Apache Spark与Hadoop开发者培训教程
需积分: 5 130 浏览量
更新于2024-07-09
收藏 11.32MB PDF 举报
"Developer Training for Apache Spark and Hadoop 是一份深度学习资料,涵盖了Apache Spark和Hadoop的基础到高级知识,适合开发人员进行大数据处理技术的学习。这份材料详细讲解了Hadoop生态系统、Spark基础、DataFrame与Schema操作、RDD处理、SQL查询、Dataset使用、Spark分布式处理、持久化数据、结构化流处理以及与Apache Kafka的集成等内容。"
**Apache Hadoop与生态系统**
Apache Hadoop是开源的大数据处理框架,主要由HDFS(Hadoop Distributed File System)和MapReduce组成。HDFS提供了高容错性的分布式存储,而MapReduce则用于大规模数据集的并行计算。Hadoop生态系统包括多个组件,如YARN(资源调度器)、HBase(NoSQL数据库)、Hive(数据仓库工具)等,它们共同构成了一个强大的大数据处理环境。
**Apache Spark基础知识**
Apache Spark是快速、通用的分布式计算系统,设计目标是提供比Hadoop MapReduce更高效的计算模型。Spark的核心概念是弹性分布式数据集(RDD),它是一种可编程的、容错的数据结构。此外,Spark引入了DataFrame和Dataset,它们提供了更加高级且易用的数据操作接口,简化了数据分析流程。
**DataFrame与Schemas**
DataFrame是Spark SQL中的一个重要概念,它是表格型数据的抽象,支持丰富的SQL查询和转换。DataFrame可以自动推断或指定模式(Schema),提供了面向列的操作,使得处理结构化数据更加便捷。
**RDD操作**
RDD是Spark的基本构建块,代表了一组不可变、分区的记录集合。通过转换(Transformation)和动作(Action)操作,开发者可以在分布式集群上对RDD进行计算。转换操作不会立即执行,而是创建一个新的RDD,而动作操作会触发实际的计算。
**Spark SQL与查询**
Spark SQL提供了与SQL兼容的接口,允许用户通过SQL查询DataFrame。这对于那些熟悉SQL语法的开发者来说,降低了学习曲线,同时提高了工作效率。
**Distributed Processing与数据持久化**
Spark的分布式处理能力使得它能高效地处理大量数据。数据持久化机制允许RDD在内存中缓存,以加速后续计算。多种持久化级别可供选择,以平衡性能和容错性。
**Structured Streaming与Apache Kafka集成**
Structured Streaming是Spark的流处理框架,提供了一种声明式编程模型,支持连续的数据处理。Apache Kafka是一个实时消息队列系统,常用于数据流的生产与消费。将Structured Streaming与Kafka结合,可以实现高效的数据流处理和实时分析。
**Aggregating and Joining Streaming DataFrames**
在处理流数据时,聚合(Aggregation)和连接(Join)操作是常见的数据处理任务。Structured Streaming支持对流数据进行实时聚合和连接,以便进行复杂的实时分析。
通过这份培训资料,开发者将能够深入理解Spark和Hadoop的工作原理,并掌握如何在实际项目中运用这些技术进行大数据处理。
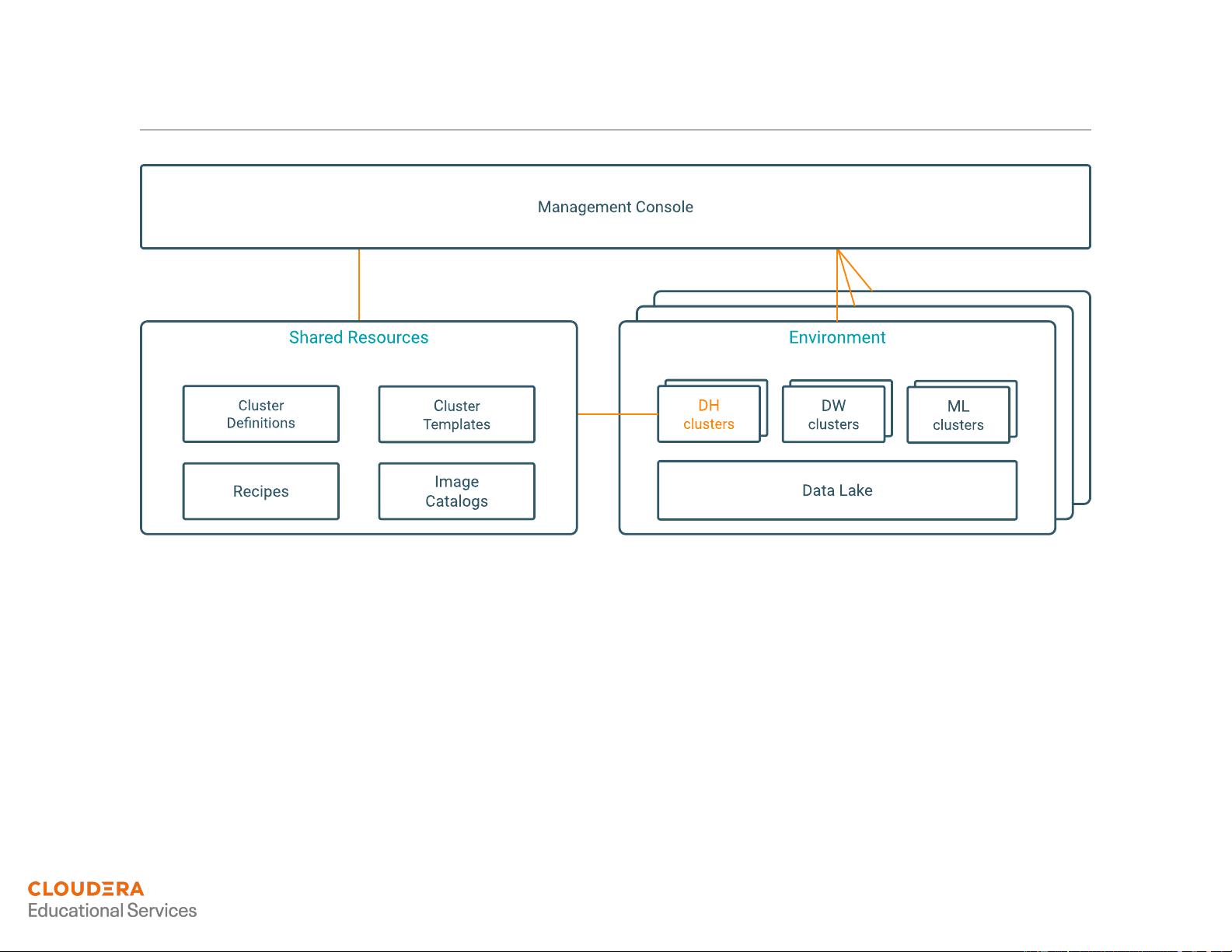
Cloudera Data Hub
Customize your own experience in cloud form factors
▪
Integrated suite of analytic engines
▪
Cloudera SDX applies consistent security and governance
▪
Fueled by open source innovation
Copyright © 2010–2020 Cloudera. All rights reserved. Not to be reproduced or shared without prior written consent from Cloudera.
01-15


剩余673页未读,继续阅读
2021-11-14 上传
2017-01-13 上传
2018-03-01 上传
2023-12-01 上传
2023-04-26 上传
2023-03-31 上传
2023-04-26 上传
2023-05-27 上传
2023-05-20 上传


柏冉看世界
- 粉丝: 1074
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
