实时数据处理与流计算技术详解:Spark、Storm等实践应用
需积分: 9 90 浏览量
更新于2024-07-19
3
收藏 3.66MB PDF 举报
《Streaming.Data.2017.5.pdf》是一本深度讲解实时数据处理的实用教程,作者是Andrew G. Psaltis。本书的核心内容围绕着如何有效地与快速流动的数据交互,提供了丰富的实例和应用案例,帮助读者理解和设计处理实时数据的应用程序。它涵盖了从数据读取、分析到分享和存储的全链条设计。
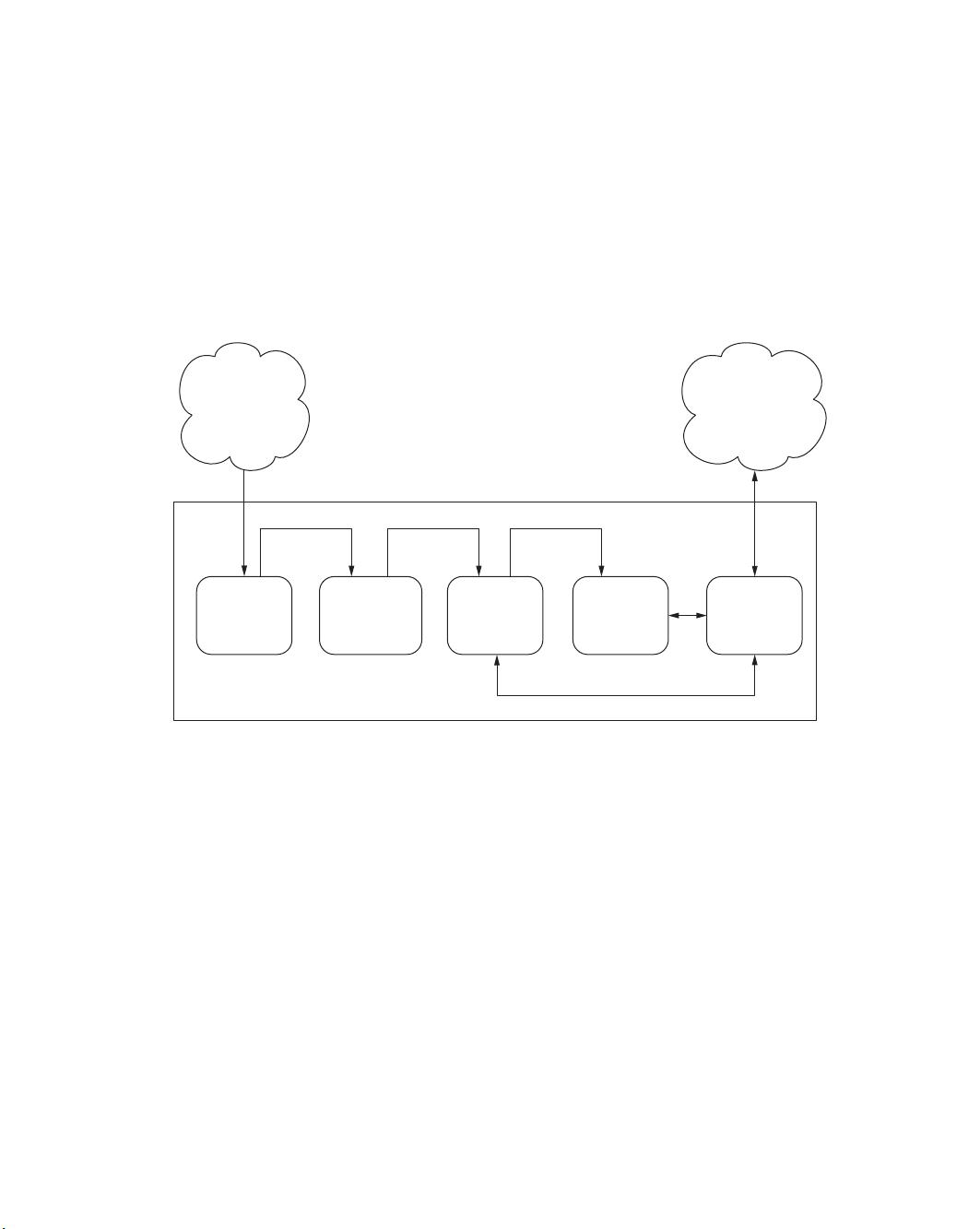
首先,"实时数据管道"这一章节将引导读者理解实时数据处理的关键架构。在这个过程中,读者会了解到Spark、Storm、Kafka、Flink等关键技术在处理流式数据中的角色。这些技术在数据的实时处理中起着至关重要的作用,如Spark用于大规模数据处理,Storm负责实时事件驱动计算,而Kafka则作为消息队列,确保数据的可靠传输。
其次,书中强调了长期存储的重要性。即使分析后得到的数据有时需要持久化,以便在未来查询或进一步利用。例如,浏览器、移动设备、自动售货机等场景中,可能需要回溯历史分析结果。因此,一个包含内存数据存储和长期数据存储的多层次结构被提出,这包括内存在线存储用于快速访问,以及用于长期存储和备份的持久化层。
分析阶段是数据处理的核心环节,书中介绍了构建分析-tier,用于深度挖掘和实时分析数据。这个层次不仅涉及实时计算,还可能涉及到机器学习算法,以提取有价值的信息。
除了分析,消息队列-tier(如RabbitMQ)也是不可或缺的,它确保了数据的有序传递,即使在系统负载变化时也能维持数据的实时性。
最后,数据访问-tier关注的是如何高效地访问和检索处理后的数据,这对于提供实时服务至关重要。这可能包括数据库优化,缓存策略,或者API设计,以支持多种客户端应用程序的访问。
尽管本书并未深入探讨所有细节,但读者可以从中获得对实时数据处理的整体框架和实践方法有深入的理解。对于那些希望通过实践掌握实时数据处理技术的人来说,这是一本非常有价值的参考资料。同时,读者还能了解到Manning出版社提供的购买优惠和服务联系方式,以及版权声明。《Streaming.Data.2017.5.pdf》是一本既具有理论深度又兼顾实践指导的实时数据处理指南。

