统一渲染架构GPU性能模型:量化处理效率与误差分析
130 浏览量
更新于2024-08-31
收藏 755KB PDF 举报
本文主要研究了统一渲染架构GPU图形处理的量化性能模型,随着GPU技术的快速发展,从早期的固定功能流水线到统一渲染架构,其运算、存储资源日益丰富,但同时也对软件优化提出了更高的挑战。统一渲染架构GPU的特点在于它的并行计算、流水线结构、数据通信和存储结构的复杂性,使得传统的性能评估方法已不再适用。
文章首先回顾了GPU的发展历程,强调了统一渲染架构在提升图形处理能力中的关键作用,尤其是在NVIDIA和AMD等公司的推动下。然而,这些研究大多属于商业机密,对于公开的研究资料相对匮乏。在国内,虽然有理论探讨集中在并行计算和编程优化上,但对于GPU设计本身的深入研究却较为不足。
作者针对这一空白,构建了一个量化性能模型,该模型围绕统一渲染架构GPU的核心组件展开,包括图形指令生成、主机接口数据传输、图形指令解析、图形处理流水数据吞吐以及统一染色阵列处理能力。这些因素共同决定了GPU的图形处理性能。通过仿真验证,模型在设计自主知识产权GPU时展现了良好的有效性,与实际测量的性能误差控制在7.5%以内,这对于GPU的设计者和优化者来说具有重要的实践指导意义。
在模型的具体实现上,文章以NVIDIA的GeForce 8800为例进行分析,这款产品代表了统一渲染架构的里程碑,它的发布标志着GPU处理方式的重大转变。通过对这款产品的剖析,作者揭示了统一渲染架构GPU的图形处理流程和关键技术细节,为后续的性能参数设计提供了实用的方法论。
总结来说,本文的研究不仅填补了国内在统一渲染架构GPU性能研究上的空白,还为GPU设计者提供了一套科学的量化性能评估工具,有助于提升图形处理效率,推动GPU技术的进一步发展。
统一渲染架构统一渲染架构GPU图形处理量化性能模型研究图形处理量化性能模型研究
统一渲染架构GPU为图形处理提供了丰富的运算、存储资源,也对软件优化提出了更高要求。为了有效地进行
性能设计和优化,针对统一渲染架构实现的GPU 提出一种量化的图形处理性能模型,在深入研究统一渲染架构
GPU架构和工作原理基础上,分析影响图形处理的各种因素:图形指令生成、主机接口数据传输、图形指令解
析、图形处理流水数据吞吐和统一染色阵列处理能力。通过仿真验证表明,在研制自主知识产权GPU过程中,
采用本方法设计各部分性能指标,评估统一染色GPU图形处理性能与实测相比,误差小于7.5%。
0 引言引言
从1999年NVIDIA发布第一款GPU产品至今,GPU技术发展主要经历了固定功能流水线阶段、分离染色器架构阶段、统一
染色器架构阶段
[1]
。其处理架构的不断改变使得图形处理能力和计算能力不断提升,相应的流水线结构、并行计算结构、并行
