Python使用pdfkit将ipynb转换为PDF教程
121 浏览量
更新于2024-08-29
1
收藏 406KB PDF 举报
本文主要介绍了如何使用Python将IPython Notebook(ipynb)文件转换成PDF格式,适合需要分享或打印Jupyter Notebook内容的情况。在过程中遇到了错误,但通过使用HTML作为中间转换格式,借助pdfkit库实现了转换目标。
在Jupyter Notebook中编写课件或者报告是一种高效的方式,因为它的Markdown支持和内建的Python执行环境。然而,对于非开发者或者不熟悉ipynb格式的人来说,直接提供这种文件并不方便。PDF格式则更易于阅读和分享,因此将ipynb转换成PDF成为了一个需求。
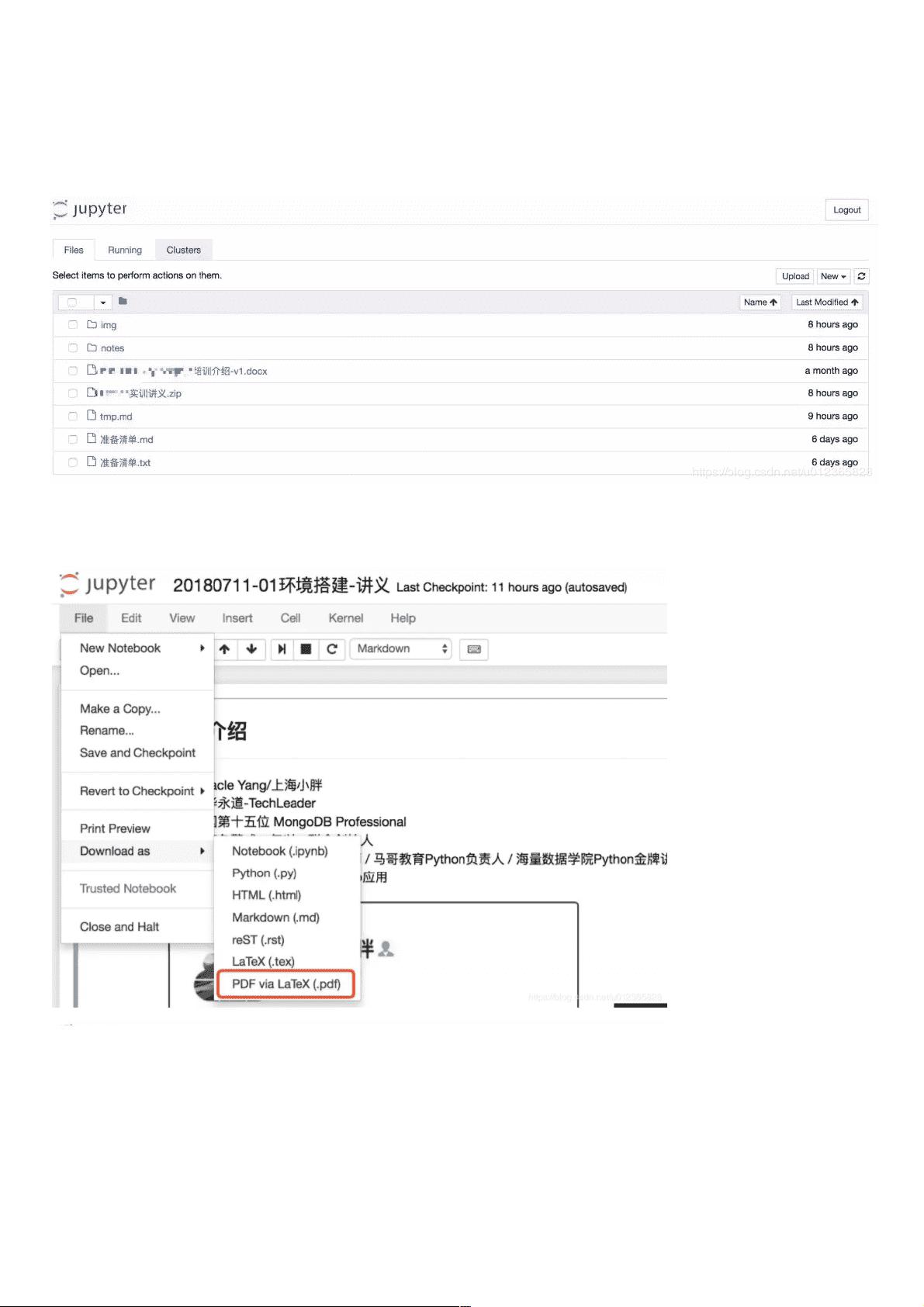
首先,作者尝试直接从Jupyter Notebook下载为PDF,但遇到了错误。解决这个问题的一个常见建议是安装LaTeX环境,但这可能会占用大量磁盘空间。为了避免这种情况,作者选择了一个替代方案,即通过HTML转换为PDF。
Python的pdfkit库被用于这个目的。pdfkit能够将HTML页面转换为PDF,它依赖于wkhtmltopdf工具,这是一个轻量级的网页渲染引擎。用户需要先下载并安装适用于自己操作系统的wkhtmltopdf二进制文件,然后通过pip安装pdfkit库。
转换过程的Python代码如下:
```python
import nbformat
from IPython.display import display, HTML
import pdfkit
# 读取ipynb文件
with open('example.ipynb', 'r') as f:
notebook = nbformat.read(f, as_version=4)
# 将notebook转换为HTML字符串
html = HTML(str(nbformat.v4.writes(notebook)))
# 使用pdfkit将HTML转换为PDF
pdfkit.from_string(html, 'output.pdf')
```
这段代码首先读取ipynb文件,将其转换为HTML字符串,然后使用pdfkit将这个HTML字符串转换为PDF文件,最终的PDF文件名为'output.pdf'。
此外,文章还提到了其他与PDF处理相关的Python教程,如提取PDF表格数据、提取PDF内容、处理PDF文件、以及利用Python进行PDF的其他操作,如分割、合并和文字提取等。这些教程可以帮助读者进一步了解Python在PDF处理方面的应用。
