MapReduce:大数据分布式计算框架解析
版权申诉
124 浏览量
更新于2024-07-03
收藏 1.61MB PDF 举报
"该资源是关于大数据技术框架的讲解,主要聚焦于MapReduce,这是一个用于处理大规模数据的分布式计算框架。文档共44页,详细介绍了MapReduce在大数据处理中的应用,包括数据分布式存储、作业调度、容错机制以及机器间通信等关键问题。此外,内容还涉及Hadoop Streaming,MapReduce的存储模型,以及MapReduce的基本概念、分而治之的思想和执行流程。"
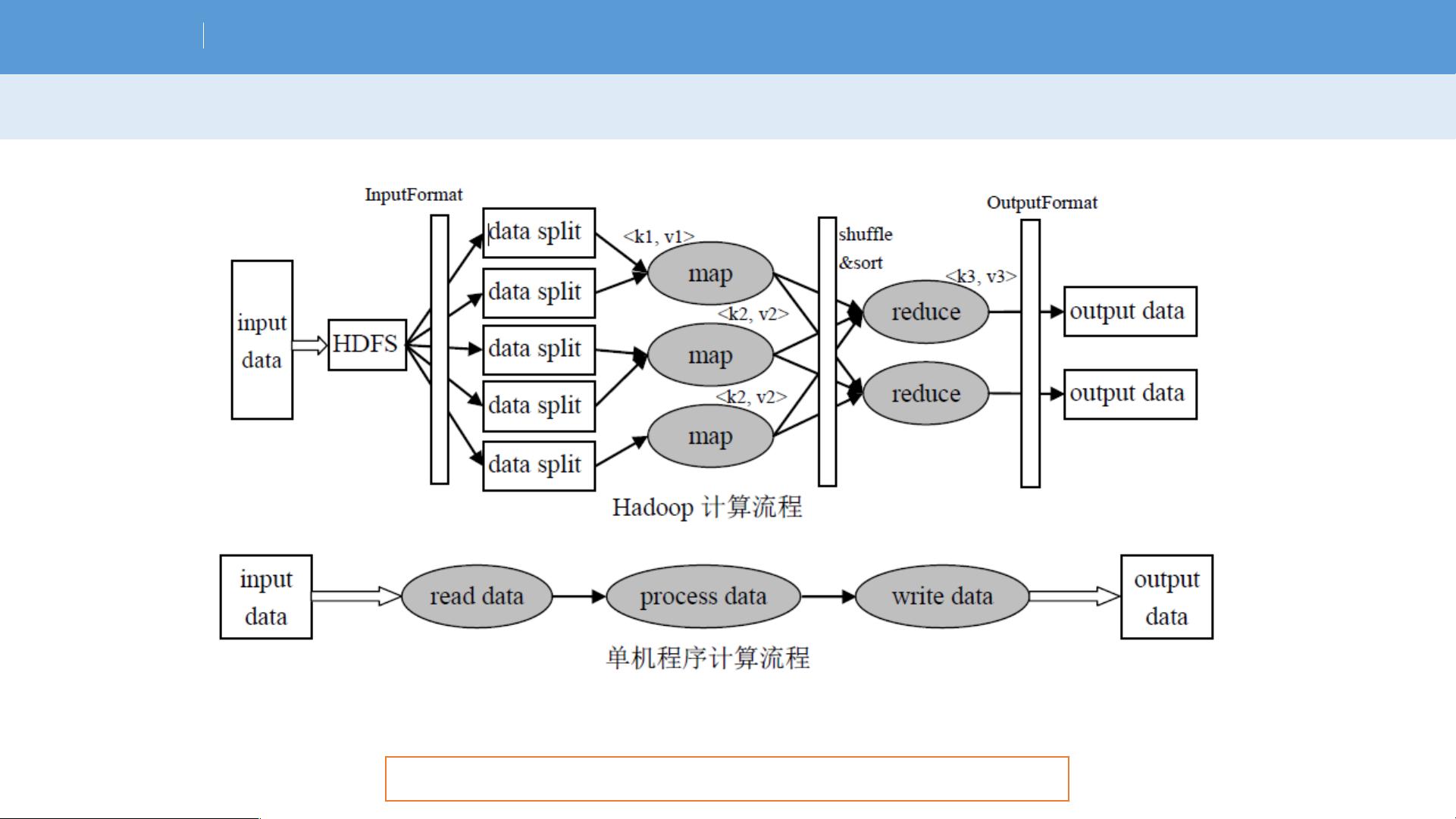
MapReduce是大数据处理领域中的核心组件,由Google提出,旨在简化海量数据的处理工作。它通过分而治之的策略,将复杂的大规模计算问题拆分成可并行处理的小任务,从而高效地处理PB级别的数据。MapReduce包含两个主要阶段:Map阶段和Reduce阶段。
Map阶段是对原始数据进行处理的过程,通常用于数据的过滤和转换。在这个阶段,输入数据被分割成多个块(Block),每个块会被分配到不同的节点上,并由Map函数进行独立处理。Map函数将输入数据转化为键值对(Key-Value Pairs)的形式,这些中间结果会被分区(Partitioned)并排序,然后传递给Reduce阶段。
Reduce阶段是聚合Map阶段产生的中间结果,执行进一步的计算,以生成最终的结果。Reduce函数接收来自Map阶段的键值对,对同一键的所有值进行聚合操作,如求和、计数或者连接等,最后生成最终的输出。
MapReduce框架还处理了数据的分布式存储问题,采用Hadoop Distributed File System (HDFS)。HDFS是一个高容错、可扩展的文件系统,它将大文件分割成多个块(Chunks),并复制到多台机器上,确保数据的可靠性和高可用性。在HDFS中,每个数据块都有多个副本,以防止单点故障。
作业调度是MapReduce的另一重要方面,它负责决定何时、何地运行Map和Reduce任务。MapReduce框架会自动处理机器间的通信,确保数据的正确传输和任务的协调。同时,框架内置了容错机制,当某个节点出现故障时,可以自动将任务重新调度到其他可用节点,确保计算的连续性。
