优化Hive:存储与运行性能提升的关键技术突破
需积分: 9 46 浏览量
更新于2024-09-15
收藏 478KB PDF 举报
Apache Hive 是一个广泛应用于 Apache Hadoop 的数据仓库系统,由于其在大数据分析领域的广泛采用,许多组织都将其作为关键工具。然而,随着处理的数据量不断增长,对 Hive 在文件格式、查询规划和执行效率方面的需求也在增加。本文重点关注 Hive 的主要技术改进,特别是针对存储性能和运行时性能的优化。
首先,关于存储性能,文章提出了一项重要目标:通过更新文件格式来最大化有效存储容量和加速数据访问。Hive 的ORCFile(Optimized Row Columnar)格式被提及,这是一种高效的数据存储方式,它利用列式存储和压缩技术,能够显著减少磁盘I/O,提高读写速度。ORCFile 提供了更紧凑的数据表示,减少了存储空间占用,并且优化了查询性能,特别是在涉及大量数据扫描的场景下。
其次,文章讨论了查询规划方面的技术提升。查询优化是影响 Hive 性能的关键因素,因为优化器负责决定如何执行 SQL 查询以达到最高效的资源使用。在这篇论文中,可能探讨了新的查询优化算法、索引策略的改进以及与分布式计算框架的协同优化,以减少不必要的计算和数据传输,从而提高查询响应时间。
此外,查询执行效率也是关注的重点。可能介绍了对 MapReduce 或 Spark 等计算模型的优化,以及如何更好地利用多核处理器和分布式内存,以提升任务并行性和并发性。这可能包括了执行引擎的改进,如减少不必要的数据复制,以及缓存策略的优化,以降低磁盘 I/O 和网络延迟。
最后,为了满足处理大规模数据的持续需求,文章可能还涵盖了实时处理和流处理能力的增强,使 Hive 能够处理更复杂的数据流作业。这可能涉及到了对 Hive Streaming 或者实时数据加载机制的扩展,使得用户能够更灵活地处理实时数据和批处理数据。
总结来说,这篇论文围绕 Apache Hive 的主要技术进步,聚焦于存储和运行时性能的提升,重点介绍的是 ORCFile 文件格式的优化、查询优化技术、执行效率改进以及对实时处理能力的支持,这些改进旨在提升 Hive 在大数据时代中的竞争力和适应性。通过这些技术创新,Hive 有望更好地服务于日益增长的数据处理需求。
row manner, rows have more entropy, which make them hard to be
densely compressed. In Hive 0.4, Record Columnar File (RCFile)
[27] was introduced. Because RCFile is a columnar file format,
it achieved certain improvement on storage efficiency. However,
RCFile is still data-type-agnostic and its corresponding SerDe se-
rializes a single row at a time. Under this structure, data-type spe-
cific compression schemes cannot be effectively used. Thus, the
first key shortcoming of Hive on storage efficien cy is that data-
type-agnostic file formats and one-row-at-a-time serialization
prevent data values being efficiently compressed.
The query execution performance is largely determined by the
file format component, the query planning component (the query
planner), and the query execution component containing imple-
mentation of operators. Although RCFile is a columnar file for-
mat, its SerDe does not decompose a complex data type (e.g. Map).
Thus, when a query needs to access a fiel d of a complex data type,
all fields of this type have to be read, which introduces inefficiency
on data reading. Also, R CFile was mainly designed for sequential
data scan. It does not have any index and it does not take advantages
of semantic information provided by queries to skip unnecessary
data. Thus, the second key shortcoming of the file format com-
ponent is that data reading efficiency is limited by the lack of
indexes and non-decomposed columns with complex data types.
The query planner in the original Hive translates every operation
specified in this query to an operator. When an operation requires
its input datasets to be partitioned in a certain way
2
, Hive will in-
sert RSOps as the boundary between a Map phase and a Reduce
phase. Then, the query planner will break the entire operator tr ee
to MapReduce jobs based on these boundaries. During query plan-
ning and optimization, the planner only focuses on a single data
operation or a si ngle MapReduce job at a time. This query plan-
ning approach can significantly degrade t he query execution per-
formance by introducing unnecessary and time consuming opera-
tions. For example, t he original query planner was not aware of
correlations between major operations in a query [
31]. Thus, the
third key shortcoming of the query planner is that the query
translation approach ignores relationships between data oper-
ations, and thus introduces unnecessary operations hurting the
performance of query execution.
