数据科学复习:从预处理到模型应用详解
需积分: 5 87 浏览量
更新于2024-06-22
2
收藏 4.44MB PDF 举报
数据科学复习总结涵盖了多个关键知识点,包括基础统计学习方法、数据预处理、模型构建与评估以及机器学习的核心流程。以下是对这些内容的详细说明:
1. **代码片段:** 学习者将通过实践来熟悉线性回归建模,如使用Python的scikit-learn库进行一元线性回归。这涉及到数据导入、特征选择、模型训练和预测,例如上述的`LinearRegression`类的使用。
2. **逻辑回归和朴素贝叶斯分类:** 学习者会接触到分类任务,如红酒数据分类,以及高斯朴素贝叶斯分类,这是基于概率论的简单但强大的分类方法,常用于文本分类和垃圾邮件过滤等场景。
3. **多顶式朴素贝叶斯分类:** 这里可能指的是多项式朴素贝叶斯模型,适用于离散特征,如文档分类问题。
4. **实际应用:** 用朴素贝叶斯模型处理实际问题,如分析北京市空气质量数据,这需要对数据的理解和模型预测结果的解读。
5. **在线作业平台:** 提供了`http://172.30.211.4/assignment/index.jsp`的学习资源,可能包含更多的编程练习和理论测试。
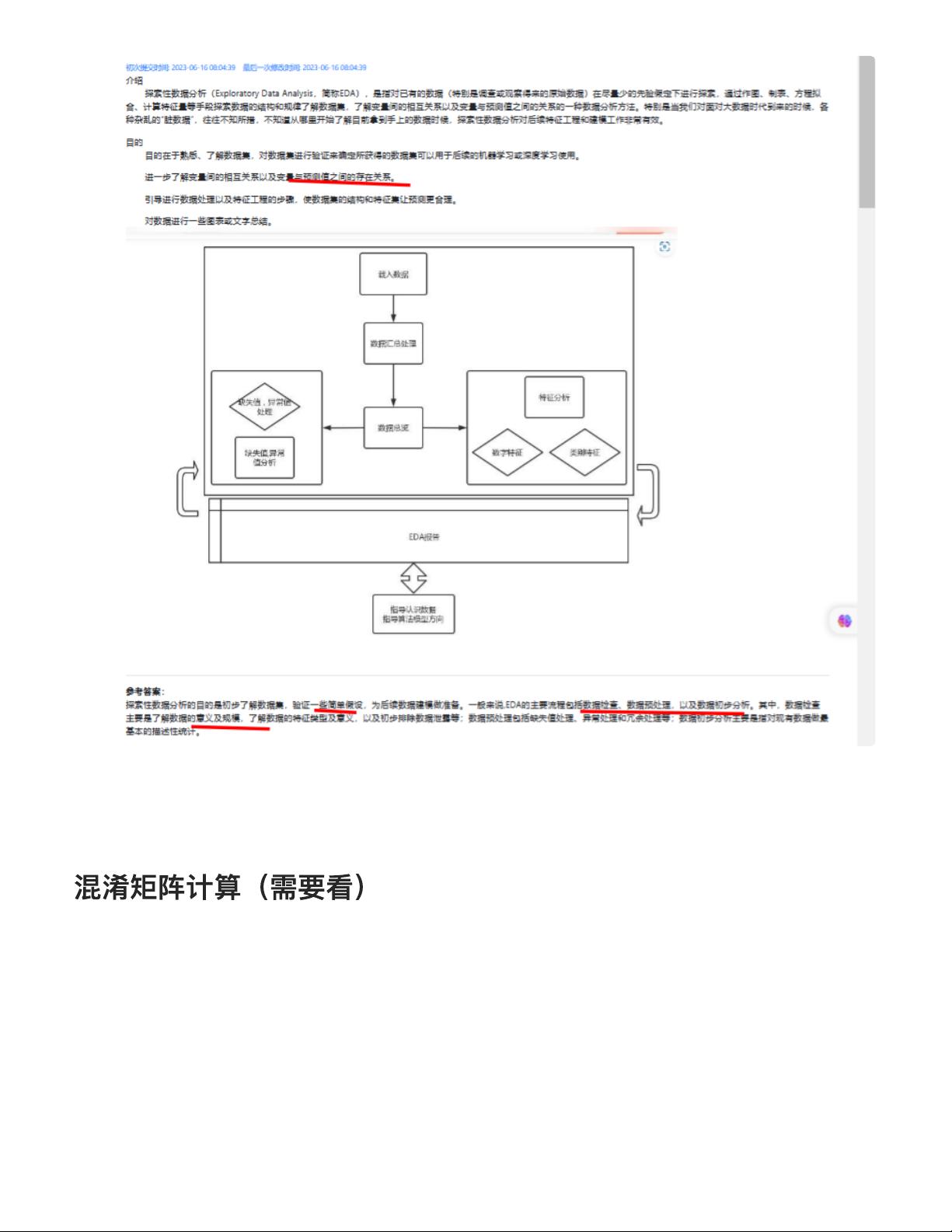
6. **数据预处理和探索性数据分析(EDA):** 这部分强调了在建模前清理和理解数据的重要性,通过可视化和统计分析来发现数据的结构和潜在关系。
7. **聚类方法:** 包括k-means聚类,学习者需掌握其步骤,如初始化质心、迭代更新、评估算法性能等,以及理解其与分类的区别。
8. **评估指标:** 如混淆矩阵的计算,用于模型性能的定量评估,以及K折交叉验证,确保模型泛化能力的提高。
9. **K-means算法和K折交叉验证:** K-means迭代过程,以及K折交叉验证的步骤和目的,是为了防止过拟合,提高模型在未知数据上的表现。
10. **机器学习步骤概述:** 通常包括数据收集、预处理、特征工程、模型选择、训练、验证、调整和部署等环节。