MapReduce通过提供一个抽象的计算模型,使得开发者能够专注于业务逻辑,而无需关心底层的分布式存储和计算细节。这极大地简化了大数据处理的复杂性,是大数据分析和挖掘的重要工具。通过学习和掌握MapReduce,开发者可以构建起处理大规模数据的解决方案,应对现代数据密集型应用的挑战。
大数据培训 MapReduce
MapReduce ——
M a p R e d u c e 分而治之思想
• 分治思想
– 分解
– 求解
– 合并
• MapReduce映射
– 分:map
• 把复杂的问题分解为若干“简单的
任务”
– 合:reduce
剩余43页未读,继续阅读
106 浏览量
108 浏览量
2024-06-02 上传
2024-06-02 上传
2022-03-20 上传
2022-12-17 上传
113 浏览量
109 浏览量
2021-08-08 上传

passionSnail
- 粉丝: 469
- 资源: 7836
 我的内容管理
展开
我的内容管理
展开







最新资源
- 20210805-西南证券-思瑞浦-688536-业绩持续增长,电源管理芯片表现亮眼.rar
- nodejs-restapi:使用Node.js和MongoDB Atlas设计REST API
- 易语言动画播放器
- spring-cloud-api-gateway
- 福州大学汇编语言程序设计实践作业(堆排序八皇后等).zip
- 作品答辩极简建筑系风格大学生设计答辩模板.rar
- MyBaD - MySQLish MP3 frontend-开源
- backbone.helpers:一组用于扩展 Backbone.js 的辅助类
- 易语言JnToo播放器源码 易语言MP3播放器
- Encode Utility.-crx插件
- antd-pro-hapijs-user:基于antd pro + hapi-api的带权限用户管理
- SHC-公共商店
- My-Portfolio:这是我的个人网站的仓库。这反映了我是谁!
- 20210805-中信期货-饲料养殖专题报告:生猪调研,疫情干扰出栏节奏,现货价格阶段存反弹预期.rar
- kmihiel.github.io
- ASP+ACCESS新闻发布系统(源代码+LW).zip
