




无命题时间动作检测:全局分割模板学习新方法
PDF格式 | 1.51MB |
更新于2024-06-18
| 150 浏览量 | 举报
“基于全局分割模板学习的无命题时间动作检测”
在时间动作检测(Temporal Action Detection,TACT)领域,当前的方法通常依赖于为每个视频生成大量的动作建议,然后对这些建议进行处理以识别动作的起始和结束时间。然而,这种依赖建议的方式导致了复杂的模型设计和高昂的计算成本。为了克服这一问题,研究者们首次提出了一种无需建议的检测模型,称为全局分割模板学习(Global Segment Masking,简称TAGS)。TAGS的核心理念是在整个视频时序上联合学习每个动作实例的全局分割掩模,从而直接检测动作的起点和终点。
与传统基于建议的方法相比,TAGS模型聚焦于全局时间表示的学习,能够直接检测和定位动作实例,而无需先生成建议。这种方法简化了模型架构,降低了计算成本。大量实验结果显示,尽管TAGS模型设计简洁,但它在两个基准测试中超越了现有方法,实现了新的最先进的性能。而且,TAGS模型的训练速度比其他方法快20倍,推理速度提升100倍,提高了效率。其PyTorch实现可供研究人员使用,可从https://github.com/sauradip/TAGS访问。
现有的TACT方法如锚定方法,通常基于预定义的锚框或者直接预测建议的开始和结束时间来生成动作提案。这些方法以单个建议为中心,对每个提案进行时间和类别的精细化分析。然而,这种方法存在的问题是需要大量的提案以确保良好的检测效果,例如,BMN算法通过详尽的开始点和结束点配对为每个视频生成500个提案。
TAGS模型的创新之处在于其整体建模策略,它避免了对单个建议的逐个处理,而是考虑全局视频上下文,以更高效的方式检测动作实例。这种方法减少了计算资源的需求,使得在不牺牲性能的情况下,能够快速训练和推理,这对于实时应用和大规模视频数据处理至关重要。
基于全局分割模板学习的无命题时间动作检测为解决TACT中的计算效率和复杂性问题提供了一个新颖且有效的方法。未来的研究可能将探索如何进一步优化TAGS模型,以适应更多样化的视频内容和更复杂的场景,同时保持其高效性和准确性。
+v:mala2255获取更多论
文
∈
∈
S
s
S
4 Nag等人。
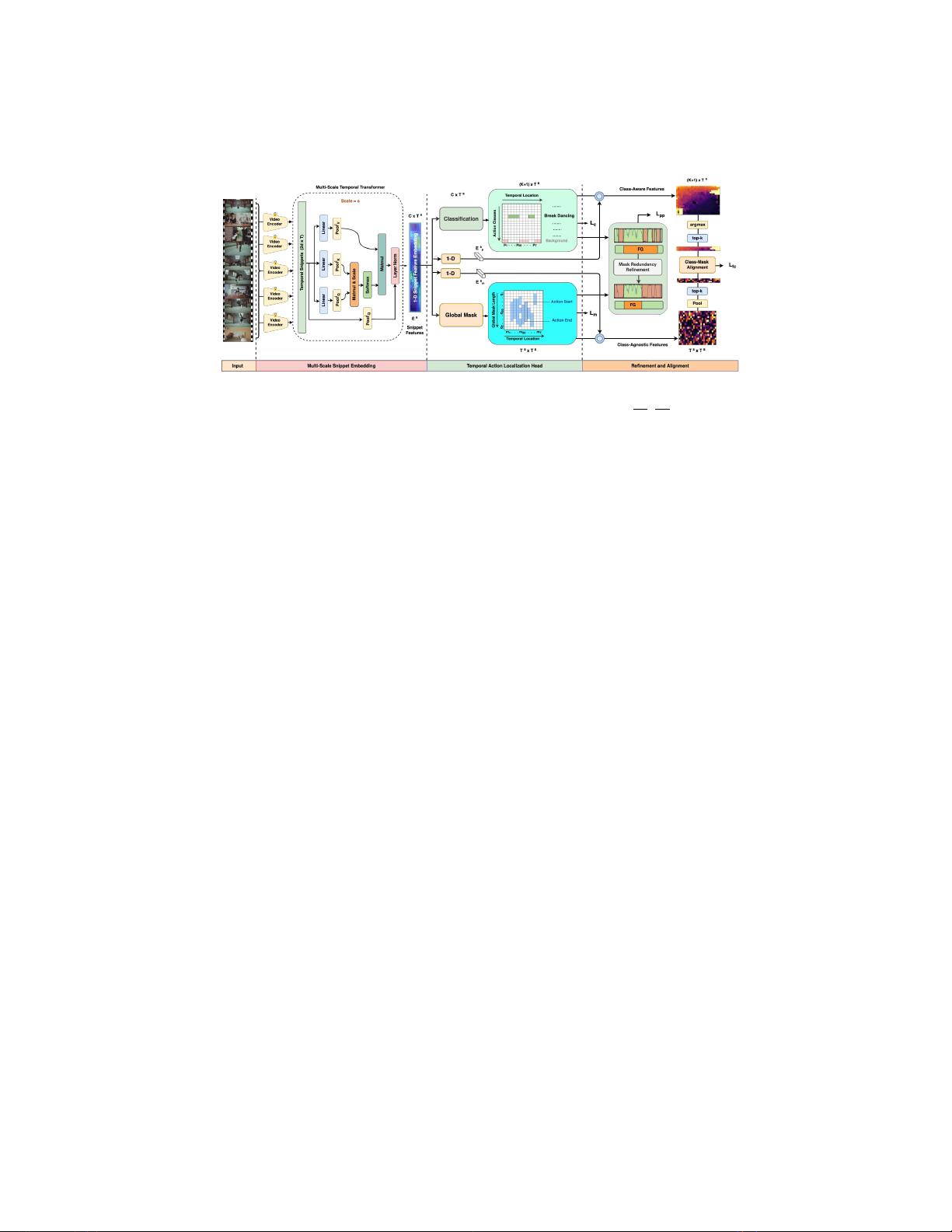
图 2 : 我 们 的 无 建 议 时 间 间 隔 检 测 模 型 的 架 构
,通 过
G/S
分 段 掩 码
(
TAGS
)。
给定未修剪的视频,TAGS首先使用预先训练的视频编码
器(
例如,
,I3D [7]),并在多
个
时间尺度
s
上进行自主学习,以获得具
