深度学习:Xavier初始化在深度前馈网络中的应用解析
版权申诉
174 浏览量
更新于2024-08-04
收藏 476KB PDF 举报
"本文深入探讨了深度前馈网络的反向传播过程和Xavier初始化原理,适合对机器学习和AI有深入了解的读者。"
深度前馈网络(Deep Feedforward Network)是一种基本的神经网络架构,其中数据沿单向传递,从输入层通过隐藏层直至输出层。这种网络的核心组成部分是线性映射和非线性激活函数,这两者共同构建了网络的复杂性。
线性映射是每一层与下一层之间的连接,由权重矩阵表示。每个神经元的输出是输入与权重的乘积之和,即线性组合。非线性激活函数如Sigmoid、ReLU或Tanh则引入非线性,使网络能够学习更复杂的模式。
在反向传播过程中,误差从输出层向输入层反向传播,用于更新权重。这一过程基于链式法则和梯度下降,使得网络能根据预测错误调整权重。对于某层神经元,假设其输入为z,经过激活函数f1得到输出a。如果z是另一层的输出(通常由线性映射函数f2产生,即z=f2(x)),则在求梯度时,只需乘以f1的导数,即可忽略激活函数之后的影响,仅关注当前层及之前的变量。
对于线性层,其函数形式为f2(x)=w\cdot x,当误差反向传播至此,只需乘以权重w来继续传播。这个过程在深度网络中不断重复,通过乘以激活函数的导数和权重,逐步计算各层的梯度。
Xavier初始化,由Glorot和Bengio在2010年提出,是为了解决深度网络中梯度消失或爆炸的问题。该方法建议权重初始化的均值接近于0,方差根据输入和输出神经元的数量进行调整。具体来说,权重w的初始化应遵循以下公式:
\[
Var(w) = \frac{2}{n_{in} + n_{out}}
\]
其中,\(n_{in}\)是输入节点数,\(n_{out}\)是输出节点数。这样,初始化的权重既不会导致前几层的输出过于压缩(导致梯度消失),也不会过于放大(导致梯度爆炸),从而有利于训练过程的稳定进行。
除了Xavier初始化,还有其他初始化策略,如He初始化,特别适用于ReLU激活函数,它考虑了ReLU的非零导数期望,进一步优化了权重初始化。这些初始化技巧对于深度学习模型的训练至关重要,它们可以帮助网络更快地收敛,提高学习效果。