The query execution component of Hive was heavily influenced
by the working model of Hadoop MapReduce. In a Map or a Re-
duce task, the MapReduce engine fetches a key/value pair and then
forwards it to the Map or Reduce function at a time. For example,
in the case of word count, every Map task processes a line of a text
file at a time. Hive inherited this working model and it processes
rows with a one-row-at-a-time way. However, this working model
does not fit the architecture of modern CPUs and introduces high
interpretation overhead, under-utilized parallelism, low cache per-
formance, and high function call overhead [
19] [35] [50]. Thus,
the fourth key shortcoming of the query execution component
is that the runtime execution efficiency is limited by the one-
row-at-a-time execution model.
4. FILE FORMAT
To address the shortcoming of the storage and data access effi-
ciency, we have designed and implemented an improved file for-
mat called Optimized Record Columnar File (ORC File)
3
which
2
In the rest of this paper, this kind of data operations are called
major operations and an operator evaluating a major operation is
called a major operator.
3
In the rest of this paper, we use ORC File to refer to the file format
we introduced and we use an ORC file or ORC files to refer to one
or multiple fil es stored in HDFS with the format of ORC Fil e.
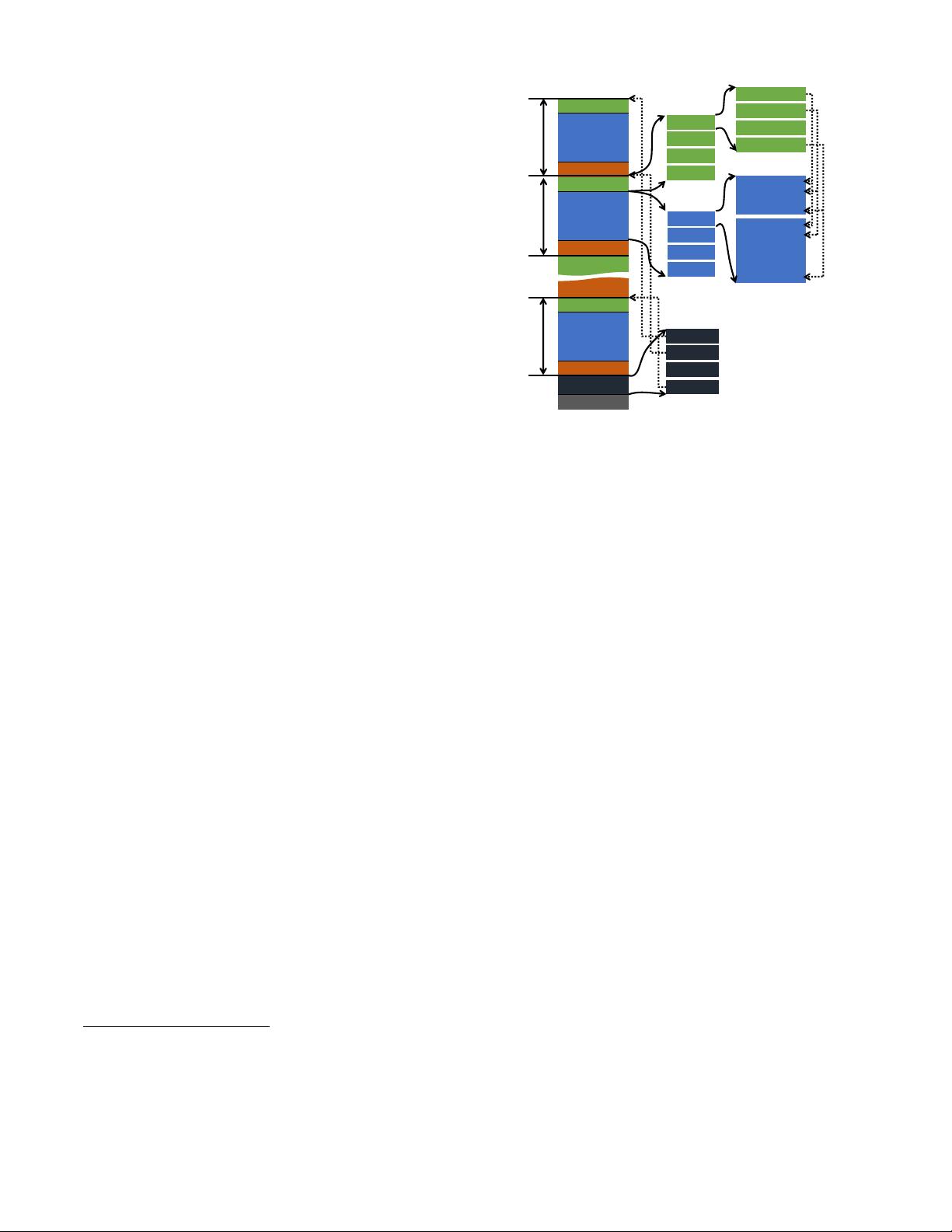
Index Data
Row Data
Stripe Footer
Index Data
Row Data
Stripe Footer
Index Data
Row Data
Stripe Footer
File Footer
Postscript
^ƚƌŝƉĞϭ^ƚƌŝƉĞϮ
^ƚƌŝƉĞŶ
Column 1
Column 2
Column m
…
Column 1
Column 2
Column m
…
Stripe 1
Stripe 2
Stripe n
…
Metadata
Streams
Data Stream
Row index 1
Row index 2
Row index k
…
Figure 2: The structure of an ORC file. Round-dotted lines
represent position pointers.
