Pandas统计分析在机器学习中的应用
版权申诉
15 浏览量
更新于2024-06-28
收藏 3.64MB PPTX 举报
“机器学习--pandas统计分析.pptx”主要涵盖了使用Python的pandas库进行数据统计分析的内容,特别是围绕Series和DataFrame两种核心数据结构展开。这份资料旨在提升学习者在物流人工智能和机器学习领域的数据分析技能,通过实践教学激发技术创新,并对产业变革产生积极影响。
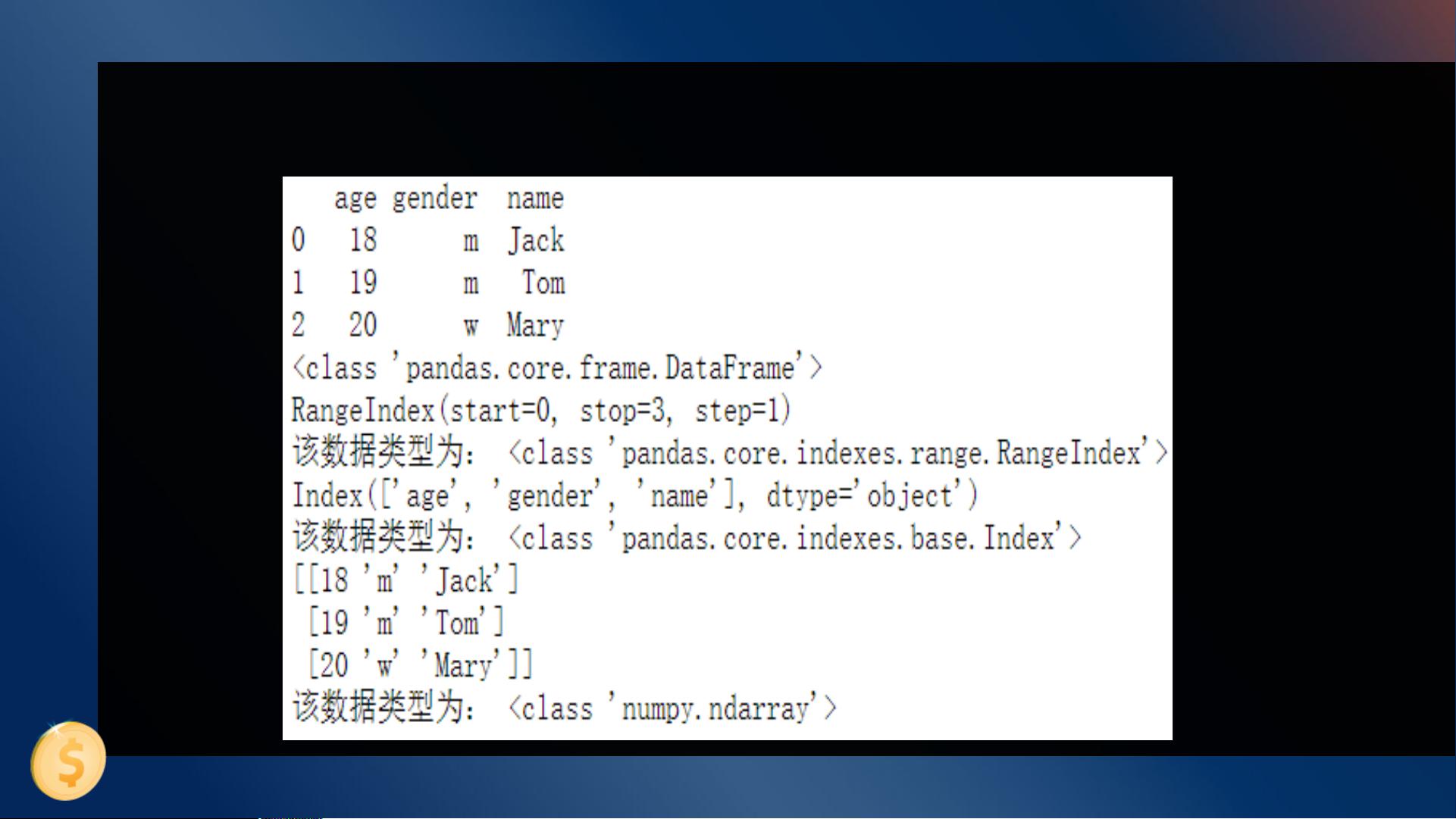
1. **Series**: Series是pandas的基础数据结构之一,它类似于一维数组或字典。Series可以由字典创建,其中字典的key作为索引(index),values作为数据。Series具有名称属性,可以设置别名。Series支持多种索引方式,包括位置下标(类似序列)和标签索引(使用index的字符串)。切片和布尔型索引也是Series的重要操作,允许基于条件选取数据。
2. **DataFrame**: DataFrame是更复杂的数据结构,可以理解为带有列标签的二维表格。它可以通过多种方法创建:
- 1) 由数组或list组成的字典创建,使用`pandas.DataFrame()`。
- 2) 由Series组成的字典创建。
- 3) 直接通过二维数组创建。
DataFrame有行索引和列索引,可以选择特定行和列进行操作。`df.loc[]`用于按index选择行,支持布尔型索引和多重索引,即同时索引行和列。
3. **DataFrame的常用操作**:这部分内容详细介绍了DataFrame的数据操作,如查看数据、转置、对齐和排序等。数据查看包括使用`head()`, `tail()`, `describe()`等函数;转置使用`transpose()`或`.T`属性;对齐操作确保两个DataFrame的索引匹配;排序功能允许按照指定列或索引进行升序或降序排列。
4. **统计分析**: 在机器学习中,pandas提供了丰富的统计功能,如描述性统计(均值、中位数、标准差等)、时间序列处理、排序和算术运算等。这些统计分析对于数据预处理、特征工程和模型评估至关重要,尤其是在物流人工智能领域,有助于优化运输路径、预测需求和降低成本。
5. **实践与教学**:通过实际案例和练习,学习者可以加深对pandas的理解,提高数据分析能力,为创新提供数据支持,进而影响物流行业的技术进步和效率提升。
总结,这个资料是针对机器学习和物流人工智能领域中使用pandas进行数据统计分析的教程,旨在通过理论与实践相结合的方式,帮助学习者掌握高效的数据处理技能,促进技术和产业的发展。



2021-01-20 上传
2024-04-17 上传
2023-08-03 上传
2023-05-09 上传
2024-05-16 上传
2023-05-27 上传
2023-09-10 上传

知识世界
- 粉丝: 368
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