深度前馈网络的反向传播和Xavier初始化是理解神经网络优化和训练的关键概念。掌握这些原理有助于构建和训练更高效、更稳定的深度学习模型。在实际应用中,结合其他工程技巧,如正则化、优化算法和批量归一化,可以进一步提升模型的性能。
深度前馈⽹络与Xavier初始化原理
原创
⼣⼩瑶
2017-07-17⼣⼩瑶的卖萌屋
来⾃专辑
卖萌屋@深度学习炼丹技巧
基本的神经⽹络的知识(⼀般化模型、前向计算、反向传播及其本质、激活函数等)⼩⼣已经介绍完毕,本⽂先讲
⼀下深度前馈⽹络的BP过程,再基于此来重点讲解在前馈⽹络中⽤来初始化model参数的Xavier⽅法的原理。
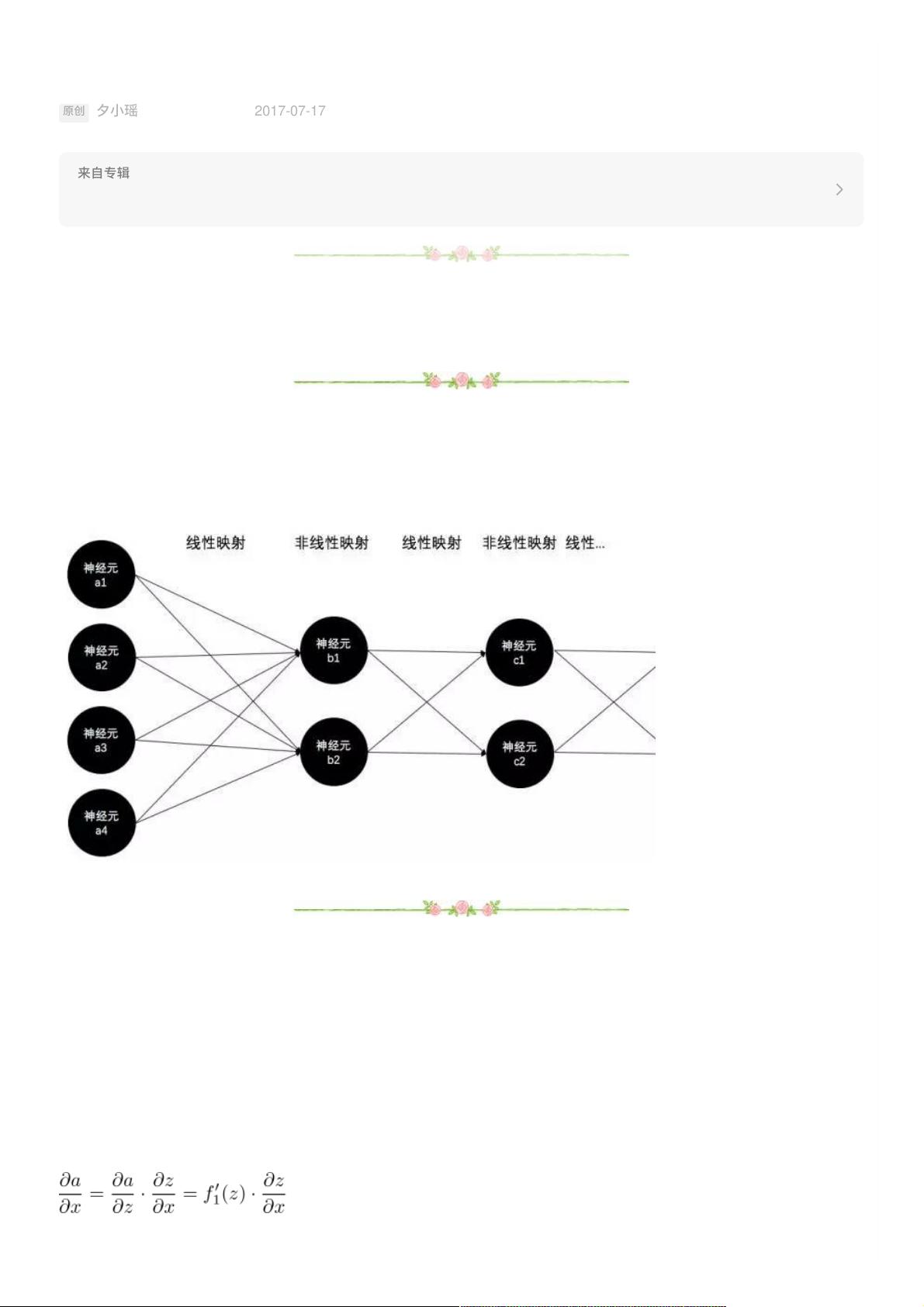
前向过程很简单,每⼀层与下⼀层的连接边(即参数)构成了⼀个矩阵(即线性映射),每⼀层的神经元构成⼀个激活函
数阵列(即⾮线性映射),信号便从输⼊层开始反复的重复这两个过程直到输出层,也就是已经在《神经⽹络激活
函数》中详细讲过的线性与⾮线性交替映射的过程:
误差反向传播的过程也很简单,其本质就是基于链式求导+梯度下降,原因已在《BP算法的本质》中讲解,这⾥就
重点讲解⼀下BP算法的过程。
⾸先往上翻⼀翻,记住之前说过的前馈⽹络⽆⾮就是反复的线性与⾮线性映射。然后:
⾸先,假设某个神经元的输⼊为z,经过激活函数f1(·)得到输出a。即函数值a=f1(z)。如果这⾥的输⼊z⼜是另⼀个函
数f2的输出的话(当然啦,这⾥的f2就是线性映射函数,也就是连接某两层的权重矩阵),即z=f2(x),那么如果基于
a来对z中的变量x求导的时候,由于
显然只要乘以激活函数f1的导数,就不⽤操⼼激活函数的输出以及更后⾯的事⼉了(这⾥的“后⾯”指的是神经⽹络的
下载后可阅读完整内容,剩余3页未读,立即下载
2023-10-18 上传
2022-04-13 上传
2021-09-25 上传
2021-09-24 上传
2021-09-25 上传
2021-09-25 上传
2021-09-27 上传

普通网友
- 粉丝: 1272
- 资源: 5619
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
