Shell脚本中逐行读取.doc文件的3种方法
下载需积分: 31 | DOC格式 | 70KB |
更新于2024-08-13
| 181 浏览量 | 举报
在Shell脚本中逐行读取文件是一项常见的任务,有助于处理大量数据或按行执行操作。本文档介绍了两种方法来实现这一目标。
首先,方法一是通过使用输入重定向结合while循环。在shell脚本中,创建一个名为`example1.sh`的脚本,其基本结构如下:
```bash
#!/bin/bash
while IFS= read -r rows; do
echo "Line contents are: $rows"
done < mycontent.txt
```
在这个例子中,`IFS= read -r rows`会逐行读取文件`mycontent.txt`的内容,`IFS`(Internal Field Separator)被设置为空格,确保正确解析每一行。`-r`选项防止转义字符的影响。每次循环,`$rows`变量会存储当前行的内容,然后使用`echo`输出包含自定义字符串和变量的行。
另一种方法是利用`cat`命令和管道符`|`。在`example2.sh`脚本中,代码如下:
```bash
#!/bin/bash
cat mycontent.txt | while read rows; do
echo "Line contents are: $rows"
done
```
`cat mycontent.txt`会将文件内容传递给管道,然后`while`循环接收并逐行处理这些内容。同样,`$rows`变量储存每行文本。
两种方法都支持简化版,例如将while循环和`read`命令合并成一行:
```bash
#!/bin/bash
while read -r rows; do echo "Line contents are: $rows"; done < mycontent.txt
```
或者
```bash
#!/bin/bash
cat mycontent.txt | while read rows; do echo "Line contents are: $rows"; done
```
这些技巧使得Shell脚本在处理文件时更加灵活高效。通过了解和熟练运用这些方法,程序员可以在处理文本文件时实现高效的行级操作。
如何在 Shell 脚本中逐行读取文件
在这里,我们学习 Shell 脚本中的 3 种方法来逐行读取文件。
方法一、使用输入重定向
逐行读取文件的最简单方法是在 while 循环中使用输入重定向。为了演
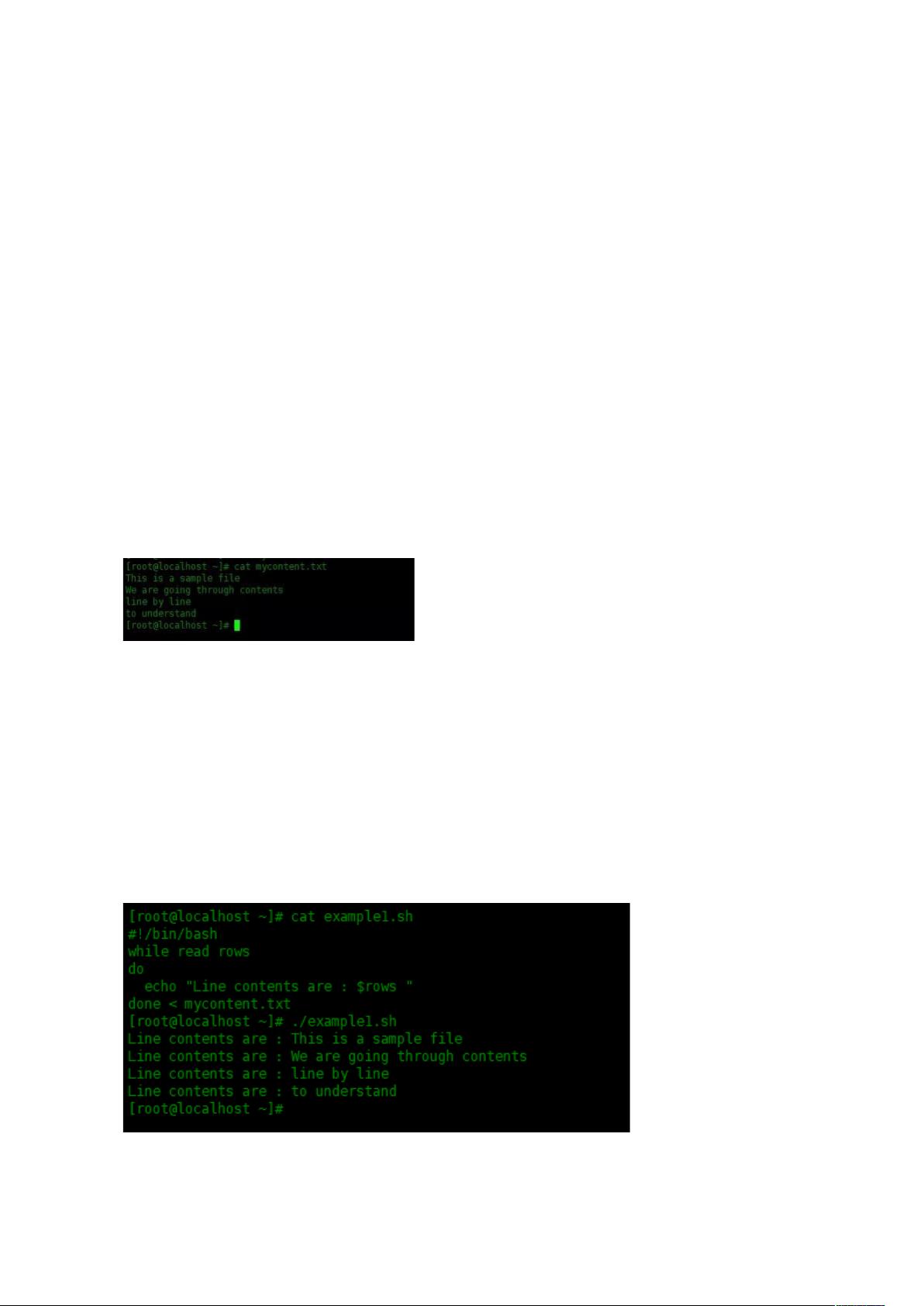
示,在此创建一个名为“ mycontent.txt”的文本文件,文件内容在下面:
[root@localhost~]#catmycontent.txt
Thisisasamplefile
Wearegoingthroughcontents
linebyline
tounderstand
创建一个名为“ example1.sh”的脚本,该脚本使用输入重定向和循环:
[root@localhost~]#catexample1.sh
#!/bin/bash
whilereadrows
do
echo"Linecontentsare:$rows"
done<mycontent.txt
运行结果:
下载后可阅读完整内容,剩余3页未读,立即下载
相关推荐





天蝎兔Rabbit
- 粉丝: 35
 我的内容管理
展开
我的内容管理
展开







最新资源
- VB实现Excel数据导入到ListView控件技术
- 触屏版wap购物网站模板及多技术源码大全
- ZOJ1027求串相似度解题策略与代码分析
- Excel表格数据合并工具:高效整合多个数据源
- MFC列表控件:实现下拉选择与编辑功能
- Tinymce4集成Powerpaste插件即用版使用教程
- 探索QMLVncViewer:Qt Quick打造的VNC查看器
- Mybatis生成器:快速自定义实体类与Mapper文件
- Dota 2插件开发:TrollsAndElves自定义魔兽3地图攻略
- C语言编写单片机控制蜂鸣器唱歌教程
- Ansible自动化脚本简化Ubuntu本地配置流程
- 探索ListView扩展:BlurStickyHeaderListView源码解析
- 探索traces.vim插件:Vim的范围选择与模式高亮预览
- 快速掌握Ruby编译与安装的神器:ruby-build
- C语言实现P1口灯花样控制源代码及使用指南
- 会员管理系统:消费激励方案及其源代码
