线上AdPlatform集群CPU飙升:Date对象过大引发的深度剖析
需积分: 9 143 浏览量
更新于2024-09-05
收藏 2.17MB DOCX 举报
线上adplatform集群机器CPU飙升问题的排查与解决是一个实际的生产环境中的挑战,发生于2018年12月3日,当集群中的服务出现超时和抛弃量增加的情况。该事件促使团队深入调查,首先通过服务管理平台和云平台监控发现CPU使用率异常,达到100%,导致部分机器被隔离以分析问题根源。
在排查过程中,团队使用了常见的系统命令,如`top`和`ps-ef|grep adplatform`,定位到异常进程PID为674。进一步使用`jstat-gcutil`查看GC信息,发现old区内存占用已高达100%,这表明可能存在的内存泄漏问题。随后生成`jstack`日志和`jmap-dump`文件,以便在本地详细分析。
分析结果显示,问题的关键在于一个名为`TreeMap`的数据结构中存储了2800万个Date对象,占用了1120MB的内存,这使得对象大小进入了老年代(old区)。调用栈追踪显示异常发生在`common`包的`ScheduleFormatUtil`类的第114行,但当时的日志并未明确显示问题的具体位置,因为该行没有直接操作`TreeSet`。
团队怀疑114行的`getHour`方法可能是问题触发点,因为传入的startTime和endTime差距过大,导致TreeSet的大小不断增长,最终填满了old区,引发内存溢出。然而,他们不确定是否真的误判了错误的代码行。
为验证假设,团队设计了一个实验性Demo来重现CPU飙升现象,以确认代码逻辑中的问题并找出解决方案。这种实践对于理解和解决内存管理问题,特别是在JVM和Full GC方面,是非常重要的经验教训。
此次排查和解决问题的过程涉及到了JVM内存管理、Full GC的理解,以及如何通过日志、堆转储文件和性能分析工具(如JProfiler)来诊断内存泄漏。对于线上服务的维护人员来说,这类经验对于优化系统性能,避免类似问题再次发生具有很高的价值。通过识别和修复代码中的内存消耗瓶颈,可以提升系统的稳定性和响应速度,确保业务的正常运行。
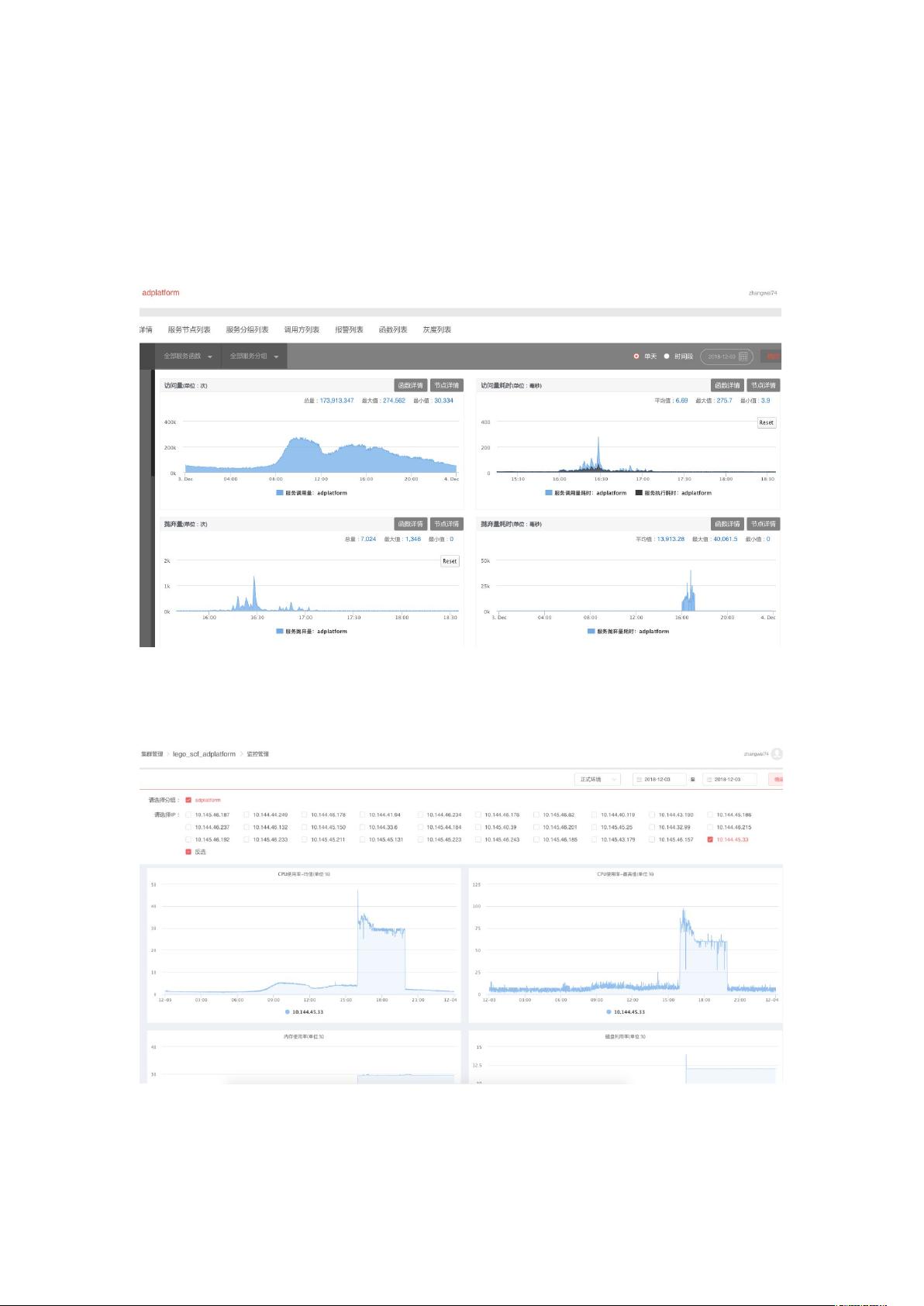
排查:
1. 首先到服务管理平台上查报警的服务及服务之间的调用,发现 adplaorm 集群从 12 月
03 日 15:59:00 开始,访问量耗时、抛弃量都很高。并且各个调用方的耗时都很高
2. 然后到云平台看 adplaorm 集群的监控,发现部分机器的 cpu 飙升,cpu 使用率一度达
到 100%
3. 当时为了线上服务稳定,把 cpu 飚高的机器踢掉了,只留了 10.144.45.33 机器,用来
分析 cpu 飚高的原因
剩余12页未读,继续阅读

huanghe_0918
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
