WEKA数据挖掘工具全面指南
需积分: 35 155 浏览量
更新于2024-07-23
收藏 575KB PDF 举报
"这篇文档是关于WEKA 3.5.5版本的Explorer用户的详细指南,涵盖了从启动WEKA到各个功能模块的操作介绍,包括预处理、分类、聚类、关联规则、属性选择以及可视化等核心功能。"
WEKA是一个流行的数据挖掘工具,尤其在机器学习领域中广泛应用。其Explorer界面提供了用户友好的交互式环境,用于数据预处理、模型构建、评估和可视化。以下是各部分的详细说明:
1. **启动WEKA**:通过GUIChooser启动,支持MDI界面,有Program菜单,其中包含LogWindow(记录输出信息)和Exit(退出程序)等功能。
2. **WEKAExplorer**:这是主要的探索数据环境,包含了多个标签页,如数据加载、预处理、分类、聚类、关联规则等,同时有状态栏、日志按钮和WEKA状态图标。
3. **预处理**:包括数据的加载、查看当前数据关系、属性处理和应用过滤器。数据预处理是数据分析的关键步骤,用于清洗数据、处理缺失值、转换数据类型等。
4. **分类**:用户可以选择分类器,设置测试选项,指定类别属性,训练模型,并查看分类器输出和结果列表。分类任务是预测一个离散的目标变量。
5. **聚类**:选择聚类算法,查看聚类模式,设置忽略属性,训练聚类模型。聚类是无监督学习,寻找数据的内在结构和相似性。
6. **关联规则**:设定关联规则学习的参数,进行学习,用于发现数据中的频繁项集和强关联规则。
7. **属性选择**:搜索和评估最佳属性子集,设置属性选择的选项并执行选择。属性选择能提升模型性能,减少不相关属性的影响。
8. **可视化**:包括散点图矩阵、二维散点图和实例选择,帮助用户直观理解数据分布和模型效果。
此文档不仅适合初学者了解WEKA的基本操作,也对有一定经验的用户进行更深入的数据分析和模型构建提供了指导。通过WEKA,用户可以方便地进行数据预处理、构建机器学习模型,并通过可视化工具进行结果验证和理解。
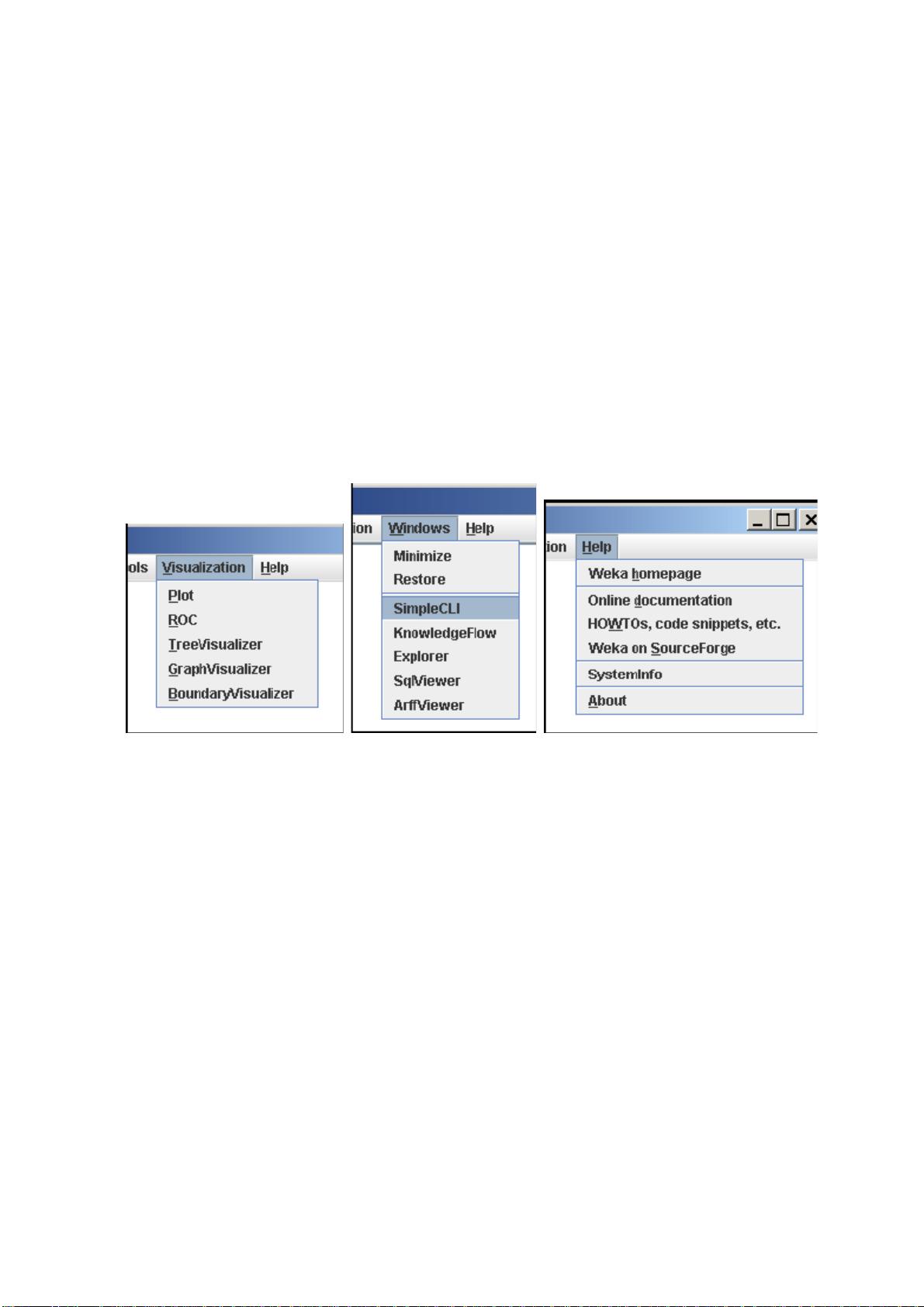
