深度学习中的稀疏自编码器与DNN应用
下载需积分: 50 | PPT格式 | 3.1MB |
更新于2024-07-09
| 146 浏览量 | 举报
"本文主要探讨了在人工智能领域,特别是深度学习中的DNN(深度神经网络)及其相关概念,包括误差目标函数、传播项以及稀疏自编码器的应用。"
在原BP(Backpropagation)网络的误差目标函数及传播项是深度学习中的一种基本计算方法。误差传播项描述了在网络中如何通过反向传播算法来调整权重,以减小预测输出与实际目标之间的误差。这一过程是训练神经网络的关键,通过梯度下降等优化算法更新权重,以最小化损失函数,使网络预测更加准确。
稀疏自编码器(Sparse Auto-Encoder)是一种特殊的自编码器,它引入了稀疏性约束,即限制隐藏层神经元的激活程度,使得网络在无监督学习中能学习到输入数据的紧凑表示。自编码器试图学习一个近似于恒等函数的映射,使得输出尽可能接近输入。当网络的隐藏层神经元数量少于输入层时,网络必须从较少的特征中重构输入,这有助于发现数据中的潜在结构。例如,对于图像数据,自编码器可以学习到一种类似于主元分析(PCA)的低维表示,揭示输入数据的相关性和模式。
深度学习(Deep Learning)是近年来人工智能领域的一个热点,因其在语音识别、图像识别等任务中的优秀表现而受到广泛关注。深度学习的核心在于多层非线性处理单元的组合,形成深层神经网络,模仿人脑的分层信息处理机制。通过自动学习多层次的抽象特征,深度学习解决了传统机器学习中手动特征工程的难题。
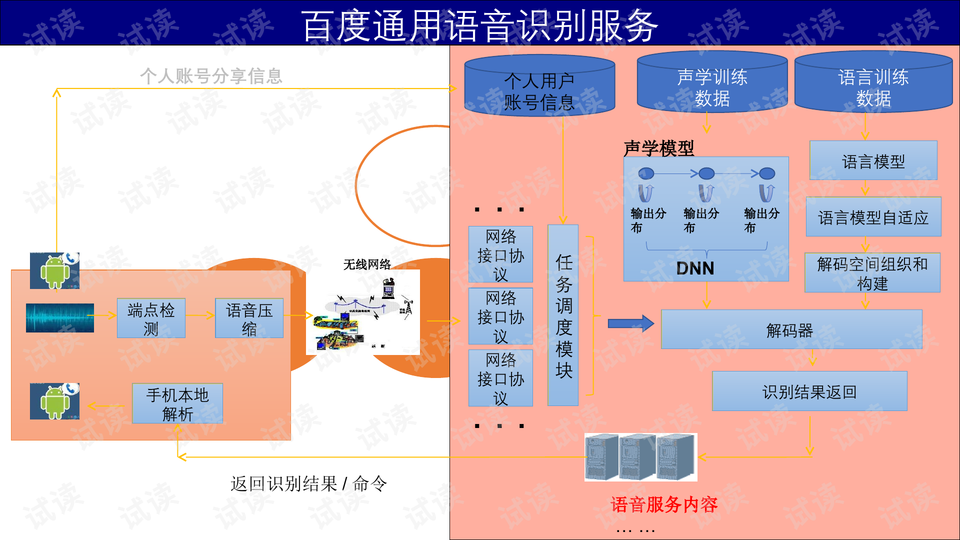
以深度神经网络(DNN)为基础的语音识别服务,如示例中提到的百度通用语音识别,通常包含声学模型、语言模型和解码器等组件。声学模型利用DNN处理声学特征,语言模型则用于理解上下文,解码器根据前两者的输出生成识别结果。DNN在此过程中起到了关键作用,通过大量数据训练,自动学习到有效的特征表示,提高了识别的准确性和效率。
深度学习的兴起与大数据的可用性密切相关,互联网公司如Google、微软和百度等纷纷投入资源进行研发。由于深度学习能够自动从原始数据中学习高级特征,减少了对人工特征工程的依赖,因此在许多机器学习问题上展现出强大的性能和潜力。然而,尽管深度学习取得了显著成果,但它仍然面临挑战,如训练的计算复杂性、过拟合问题以及对大量标注数据的依赖等。尽管如此,深度学习的不断发展正在推动人工智能领域的持续创新。
下载后可阅读完整内容,剩余24页未读,立即下载
相关推荐

清风杏田家居
- 粉丝: 24
 我的内容管理
展开
我的内容管理
展开








最新资源
- 咖喱技术:实现Haskell与Rust的互操作
- 深入理解面向对象编程设计原则
- HTML压缩技术:NirvanaAche.ajkt8j4ngr.gaqaNxP方法解析
- Laravel中使用Twilio实现电话号码验证的教程
- TensorFlow 2.0深度应用:Python文本处理库
- 深入探究SkupChik项目:Lua语言的应用与发展
- Docpress:从Markdown到静态网站的便捷转换工具
- MATLAB实现LFM调频连续波雷达仿真及多目标分析
- 微前端架构实践:qiankunJS结合Vue与Vite的应用与挑战
- Flask-LazyViews:优化Flask URL路由注册方法
- 掌握浏览器端事件监听:使用js-on库
- React 应用开发入门指南及脚本使用
- 实现带滚动条和预览图的相册切换特效教程
- 双时间尺度更新规则在GANs训练中的应用
- 探索TurtleBot3:全方位应用程序与ROS软件包介绍
- NStack:数据分析中的类型安全、微服务组合解决方案