11. **一元线性回归求解:** 描述了模型如何通过最小二乘法拟合数据,以及如何用数学公式理解权重和截距的意义。
12. **抽样偏差:** 概念介绍,它反映了样本与总体之间的差异,是评估样本代表性的关键概念。
13. **基尼系数:** 作为不确定性度量,基尼系数解释了数据的不平等程度,越接近1表示不确定性越高,反之越低。
14. **实战编程:** 从数据预处理到线性回归模型的完整流程,包括数据清洗、特征工程、模型训练及预测。
15. **多元线性回归案例:** 使用`crime.csv`数据集,探讨如何预测盗窃案件的数量,展示了模型在实际问题中的应用。
16. **数据加载和分析:** 使用pandas库读取和操作CSV数据,为后续分析奠定基础。
17. **数据加载示例的继续:** 继续处理crime_data,可能是进一步的分析或模型开发。
这份复习总结涵盖了从基础统计到高级机器学习模型的各个方面,旨在帮助学习者系统地掌握数据科学的核心概念和技术。
6
混淆
矩
阵
计
算
(
需
要
看
)
剩余29页未读,继续阅读
122 浏览量
308 浏览量
499 浏览量
2023-12-27 上传
187 浏览量
904 浏览量
1390 浏览量
2022-07-17 上传

哈都婆
- 粉丝: 2213
- 资源: 36
 我的内容管理
展开
我的内容管理
展开







最新资源
- 《LINUX与UNIX SHELL编程指南》读书笔记
- DELL MD3000 软件安装配置
- 程序设计模式解说 - 追MM版
- ASP.NET中数据库的使用实训指导.pdf
- SELinux usage guide
- spring+hibernate+struts的配置整和
- ansys技巧全集(很好的ansys技巧 英文版) 很多书上都没有的技巧
- wavecom 模块常用AT指令手册.pdf
- HTTP协议中文版.pdf
- 汽车测距预警及险警系统结构与设计研究
- iReport使用手册
- 中国移动代理服务器(MAS)设备规范.doc
- 转发:嵌入式视频处理基本原理
- MS SQL全库导入oracle
- jbpm中文入门指南
- core java I 笔记