数据通信结构、存储结构越发复杂,图形处理性能指标已难以从单方面去设计、评价。研究GPU图形处理性能模型意义重
大。
国外NVIDIA、AMD等公司针对GPU图形处理性能方面进行了大量研究,但都是各公司的核心机密,公开甚少
[2]
。国内在统
一渲染架构GPU性能方面进行了一定理论探讨,但主要集中在并行计算、存储结构、编程优化方面,针对GPU设计本身的研
究几乎空白。
本文提出统一渲染架构GPU图形处理量化性能模型,在分析统一渲染架构GPU并行架构和工作原理基础上,分析影响图形
处理的各种因素:图形指令生成、主机接口数据传输、图形指令解析、图形处理流水数据吞吐和统一染色阵列处理能力。为统
一渲染架构GPU的性能参数设计提供方法支持。
1 统一渲染架构统一渲染架构GPU图形处理模型图形处理模型
图形处理器经过近30年的发展,虽然图形处理器体系结构、处理方式发生了巨大变化,但其基于Z-Buffer的光栅化图形处理
流水线一直沿用至今
[3]
。自2006年,NVIDIA发布统一渲染架构的GPU以来,统一渲染架构便成为GPU的主流
[4]
。NVIDIA、
AMD等各厂家都有自己不同的实现方式,但基本的CPU+GPU异构工作方式、图形处理流程都基本一致
[5-6]
。下文将在分析代
表产品的基础上,针对图形处理性能抽象统一渲染架构GPU图形处理模型。
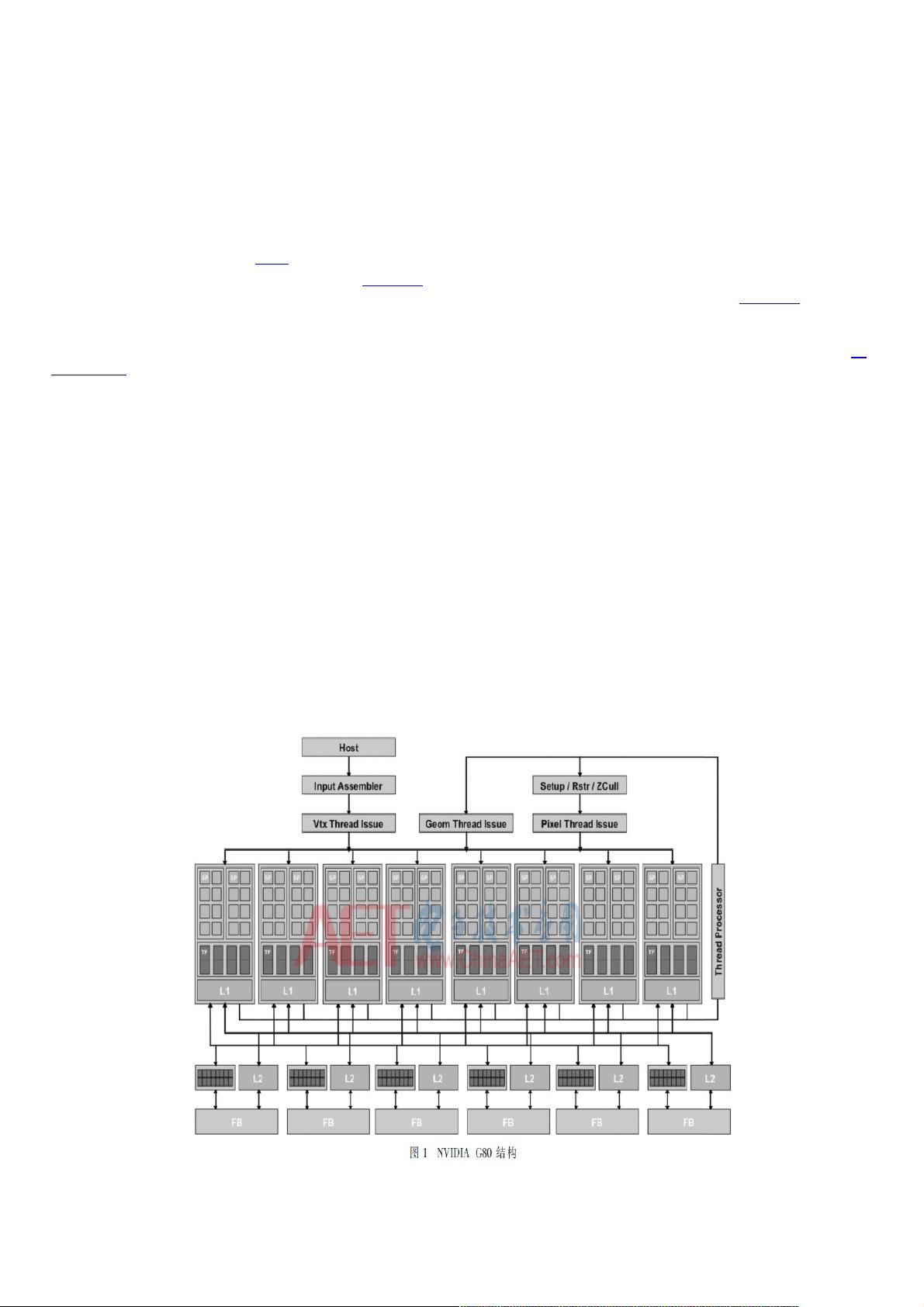
1.1 GeForce 8800
GeForce 8800是2006年NVIDIA发布的第一款统一染色架构GPU,采用G80架构
[7]
。自此NVIDIA每两年发布一款GPU架
构。2006年发布G80,2008年发布Tesla-GT200,2010年发布Fermi-GF100,2012年发布kepler,2014年发布年
Maxwell,2016年发布Pascal。每一款GPU架构都对染色阵列数量及结构进行优化、调整,但图形处理过程改变甚微,基本保
持着G80的处理过程,如图1所示。
图形处理任务由主机生成图形指令存储到主机内存中,GPU通过主机接口获取图形指令,然后将图形指令解析为统一染色
阵列和固定的硬件单元的控制和数据信息,配合完成图形处理过程。
1.2 R700
下载后可阅读完整内容,剩余8页未读,立即下载
2021-09-25 上传
2015-08-30 上传
2021-09-25 上传
2024-11-04 上传
2024-12-02 上传
2025-02-25 上传
2025-02-10 上传
2024-12-30 上传
2021-09-20 上传

weixin_38657290
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
