机器学习实战:微博文本分类与预处理解析
"基于机器学习的文本分类.pptx 是一个关于使用机器学习进行文本分类的演示文稿,其中详细介绍了如何运用机器学习算法,特别是朴素贝叶斯,来预测文本类别。该文稿提到了从语料选择、预处理、分词到模型训练和评估的整个流程,并特别强调了在中文文本处理中使用jieba分词库的重要性。"
在文本分类任务中,机器学习扮演着关键角色,它能够自动学习并识别文本的特征,进而将其归类到不同的主题或类别中。在这个PPT中,作者首先介绍了文本分类的基本步骤:
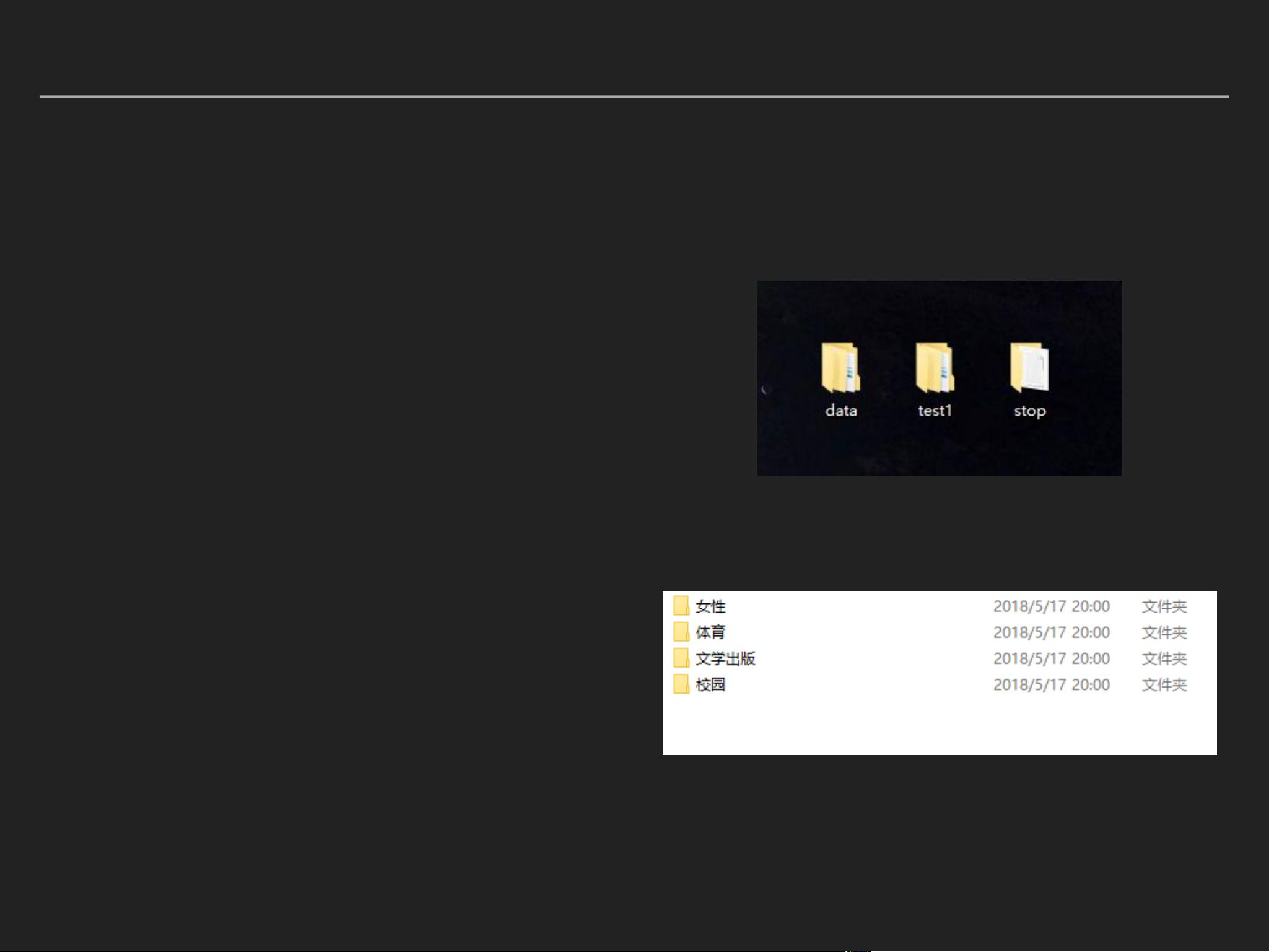
1. **语料选择**:选择合适的训练数据至关重要,这些数据应该是已经标记好的,即每个文本都有对应的类别标签。语料库的选择应当覆盖多种内容类型,且数据量充足,以便模型能学习到丰富的信息。
2. **预处理**:预处理阶段包括消除噪声,如去除特殊字符、标点符号、制表符、空格等,并对文本进行规范化处理。这一步骤有助于提高模型对文本的理解能力。
3. **中文分词**:中文分词是将连续的汉字序列切分成具有独立意义的词语。由于中文没有明显的词边界,因此分词是中文自然语言处理的关键。在示例中,使用了jieba分词库,它提供了精确模式、全模式和搜索引擎模式三种分词方式,以适应不同的需求。
4. **构建训练集和测试集向量空间**:使用词频(TF)计算每个文本的词向量,并移除停用词,如“的”、“是”、“在”等。这一步将文本转换为数值形式,便于机器学习算法处理。
5. **模型训练**:这里选择了朴素贝叶斯分类器。朴素贝叶斯是一种基于概率的分类方法,假设特征之间相互独立,适用于文本分类,因为它简单且效率高。
6. **结果评价**:通过评估模型在测试集上的表现,如准确率、召回率和F1分数,来衡量模型的性能。
在实际应用中,文本分类被广泛应用于社交媒体分析、情感分析、新闻分类、垃圾邮件过滤等领域。这个PPT和配套博客提供了一个实用的教程,指导读者如何使用Python和机器学习技术,特别是朴素贝叶斯和jieba分词,来解决文本分类问题。通过理解并实践这些步骤,开发者和研究者可以建立自己的文本分类系统,提升信息处理的效率和准确性。
文本
语料选择
▸
选择语料库,数据集,停用词集
▸
语料库内分不同内容种类
剩余25页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-10 上传
2021-09-21 上传
2024-04-24 上传
2024-03-17 上传
2024-06-01 上传
2024-05-29 上传