有全局上下文的片段嵌入。随后,对于每个片段嵌入,TAGS对不同的动
作进行分类(输出
P
s
R
(
K
+1)×
T
,其中
K
是动作类编号),并在双分支设
计中同时预测全视频长的前景掩码(输出
M
s
R
T
×
T
)。 在训练过程中,
TAGS最大限度地减少了类和掩码预测与地面实况的差异。为了更准确的
定位,一个有效的边界细化策略,进一步引入,随着掩码预测冗余和分
类掩码一致性正则化。在推断期间,TAGS从分类输出P中选择得分最高
的片段,然后在每个尺度下对M中的对应前景掩模进行阈值化,然后将
它们聚合以产生动作实例候选。最后,应用softNMS去除冗余候选。
Self-attention 我 们 的 片 段 表 示 是 基 于 self-attention 学 习 的 , 这 在
Transformers中首次引入,用于自然语言处理任务[36]。在计算机视觉
中,非局部神经网络[41]将transformers的核心自注意力块应用于上下文建
模和特征学习。通过使用这种注意力模型,在分类[13]、自监督学习
[9]、语义分割[49,53]、对象检测[6,48,55]、少量动作识别[28,54]和
对象跟踪[10最近的几部作品[35,40,29,26,25,27,24]也使用了变形
金刚。他们专注于时间提案生成[35]或细化[29]。在本文中,我们证明了
自我注意力的有效性,在一个新的无提案的可扩展架构。
3
无建议全局分割掩码
我们的
全局分割掩模
(TAGS)模型将未修剪的视频作为输入
具有可变帧数的
V
视频帧由要素进行预处理
下载后可阅读完整内容,剩余17页未读,立即下载
相关推荐







cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开








最新资源
- Linux下的IPPICV库压缩包解析指南
- MSSQL、Oracle与MySql数据库连接示例类解析
- ENVI4.8汉化补丁及卸载教程
- 基于C#的高效人事工资管理系统操作指南
- PPT设计与素材整合技巧分享
- 计算机图形学基础算法与源代码解析
- Findprop在Matlab中的应用:查找图形对象属性值
- VSCode扩展功能:前端开发与调试
- 21天精通C++编程:第4版学习指南
- 数据库JDBC连接包及示例:SQL2000, SQL2005, ORACLE, MYSQL
- VB实现内部消息通信工具源码分享
- 现代简约风格客厅3D模型设计
- 深入理解Junit4.7单元测试应用与实践
- VC环境下高斯消去法的实现与应用
- MATLAB自动频谱分析:处理不规则采样与缺失数据
- Android9环境下动态权限申请与硬件信息获取方法






















