MetaPruning:元学习驱动的自动神经网络通道剪枝优化
需积分: 37 100 浏览量
更新于2024-09-06
1
收藏 4.39MB PDF 举报
MetaPruning是一种创新的元学习方法,针对深度神经网络的自动通道剪枝问题提出了全新的解决方案。该论文的核心是设计并训练一个名为PruningNet的元模型,其功能是在给定目标网络架构的基础上,自动生成适用于各种剪枝结构的权重参数。这种元学习策略允许对深度神经网络进行高效且精确的剪枝,减少了在搜索过程中对网络结构微调的需求。
在MetaPruning的实现过程中,研究人员采用了一种简单但有效的随机结构采样方法对PruningNet进行训练。这种方法旨在让PruningNet能够理解和学习如何适应不同的剪枝策略,从而生成具有优秀性能的子网络。通过这个进化过程,搜索过程变得高效,因为生成权重的过程已经由PruningNet完成,无需在搜索阶段进行额外的调整。
MetaPruning的一大优势在于它的灵活性和易用性。一旦为目标网络训练好PruningNet,就可以在很少的人工干预下,针对不同的约束条件(如计算资源、内存需求或模型大小)搜索出一系列性能优良的剪枝网络。这不仅降低了人工操作的工作量,还使得模型压缩过程更加自动化和通用。
与当前最先进的剪枝技术相比,MetaPruning在MobileNet V1/V2和ResNet等常见的深度学习模型上展现了显著的优势。这表明MetaPruning在保持模型性能的同时,成功地实现了模型的轻量化,对于在移动设备和资源受限环境中部署深度学习模型具有重要的实际价值。
MetaPruning作为一种基于元学习的自动神经网络通道剪枝方法,提供了一种有效且可扩展的途径,使得深度学习模型能够在不牺牲太多性能的前提下,达到更小的模型尺寸和更低的计算开销,从而推动了模型压缩领域的研究进展。
MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning
Zechun Liu
1
Haoyuan Mu
2
Xiangyu Zhang
3
Zichao Guo
3
Xin Yang
4
Tim Kwang-Ting Cheng
1
Jian Sun
3
1
Hong Kong University of Science and Technology
2
Tsinghua University
3
Megvii Technology
4
Huazhong University of Science and Technology
Abstract
In this paper, we propose a novel meta learning ap-
proach for automatic channel pruning of very deep neural
networks. We first train a PruningNet, a kind of meta net-
work, which is able to generate weight parameters for any
pruned structure given the target network. We use a sim-
ple stochastic structure sampling method for training the
PruningNet. Then, we apply an evolutionary procedure to
search for good-performing pruned networks. The search is
highly efficient because the weights are directly generated
by the trained PruningNet and we do not need any fine-
tuning at search time. With a single PruningNet trained
for the target network, we can search for various Pruned
Networks under different constraints with little human par-
ticipation. Compared to the state-of-the-art pruning meth-
ods, we have demonstrated superior performances on Mo-
bileNet V1/V2 and ResNet. Codes are available on https:
//github.com/liuzechun/MetaPruning.
1. Introduction
Channel pruning has been recognized as an effective
neural network compression/acceleration method [32, 22, 2,
3, 21, 52] and is widely used in the industry. A typical prun-
ing approach contains three stages: training a large over-
parameterized network, pruning the less-important weights
or channels, finetuning or re-training the pruned network.
The second stage is the key. It usually performs iterative
layer-wise pruning and fast finetuning or weight reconstruc-
tion to retain the accuracy [17, 1, 33, 41].
Conventional channel pruning methods mainly rely
on data-driven sparsity constraints [28, 35], or human-
designed policies [22, 32, 40, 25, 38, 2]. Recent AutoML-
style works automatically prune channels in an iterative
mode, based on a feedback loop [52] or reinforcement
learning [21]. Compared with the conventional pruning
This work is done when Zechun Liu and Haoyuan Mu are interns at
Megvii Technology.