这篇文章提供了一个实用的解决方案,让Jupyter Notebook的用户可以轻松地将他们的工作转化为更通用的PDF格式,便于分享和打印。同时,也展示了Python生态系统中的工具如何简化跨格式转换任务。
python把把ipynb文件转换成文件转换成pdf文件过程详解文件过程详解
这两天一直在做课件,我个人一直不太喜欢PPT这个东西……能不用就不用,我个人特别崇尚极简风。
谁让我们是程序员呢,所以就爱上了Jupyter写课件,讲道理markdown也是个非常不错的写书格式啊。
安装Jupyter其实非常简单,你会python就应该会用jupyter,起码简单的 pip install jupyter, jupyter notebook 要会对伐~
好那接下来就是使用jupyter了,启动jupyter后,使用浏览器访问相应IP:Port就可以使用了。没错,jupyter就是这么一个可以用网站来写python的地方。
但是发讲义给同学们看,ipynb格式的文件肯定不方便啊,别人还没上课呢,哪知道那么多?再者PDF传阅起来也随时随地能打开啊。所以我就想转换成
PDF。
但是打开文件,点击下载,发现出现了Error
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-03-09 上传
2779 浏览量
499 浏览量
点击了解资源详情
1023 浏览量
点击了解资源详情

weixin_38585666
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- STM32系列单片机 sms模拟器实验教程
- Flutter计时器应用开发入门教程
- category-explorer: 用JavaScript递归构建类别树形结构
- WindowBuilder Pro 2:Eclipse插件下的Java GUI设计神器
- 混凝土配合比施工参考手册软件发布
- 易修改型CPA网站诱惑源码快速部署指南
- Ralink 3070无线网卡驱动安装及使用指南
- Webapp如何管理议会问题的工作流程详解
- Mac 10.7.2 黑苹果安装利器 - OSInstall+OSInstall.mpkg
- Next.js框架简单演示及其优势解析
- STM32-F系列单片机电子-SMS项目压缩包
- C# IP输入组件:规范IP地址输入工具的使用与集成
- Java技术栈微信小程序商城后端与前端开发详解
- C++实现作业与进程调度模拟教程
- JavaScript选择API及范围选择示例分析
- React-Native动画通知发送实现指南
