深度学习驱动的OCR与文本定位:传统方法与CNN应用比较
需积分: 9 151 浏览量
更新于2024-09-09
收藏 707KB PDF 举报
本文主要探讨了光学字符识别(OCR)和文本检测(Text Spotting)这两个在自然场景字符识别领域的重要技术。OCR是一种计算机技术,用于从图像或扫描文档中识别并转换文本,而Text Spotting则是在图像中不仅识别文本,还要定位这些文本的位置。本文将焦点放在深度学习方法上,特别是如何通过结合传统方法和深度神经网络(如卷积神经网络,CNN)来改进OCR性能。
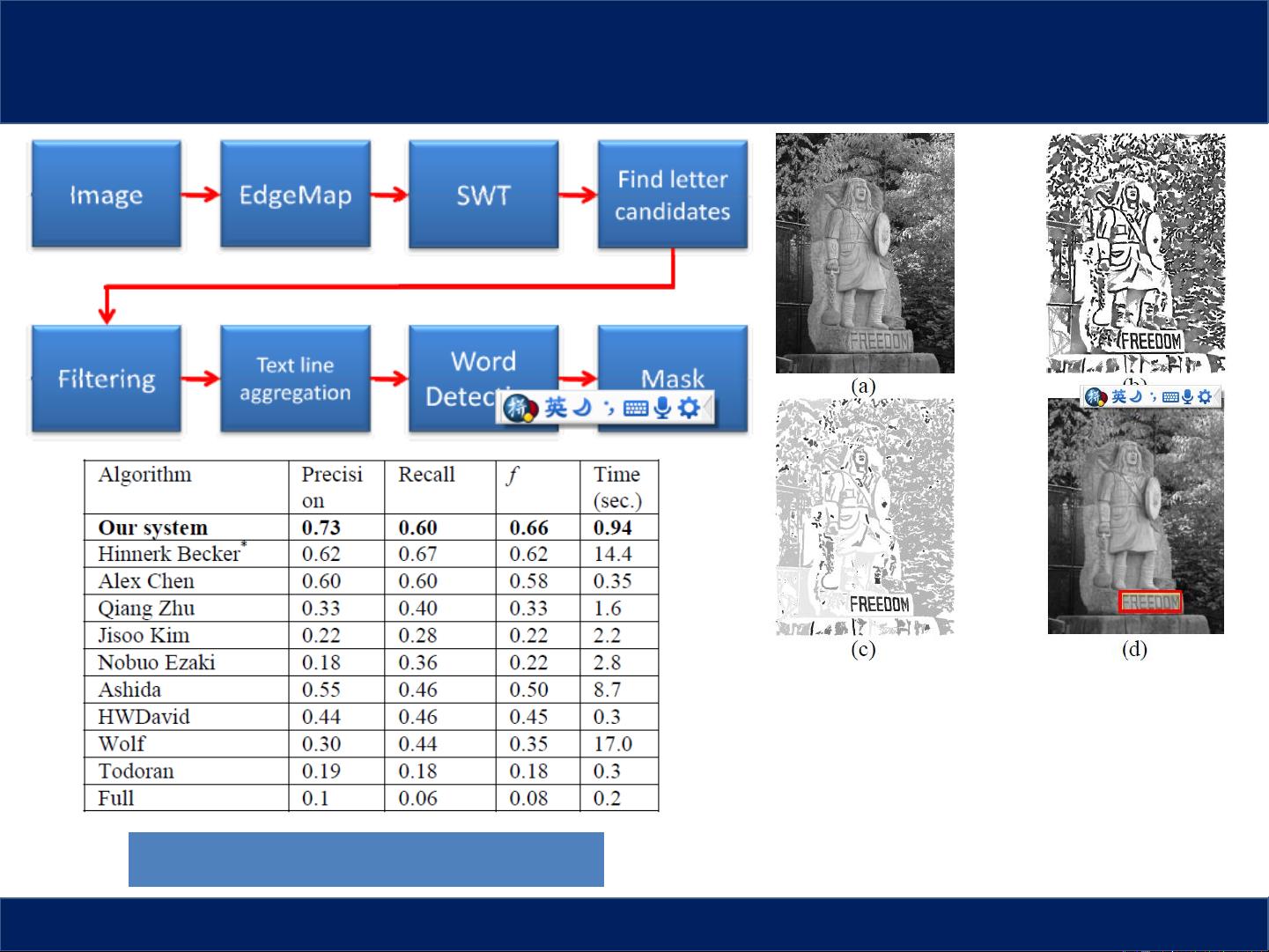
在传统的非CNN和RNN方法中,如Epshtein、Ofek和Wexler在2010年的CVPR会议上提出的StrokeWidthTransform算法,利用笔画宽度信息来检测自然场景中的文本。他们使用的数据集是Microsoft的研究资源,包含大量标注的字符样本,展示了这一方法在ICDAR数据集上的表现。尽管这种方法不依赖于复杂的CNN,但其性能受限于计算成本和准确度之间的权衡。
Google的Photo OCR技术在ICCV 2013年被提及,采用了Viola-Jones和MRF检测器,以及霍夫特征(HOG)和多层全连接网络(5层,结构为422-960-480-480-480-4800-100)。该系统训练集包含大量的手动标注字符,通过数据增强增加了约4百万个字符,使得模型能够从5百万张图片中找到20万个匹配。通过这种方式,他们构建了一个大规模的有标签字符集,进一步提升了模型的性能。
ICDAR 2013 Scene Text比赛和UCSD街景数据集展示了在实际场景下应用OCR和Text Spotting的挑战。尽管CNN由于其更高的准确性,如在2014年ICCV会议上的VGG模型,被认为是更优的选择,但作者指出,考虑到计算资源的限制,当时CNN的应用可能还没有完全发挥出其潜力。
总结来说,OCR和Text Spotting的发展经历了从基于传统特征的手动方法到深度学习驱动的自动特征提取的转变。尽管深度学习带来了显著的性能提升,但传统方法如StrokeWidthTransform仍然在特定场景下具有价值。未来的研究可能会继续探索如何平衡计算效率和准确性,以实现在更大规模和复杂环境下的高效和精确文本识别。
Liangliang Cao
Stroke Width Transform
3
Epshtein, Ofek, and Wexler, Detecting
Text in Natural Scenes with Stroke
Width Transform, CVPR 2010.
Dataset: research.microsoft.com/en-
us/um/people/eyalofek/text_detection_da
tabase.zip
Performance on ICDAR dataset
剩余10页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-11-20 上传
2020-04-29 上传
2020-12-23 上传
2021-05-31 上传
2019-08-29 上传
2018-03-21 上传

abcdezhao2008
- 粉丝: 1
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
