轻松掌握大数据:Hadoop工具详解
需积分: 10 39 浏览量
更新于2024-07-17
收藏 16.07MB PDF 举报
《Big Data Made Easy》是一本由Michael Frampton编著的专业英文书籍,由Apress出版社发行,专为想要深入了解基于Hadoop的大数据工具集的学习者设计。本书以易于理解的方式介绍了大数据处理中的核心概念和技术,尤其针对的是那些希望在大数据领域建立坚实基础的读者。
本书首先从介绍大数据面临的问题出发,帮助读者理解为什么需要处理大量复杂数据以及Hadoop生态系统的重要性。第1章深入探讨了数据问题及其解决方案,引导读者认识到大数据处理不仅仅是技术问题,更是业务洞察的关键。
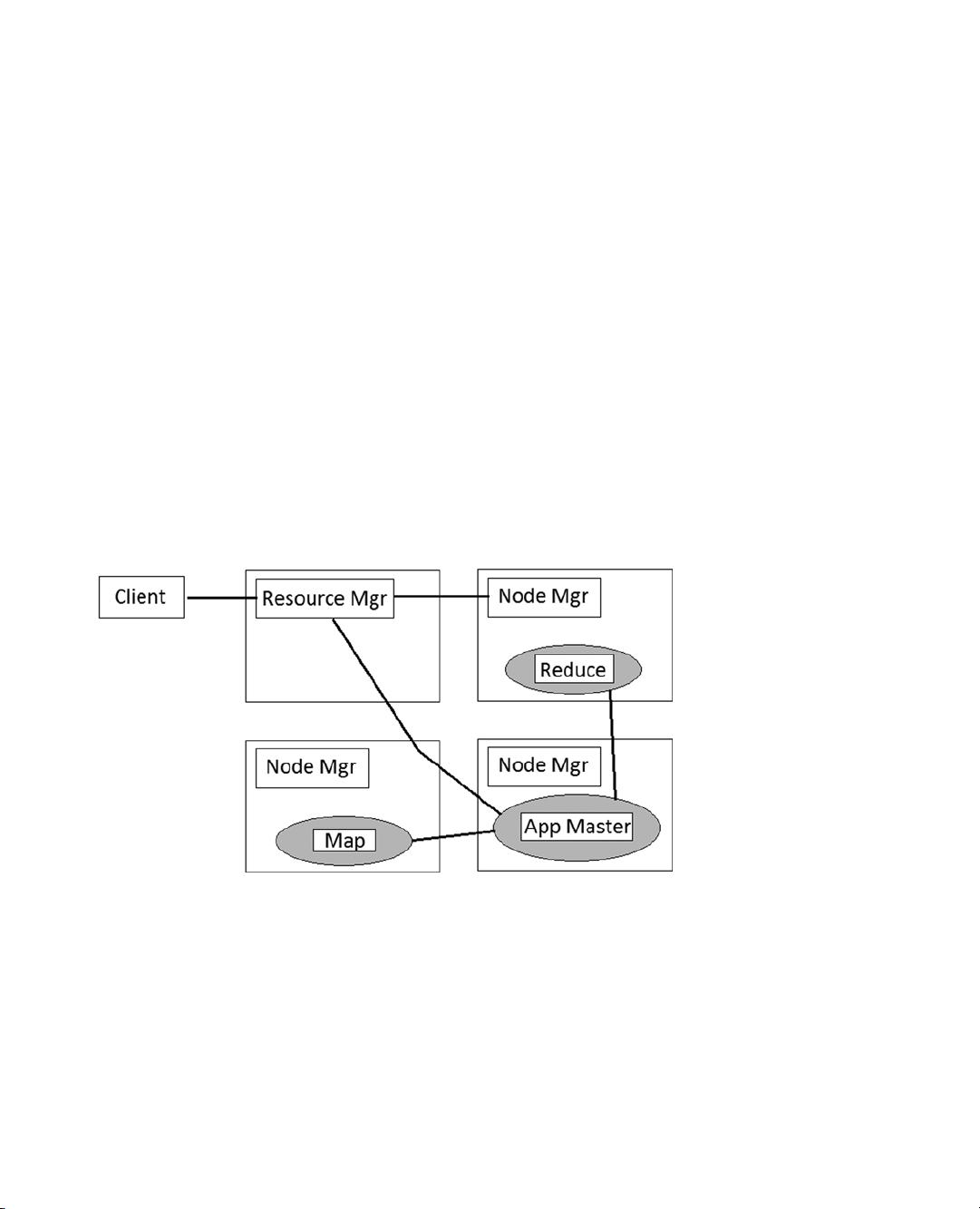
第二章详细讲解了如何利用Hadoop、YARN(Yet Another Resource Negotiator)和ZooKeeper来存储和配置数据。Hadoop作为分布式计算的基础,YARN负责资源管理和任务调度,而ZooKeeper则提供了分布式系统中的协调服务,确保数据一致性。
第三章和第四章分别聚焦于数据收集和处理,通过Nutch(一个强大的网络抓取工具)和Solr(用于全文搜索的工具)来收集数据,然后用MapReduce模型进行大规模数据处理,展示了如何实现分布式计算的强大能力。
第五章讨论了数据调度和工作流管理,确保高效地执行复杂的分析任务,包括任务分配、依赖关系管理和并行处理。
第六章重点在于数据移动,涵盖了如何在Hadoop集群内部或与其他系统之间传输数据,这对于数据集成和分布式的数据仓库建设至关重要。
第七章介绍了数据监控,帮助读者了解系统的运行状态,识别性能瓶颈,以及如何通过日志分析和指标跟踪来优化数据处理过程。
第八章深入到集群管理层面,包括硬件选型、配置调整和故障恢复,确保Hadoop集群的稳定运行。
第九章和第十章着重于数据分析和ETL(Extract, Transform, Load)过程,阐述如何使用Hadoop进行深度分析,提取有价值的信息,并将数据清洗和转换为适合分析的形式。
最后一章探讨了Hadoop在报告和可视化方面的应用,如何将处理后的数据转化为易读的报表,以便于业务决策。
《Big Data Made Easy》不仅包含丰富的实战案例,而且每个章节都配以实用的代码示例,确保读者能够迅速上手并应用所学知识。此外,作者还使用了CentOS作为主要的操作系统平台,使读者能够在常见的Linux环境中实践书中的教程。对于初学者和有一定经验的开发者来说,这本书是理解和掌握大数据处理不可或缺的资源。

