Hadoop数据仓库:Hive详解与应用
需积分: 21 65 浏览量
更新于2024-07-29
收藏 1.09MB DOCX 举报
“Hadoop数据仓库工具--hive介绍”
Hive是Apache Hadoop生态系统中的一个关键组件,它设计用于处理和管理大规模数据集。Hive构建在Hadoop之上,利用HDFS(Hadoop分布式文件系统)作为底层数据存储,并通过MapReduce进行数据处理。它的主要目的是为了解决对大规模数据进行离线分析的问题,尤其是对于那些不适合用传统关系型数据库管理系统(RDBMS)处理的大型数据集。
**Hive的核心特性**
1. **SQL-like查询语言(HQL)**:Hive提供了一种类SQL语言,称为HiveQL,使得非程序员也能方便地对大数据进行查询和分析,无需深入理解MapReduce编程模型。
2. **元数据存储**:所有关于Hive表、列、分区等的信息都存储在一个称为元数据存储的数据库中,通常使用MySQL或Derby。元数据包括表的结构、表的位置、表的分区信息等。
3. **数据分区**:Hive支持数据分区,这意味着可以将大表分成多个小块,每个分区对应数据的一个特定属性值。这样可以提高查询性能,因为针对特定分区的查询只需要扫描相关的数据子集,而不是整个表。
4. **批处理**:Hive主要用于批处理任务,而非实时或流式数据处理。它适合执行长时间运行的分析查询,而不是快速响应的事务性操作。
5. **可扩展性**:Hive可以轻松扩展到数千台服务器,以处理PB级别的数据。
6. **容错性**:Hive通过MapReduce的容错机制确保数据处理的可靠性,即使部分节点故障,系统也能继续运行。
7. **与其他Hadoop组件集成**:除了HDFS和MapReduce,Hive还可以与HBase、Pig等其他Hadoop组件集成。例如,Hive可以通过HBase接口直接读写数据到HBase,结合两者的优势,实现快速查询和大规模数据存储。
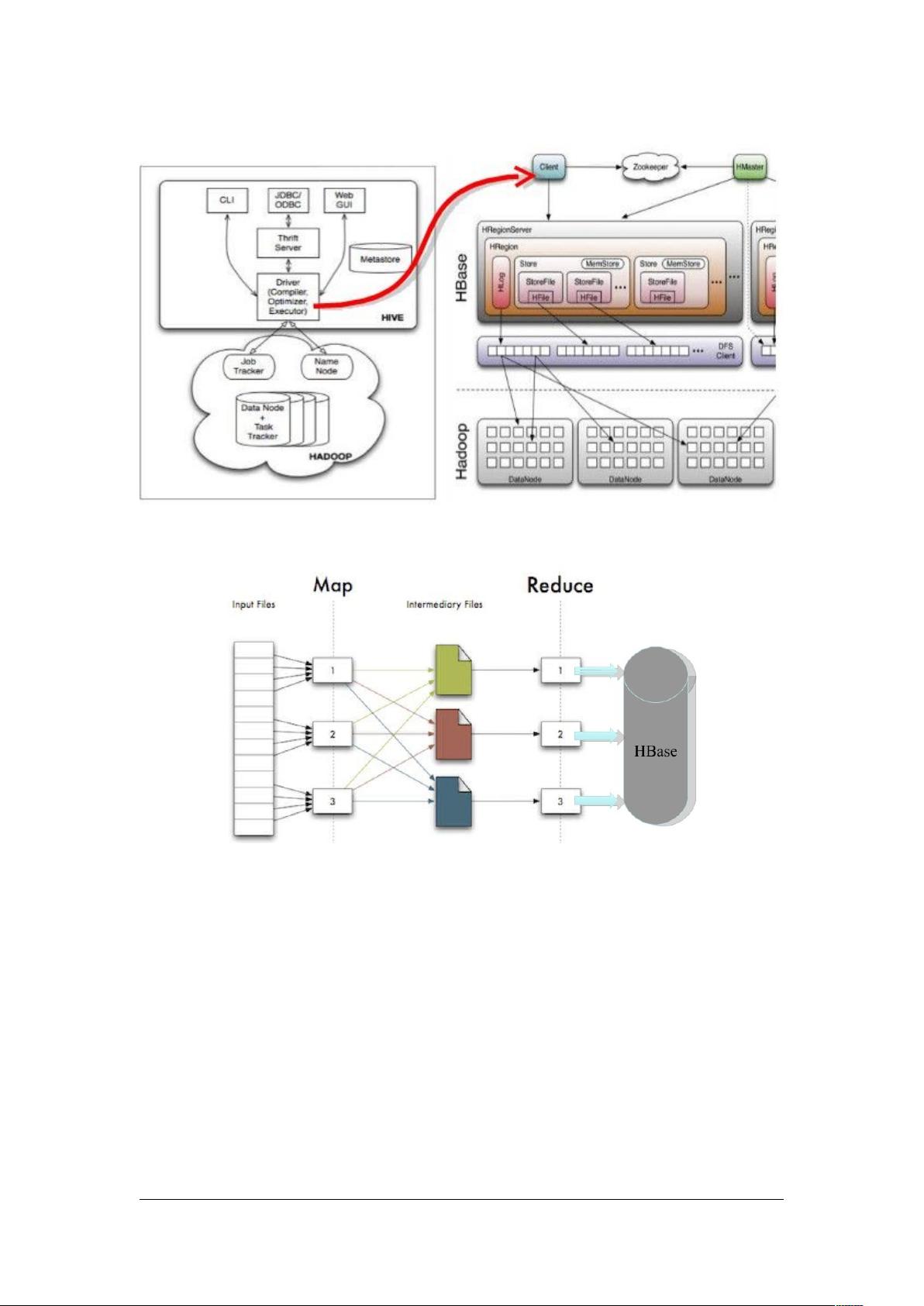
**Hive的架构**
Hive的架构主要包括以下组件:
- **操作界面**:用户可以通过命令行接口(CLI)、Web界面或Thrift API与Hive交互。
- **Driver**:驱动器负责解释和优化HQL语句,将其转换为一系列MapReduce任务。
- **Metastore**:存储元数据,如表结构、分区信息等,通常作为一个单独的服务运行。
- **Hadoop**:HDFS提供数据存储,MapReduce执行计算任务。
**Hive与HBase的结合**
Hive可以与NoSQL数据库HBase集成,以实现更快速的数据存取。Hive通过HBase的列族和行键将数据写入HBase,而在查询时,Hive会直接从HBase中读取数据,跳过MapReduce过程,提高查询速度。
**Hive的其他功能**
- **表的操作**:Hive支持创建、修改和删除表、视图以及分区。
- **数据加载**:Hive允许从本地文件系统或HDFS加载数据到表中,并可以覆盖已有数据。
- **自定义MapReduce**:用户可以编写自定义的MapReduce程序,以处理Hive无法直接支持的复杂计算需求。
总结来说,Hive是一个强大的数据仓库工具,通过提供SQL-like接口简化了Hadoop上的大数据处理,适合进行离线分析和数据挖掘。它与Hadoop生态系统的其他组件紧密集成,增强了大数据处理的灵活性和效率。
+、 不只是可以
图表 2 hive 结合 HBase 的逻辑图[5]”
图表 3 reduce 阶段写入 HBase 的方式[5]”
百度在线网络技术(北京)有限公司
剩余15页未读,继续阅读
294 浏览量
113 浏览量
154 浏览量
284 浏览量
218 浏览量
193 浏览量
202 浏览量
2024-09-15 上传
219 浏览量