z TreeVisualizer 显示一个有向图,例如一个决策树。
z GraphVisualizer 显示 XML、BIF 或 DOT 格式的图片,例如贝叶斯网络
(Bayesian network)。
z BoundaryVisualizer 允许在二维空间中对分类器的决策边界进行可视化。
5. Windows 所有已打开的窗口都列在这里。
z Minimize 最小化所有当前的窗口。
z Restore 还原所有最小化过的窗口。
6. Help WEKA 的在线资源可以从这里找到。
z Weka homepage 打开一个浏览器窗口,显示 WEKA 的主页。
z Online documentation 链接到 WekaDoc 维基文档 [4]。
z HOWTOs, code snippets, etc. 通用的 WekaWiki [3],包括大量的例子,
以及开发和使用 WEKA 的基本知识(HOWTO)。
z Weka on Sourceforge WEKA 项目在 Sourceforge.net 的主页。
z SystemInfo 列出一些关于 Java/WEKA 环境的信息,例如 CLASSPATH。
z About 不光彩的“About”窗口。
如果从终端启动 WEKA,会有一些文字在终端窗口中出现。这些文字是可以忽略的,
除非某些东西出错了——这时它可以帮助找到错误的原因。(LogWindow 也可以显示那
些信息。)
这份文档也可以从在线的
WekaDoc Wiki
[4] 中找到,它将集中阐述如何使用
Explorer,而不会逐个解释 WEKA 中的数据预处理工具和学习算法。要获得关于各种筛选
器(filter)和学习算法的更多信息,可参考
Data Mining
[2] 一书。
剩余19页未读,继续阅读
2010-05-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

yayisnail_0
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
