"YOLO目标检测模型结构横向对比及应用分析"
需积分: 41 162 浏览量
更新于2023-12-28
3
收藏 2.15MB PPTX 举报
目标检测是计算机视觉领域的重要任务,其主要目的是在图像或视频中识别并定位物体。在目标检测领域,YOLO(You Only Look Once)系列模型是一系列经典的单阶段目标检测模型。本文将对YOLOv1~v7模型进行结构剖析,并进行横向对比,探讨其优势和局限性,以及模型的发展与优化。
首先,我们要了解什么是单阶段目标检测模型。单阶段模型指的是在一个网络中同时完成目标的识别和定位,而不需要额外的候选区域生成或者边框回归。YOLOv1和YOLOv2模型作为经典的单阶段目标检测模型,其主干网络构造采用了卷积和池化操作,用于提取图片的抽象特征;损失函数构造包括对位置和类别的置信度进行预测。这些模型的设计使得其在目标检测任务中取得了良好的性能。
其次,我们将YOLO模型的发展与优化以主干网络、Neck、Head三个方面展开来进行横向对比。YOLOv3和YOLOv4在主干网络的设计上进行了优化,引入了残差连接和特征金字塔网络,提高了模型对目标的检测精度;Neck和Head的设计也得到了改进,进一步提升了模型的性能。这表明随着模型的不断发展与优化,YOLO系列模型在目标检测任务中的表现也在不断提升。
接下来,我们将YOLO模型应用到汽车检测、烟雾识别等领域,分析其优点和局限性。YOLO模型具有较高的检测精度和较快的检测速度,适合于实时目标检测任务;然而,由于模型结构的限制,其在小目标检测和目标遮挡方面仍存在局限性。针对这些局限性,我们可以加入一些方法对模型进行优化,如引入注意力机制、多尺度融合等技术,来提升模型在特定场景下的性能。
综上所述,基于YOLO系列模型的目标检测方法在区域提取和回归两种技术上有所不同。回归方法不需要先划定目标候选区,因此具有较好的实时性能;而区域提取方法则能够得到较好的检测精度。针对烟雾检测任务,基于回归的检测方法更能满足实时性的要求,而基于区域提取的检测方法则可以得到更好的精度。