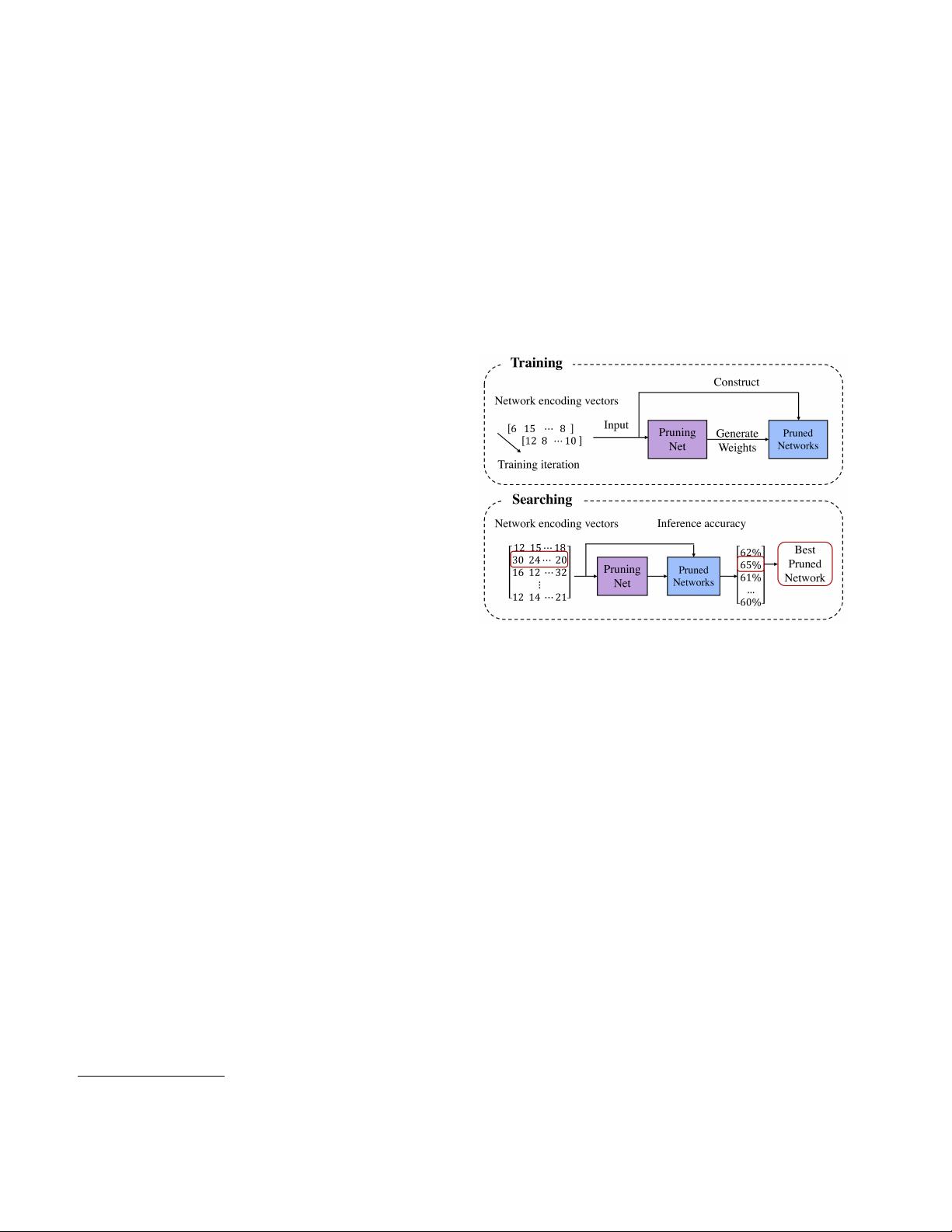
Figure 1. Our MetaPruning has two steps. 1) training a Prun-
ingNet. At each iteration, a network encoding vector (i.e., the
number of channels in each layer) is randomly generated. The
Pruned Network is constructed accordingly. The PruningNet takes
the network encoding vector as input and generates the weights
for the Pruned Network. 2) searching for the best Pruned Net-
work. We construct many Pruned Networks by varying network
encoding vector and evaluate their goodness on the validation data
with the weights predicted by the PruningNet. No finetuning or
re-training is needed at search time.
methods, the AutoML methods save human efforts and can
optimize the direct metrics like the hardware latency.
Apart from the idea of keeping the important weights in
the pruned network, a recent study [36] finds that the pruned
network can achieve the same accuracy no matter it inher-
its the weights in the original network or not. This finding
suggests that the essence of channel pruning is finding good
pruning structure - layer-wise channel numbers.
However, exhaustively finding the optimal pruning struc-
ture is computationally prohibitive. Considering a network
with 10 layers and each layer contains 32 channels. The
possible combination of layer-wise channel numbers could
be 32
10
. Inspired by the recent Neural Architecture Search
(NAS), specifically One-Shot model [5], as well as the
weight prediction mechanism in HyperNetwork [15], we
arXiv:1903.10258v3 [cs.CV] 14 Aug 2019
下载后可阅读完整内容,剩余9页未读,立即下载
2020-03-10 上传
2022-07-13 上传
2020-02-23 上传
2019-08-23 上传
2018-04-12 上传
2009-04-23 上传

librahfacebook
- 粉丝: 198
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
