大规模数据挖掘:局部敏感哈希解决文档相似性搜索
185 浏览量
更新于2024-07-14
收藏 1.95MB PDF 举报
理论与应用:局部敏感哈希(Locality-Sensitive Hashing, LSH)在大规模数据挖掘中的关键角色
在斯坦福大学的计算机科学课程CS246《挖掘海量数据》中,Jure Leskovec教授探讨了如何处理大规模文档集合中的一个核心问题:在数百万甚至数十亿的文档中寻找"近似重复"内容。这个任务对于诸如构建镜像网站、避免搜索结果中显示重复内容以及在互联网内容管理和去重等方面具有重要意义。
在面对海量文档时,面临的主要挑战包括:
1. **文档碎片化**:即使是来自同一文档的小片段,在另一个文档中可能由于顺序不同而显得不匹配。
2. **计算复杂性**:由于文档数量巨大,直接比较所有文档对是不可行的,这会导致时间和空间效率低下。
3. **存储限制**:有些文档可能体积庞大,无法一次性加载到内存中进行处理。
为了解决这些问题,研究人员提出了几种方法:
**1. Shingling**(碎词法):将文档转换为固定长度的子串(k-shingles),每个文档被表示为这些子串的集合,便于后续处理。
**2. Min-Hashing**:通过创建简短的签名(signature),保留文档之间的相似性。它寻找一个哈希函数,该函数满足Pr[hπ(C1) = hπ(C2)]等于文档C1和C2的Jaccard相似度。Min-Hash恰好具备这样的性质,使得相似文档的哈希值有更高的概率相等。
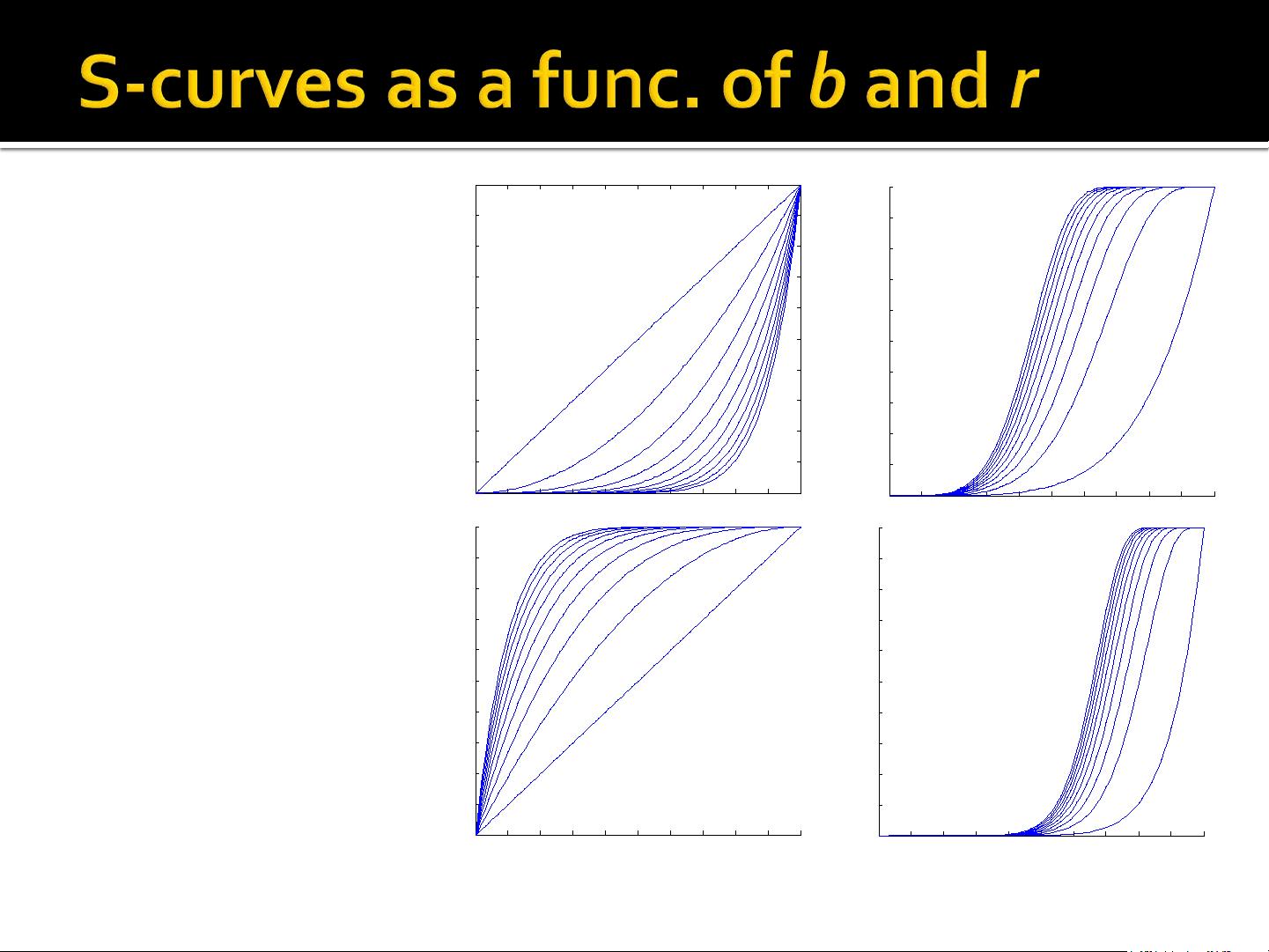
**3. 局部敏感哈希(LSH)**:LSH的重点在于针对可能来自相似文档的签名对进行更精确的聚焦。这种方法通过将签名划分为若干带,并分别进行哈希,相似的文档签名更有可能被映射到同一个哈希桶,从而形成潜在的候选对。
LSH的优势在于其对相似文档的碰撞概率较高,同时降低了计算复杂性。通过分组和哈希操作,即使在大规模数据集中,也能有效地缩小搜索范围,找出那些虽然细节上存在差异但整体相似的文档。这种技术在搜索引擎优化、图像搜索和社交网络分析等领域有着广泛应用,有助于提高系统的性能和用户体验。

Remember: b bands, r rows/band
Let sim(C
1
, C
2
) = t
Pick some band (r rows)
Prob. that elements in a single row of
columns C
1
and C
2
are equal = t
Prob. that all rows in a band are equal = t
r
Prob. that some row in a band is not equal = 1 - t
r
Prob. that all bands are not equal = (1 - t
r
)
b
Prob. that at least 1 band is equal = 1 - (1 - t
r
)
b
1/14/2015 Jure Leskovec, Stanford C246: Mining Massive Datasets 9
Similarity t
P(C
1
, C
2
is a
candidate pair)
P(C
1
, C
2
is a candidate pair) = 1 - (1 - t
r
)
b

剩余51页未读,继续阅读
2020-10-08 上传
2024-06-02 上传
2021-05-06 上传
2021-04-23 上传
2021-04-27 上传
2021-05-08 上传
2021-02-07 上传
2023-06-28 上传

weixin_38652636
- 粉丝: 6
- 资源: 896
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