在YOLOv1模型中,其主干网络为由若干卷积层和池化层组成的隐藏层,全连接层用来预测目标的位置和类别概率值。而YOLOv1的损失函数设计包括对位置和类别的置信度进行预测。此外,在YOLOv1中,通过对VOC数据集的实验,我们展示了模型输出的预测结果。
然而,随着YOLO模型的不断发展,其主干网络、Neck、Head等部分的设计和优化也在不断进行。在YOLOv3和YOLOv4中,引入了残差连接和特征金字塔网络等技术,提高了模型对目标的检测精度,并进一步提升了模型的性能。此外,YOLOv3和YOLOv4在模型的设计上也有了一些改进,使得模型在小目标检测和目标遮挡方面取得了更好的表现。
在实际的汽车检测、烟雾识别等领域的应用中,YOLO模型具有较高的检测精度和较快的检测速度,适合于实时目标检测任务。然而,由于模型结构的限制,其在小目标检测和目标遮挡方面仍存在局限性。为了克服这些局限性,可以加入一些方法对模型进行优化,比如引入注意力机制、多尺度融合等技术,来提升模型在特定场景下的性能。这些方法的引入可以进一步提高模型的检测精度和对小目标的检测能力。
综上所述,YOLOv1~v7模型在目标检测领域取得了较好的表现,但在不同的应用场景中仍存在一些局限性。随着模型的不断发展和优化,我们相信YOLO系列模型在未来会在目标检测领域取得更好的性能,为实际应用场景提供更加高效和准确的目标检测解决方案。
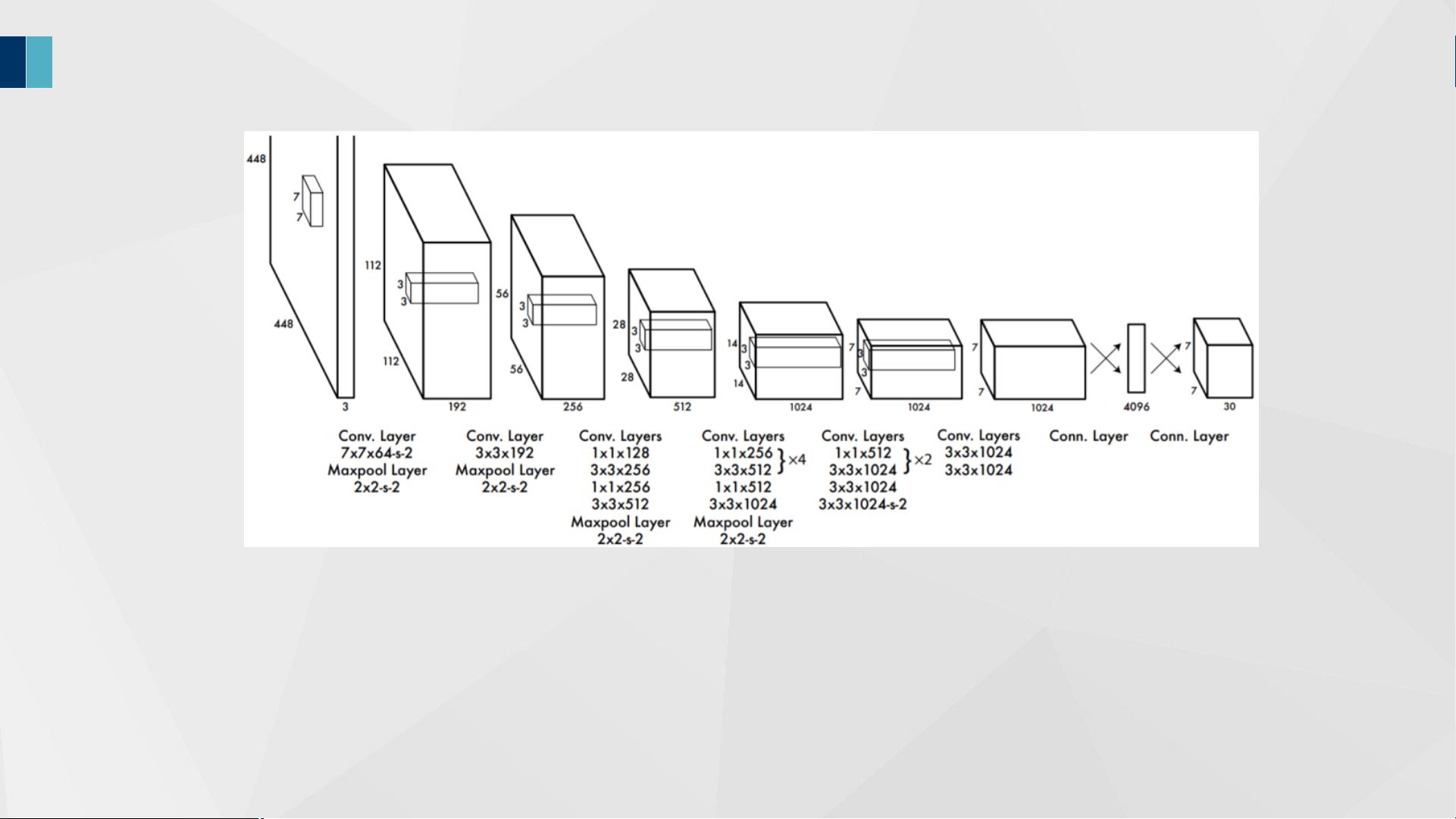
1. YOLOv1-主干网络
2
网络输入:448×448×3的彩色图片
隐藏层:由若干卷积层和池化层组成,用于提取图片的抽象特征
全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值
网络输出:得到7×7×30的预测结果
图1YOLOv1主干网络
剩余16页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-26 上传
2024-07-20 上传
2022-08-02 上传
2023-05-20 上传
2022-11-17 上传
2024-07-21 上传