has several significant improvements over RCFile. In ORC File,
we have de-emphasized its SerDe and made the ORC file writer
data type aware. With this change, we are able to add various
type-specific data encoding schemes to store data efficiently. To
efficiently access data stored with ORC File, we have introduced
different kinds of indexes that do not exist in RCFile. Those in-
dexes are critical to help the ORC reader find needed data and skip
unnecessary data. Also, because the ORC writer is aware of the
data type of a value, it can decompose a column with a complex
data type (e.g. Map) to multiple child columns, which cannot be
done by RC File. Besides these three major improvements, we also
have introduced several practical improvements in ORC File, e.g.
a larger default stripe size and a memory manager to bound the
memory footprint of an ORC writer, aiming to overcome inconve-
nience and inefficiency we have observed through years’ operation
of RCFile.
In this section, we give an overview of ORC File and its im-
provements over RCFile. First, we introduce the way that ORC
File organizes and stores data values of a table (table placement
method). Then, we introduce i ndexes and compression schemes in
ORC File. Finally, we introduce the memory manager in ORC File,
which is a critical and yet often ignored component. This memory
manager bounds the total memory footprint of a task writing ORC
files. It can prevent the task from failing caused by running out of
memory. Figure
2 shows the structure of an ORC file. We will use
it to explain the design of O RC File.
4.1 The Table Placement Method
When a table is stored by a file format, the table placement
method of this file format describes t he way that data values of this
table are organized and stored in underlying filesystems. Based
on the definition in [
28], the table placement method of ORC File
shares the basic structure with that of RCFile. For a table stored in
an ORC file, it is first horizontally partitioned to multiple stripes.
Then, in a stripe, data values are stored in a column by column way.
All columns in a stripe are stored in the same file. Also, to be adap-
tive to different query patterns, especially ad hoc queries, O RC File
does not put columns into column groups.
From the perspective of the table placement method, ORC File
has three improvements over RCFile. First, it provides a larger de-
剩余11页未读,继续阅读
118 浏览量
168 浏览量
点击了解资源详情
107 浏览量
120 浏览量
2024-06-28 上传
189 浏览量
2021-10-14 上传
2021-10-14 上传

frankliu6948
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- DWR中文教程:快速入门与实践指南
- Struts验证机制深度解析
- ArcIMS客户端选择指南:连接器与Viewer解析
- Spring AOP深度解析与实战
- 深入理解Hibernate查询语言HQL
- 改进遗传算法在智能组卷中的应用研究
- Hibernate 3.2.2官方教程:入门与基础配置
- Spring官方参考手册2.0.8版:IoC容器与AOP增强
- ABAP初学者指南:函数与关键功能解析
- ABAP实例详解:报表与对话程序结构与应用
- SAP SmartForm创建实例与测试教程
- JavaScript从入门到精通教程
- .NET 2.0时间跟踪系统设计与实现
- C++标准库教程与参考:Nicolai Josuttis著
- 项目管理流程与项目经理的关键能力
- B/S模式电子购物超市管理系统设计与实现