11
CHAPTER 2
Storing and Configuring Data with
Hadoop, YARN, and ZooKeeper
This chapter introduces Hadoop versions V1 and V2, laying the groundwork for the chapters that follow. Specifically,
you first will source the V1 software, install it, and then configure it. You will test your installation by running a simple
word-count Map Reduce task. As a comparison, you will then do the same for V2, as well as install a ZooKeeper
quorum. You will then learn how to access ZooKeeper via its commands and client to examine the data that it stores.
Lastly, you will learn about the Hadoop command set in terms of shell, user, and administration commands. The
Hadoop installation that you create here will be used for storage and processing in subsequent chapters, when you
will work with Apache tools like Nutch and Pig.
An Overview of Hadoop
Apache Hadoop is available as three download types via the hadoop.apache.org website. The releases are named as
follows:
Hadoop-1.2.1•
Hadoop-0.23.10•
Hadoop-2.3.0•
The first release relates to Hadoop V1, while the second two relate to Hadoop V2. There are two different release
types for V2 because the version that is numbered 0.xx is missing extra components like NN and HA. (NN is “name
node” and HA is “high availability.”) Because they have different architectures and are installed differently, I first
examine both Hadoop V1 and then Hadoop V2 (YARN). In the next section, I will give an overview of each version and
then move on to the interesting stuff, such as how to source and install both.
Because I have only a single small cluster available for the development of this book, I install the different
versions of Hadoop and its tools on the same cluster nodes. If any action is carried out for the sake of demonstration,
which would otherwise be dangerous from a production point of view, I will flag it. This is important because, in
a production system, when you are upgrading, you want to be sure that you retain all of your data. However, for
demonstration purposes, I will be upgrading and downgrading periodically.
So, in general terms, what is Hadoop? Here are some of its characteristics:
It is an open-source system developed by Apache in Java.•
It is designed to handle very large data sets.•
It is designed to scale to very large clusters.•
It is designed to run on commodity hardware.•



剩余380页未读,继续阅读
2019-09-23 上传
2015-11-06 上传
2019-02-13 上传
2021-03-25 上传
2017-01-12 上传
2013-11-26 上传
2016-12-16 上传
2018-04-17 上传
2018-02-24 上传

tubolao888
- 粉丝: 1
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