ACKNOWLEDGMENTS
xiv
John Guthrie, Kosmas Chatzimichalis, Giuliano Bertoti, Carlos Curotto, Andy Kirsch,
Douglas Duncan, Jeff Smith, and Sergio Fernández González, Jaromir D.B. Nemec,
Jose Samonte, Jan Nonnen, Romit Singhai, Chris Allan, Jonathan Thoms, Steven Jenkins,
Lee Gilbert, Amandeep Khurana, Charlie Gaines. Without all of you, this book wouldn’t
be what it is today.
Many others contributed in various different ways. I can’t mention everyone by
name because the acknowledgments would just roll on and on, but a big thank you
goes out to everyone else who had a hand in helping make this possible!



剩余218页未读,继续阅读
176 浏览量
540 浏览量
2021-08-31 上传
356 浏览量
点击了解资源详情
2025-03-13 上传
2025-03-13 上传

xinconan2
- 粉丝: 269
 我的内容管理
展开
我的内容管理
展开







最新资源
- Linux平台PSO服务器管理工具集:简化安装与维护
- Swift仿百度加载动画组件BaiduLoading
- 传智播客C#十三季完整教程下载揭秘
- 深入解析Inter汇编架构及其基本原理
- PHP实现QQ群聊天发言数统计工具 v1.0
- 实用AVR驱动集:IIC、红外与无线模块
- 基于ASP.NET C#的学生学籍管理系统设计与开发
- BEdita Manager:官方BEdita4 API网络后台管理应用入门指南
- 一天掌握MySQL学习笔记及实操练习
- Sybase数据库安装全程图解教程
- Service与Activity通信机制及MyBinder类实现
- Vue级联选择器数据源:全国省市区json文件
- Swift实现自定义Reveal动画播放器效果
- 仿53KF在线客服系统源码发布-多用户版及SQL版
- 利用Android手机实现远程监视系统
- Vue集成UEditor实现双向数据绑定
