(大顶堆)或最小值(小顶堆)与末尾元素交换,然后将末尾元素剔除,此时末尾元素即为排序后的最大值或最小值。
3. 重新调整堆:对剩余的n-1个元素再次进行堆化操作。
4. 重复步骤2和3,直到堆的大小为1,此时整个序列已经按照升序或降序排列完成。
在给出的代码示例中,`HeapSort`类包含了一个`heapSort`方法,该方法实现了堆排序的逻辑。首先,通过一个循环生成一个包含8000000个随机整数的数组,然后调用`heapSort`方法对数组进行排序。在排序过程中,`adjustHeap`方法用于调整堆,确保堆的性质。在排序完成后,计算并输出排序所需的时间,从而评估算法的效率。
堆排序的时间复杂度在最坏、最好和平均情况下都是O(nlogn),这使得它在处理大数据量时具有较好的性能。然而,由于堆排序不是稳定的排序算法,相同元素的相对顺序可能会在排序后改变。此外,堆排序在原地排序,不需要额外的存储空间,这是它的一个优点。
总结来说,堆排序是一种基于堆数据结构的排序算法,通过构建和调整堆来达到排序的目的,其时间复杂度为O(nlogn),适用于大规模数据的排序,但不保证稳定性。
说明
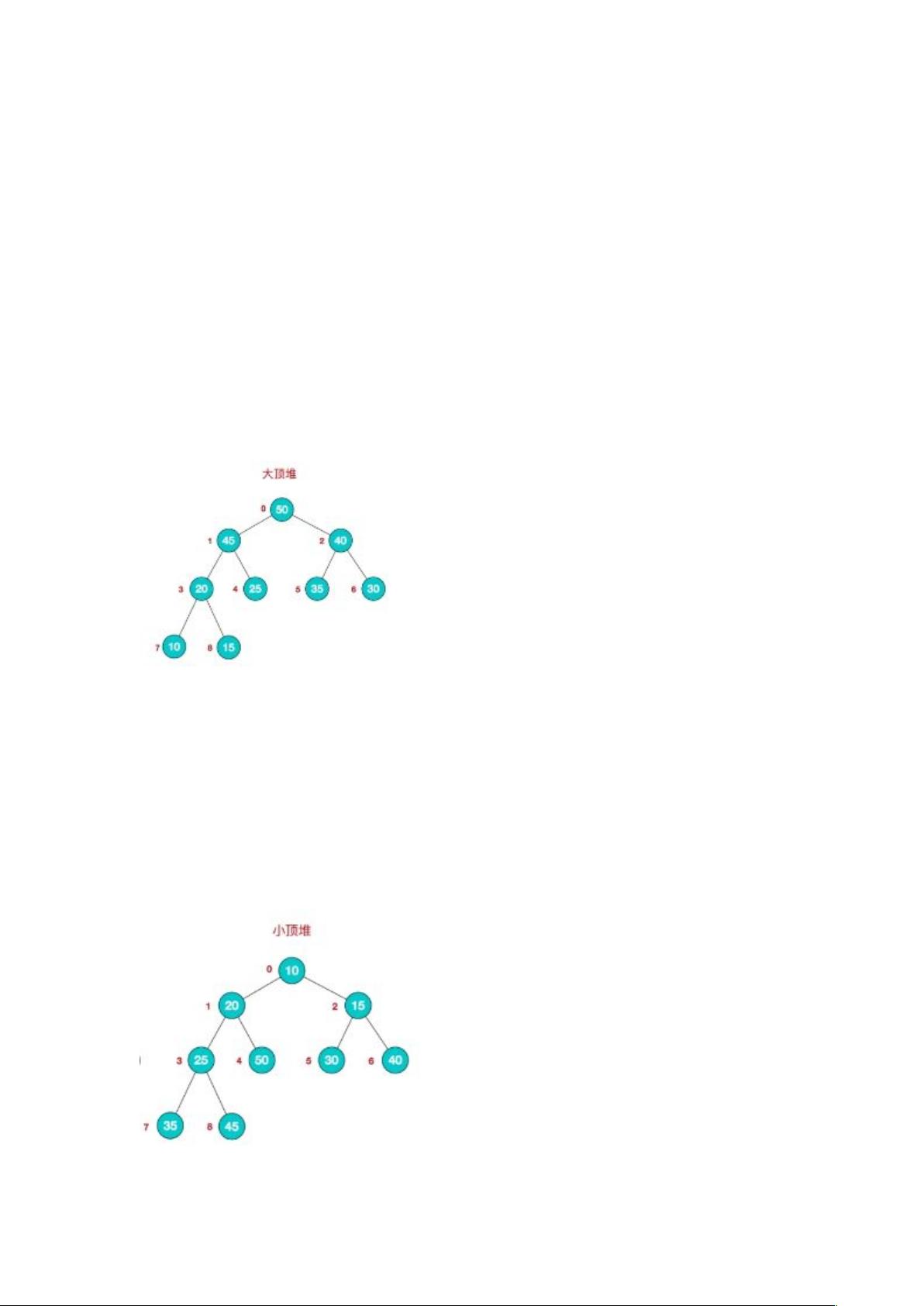
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选
择排序,它的最坏,最好,平均时间复杂度均为 O(nlogn),它也是不稳
定排序。
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩
子结点的值,称为大顶堆
大顶堆特点:arr[i] >= arr[2 _i+1] && arr[i] >= arr[2_i+2]
i 对应第几个节点,i 从 0 开始编号
注意 : 没有要求结点的左孩子的值和右孩子的值的大小关系。
每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
小顶堆特点:arr[i] <= arr[2 _i+1] && arr[i] <= arr[2_i+2]
i 对应第几个节点,i 从 0 开始编号
下载后可阅读完整内容,剩余3页未读,立即下载
2021-09-30 上传
123 浏览量
158 浏览量
129 浏览量
2022-11-26 上传
101 浏览量
183 浏览量
2022-02-07 上传

小兔子平安
- 粉丝: 271
 我的内容管理
展开
我的内容管理
展开







最新资源
- ITween插件实用教程:路径运动与应用案例
- React三纤维动态渐变背景应用程序开发指南
- 使用Office组件实现WinForm下Word文档合并功能
- RS232串口驱动:Z-TEK转接头兼容性验证
- 昆仑通态MCGS西门子CP443-1以太网驱动详解
- 同步流密码实验研究报告与实现分析
- Android高级应用开发教程与实践案例解析
- 深入解读ISO-26262汽车电子功能安全国标版
- Udemy Rails课程实践:开发财务跟踪器应用
- BIG-IP LTM配置详解及虚拟服务器管理手册
- BB FlashBack Pro 2.7.6软件深度体验分享
- Java版Google Map Api调用样例程序演示
- 探索设计工具与材料弹性特性:模量与泊松比
- JAGS-PHP:一款PHP实现的Gemini协议服务器
- 自定义线性布局WidgetDemo简易教程
- 奥迪A5双门轿跑SolidWorks模型下载
