Python爬虫实践:壁纸批量下载器的实现
22 浏览量
更新于2024-08-28
收藏 621KB PDF 举报
"该资源是一个Python编程实例,用于批量下载壁纸的爬虫项目,作者在学习Python的过程中创建了这个项目,旨在提供一个实践平台。项目使用了virtualenv管理环境,确保开发过程不会影响全局环境。主要涉及的技术包括BeautifulSoup和requests库,用于网页抓取和数据交互。"
在Python编程中,批量下载壁纸的任务通常涉及到网络爬虫技术。在这个项目中,作者使用了Python的`requests`库来发送HTTP请求,获取网页内容,以及`BeautifulSoup`库来解析HTML文档,提取所需信息。`requests`库使得我们能够方便地与Web服务器进行通信,而`BeautifulSoup`则帮助我们解析返回的HTML,找到我们需要的数据,例如壁纸的链接。
首先,为了保持开发环境的整洁,项目采用了`virtualenv`来创建一个独立的Python环境。通过运行`pip3 install virtualenv`安装`virtualenv`,然后在项目目录下创建一个名为`venv`的虚拟环境,并激活它。激活虚拟环境的命令是`.venv/bin/activate`。这样可以确保项目的依赖不会影响到全局的Python环境。
接着,创建一个`requirements.txt`文件,列出项目所依赖的库,如`bs4`(BeautifulSoup的别名)和`lxml`、`requests`,并使用`pip3 install -r requirements.txt`安装这些库。这样确保了所有必要的库都已安装且版本正确。
爬虫工作的主要步骤包括:
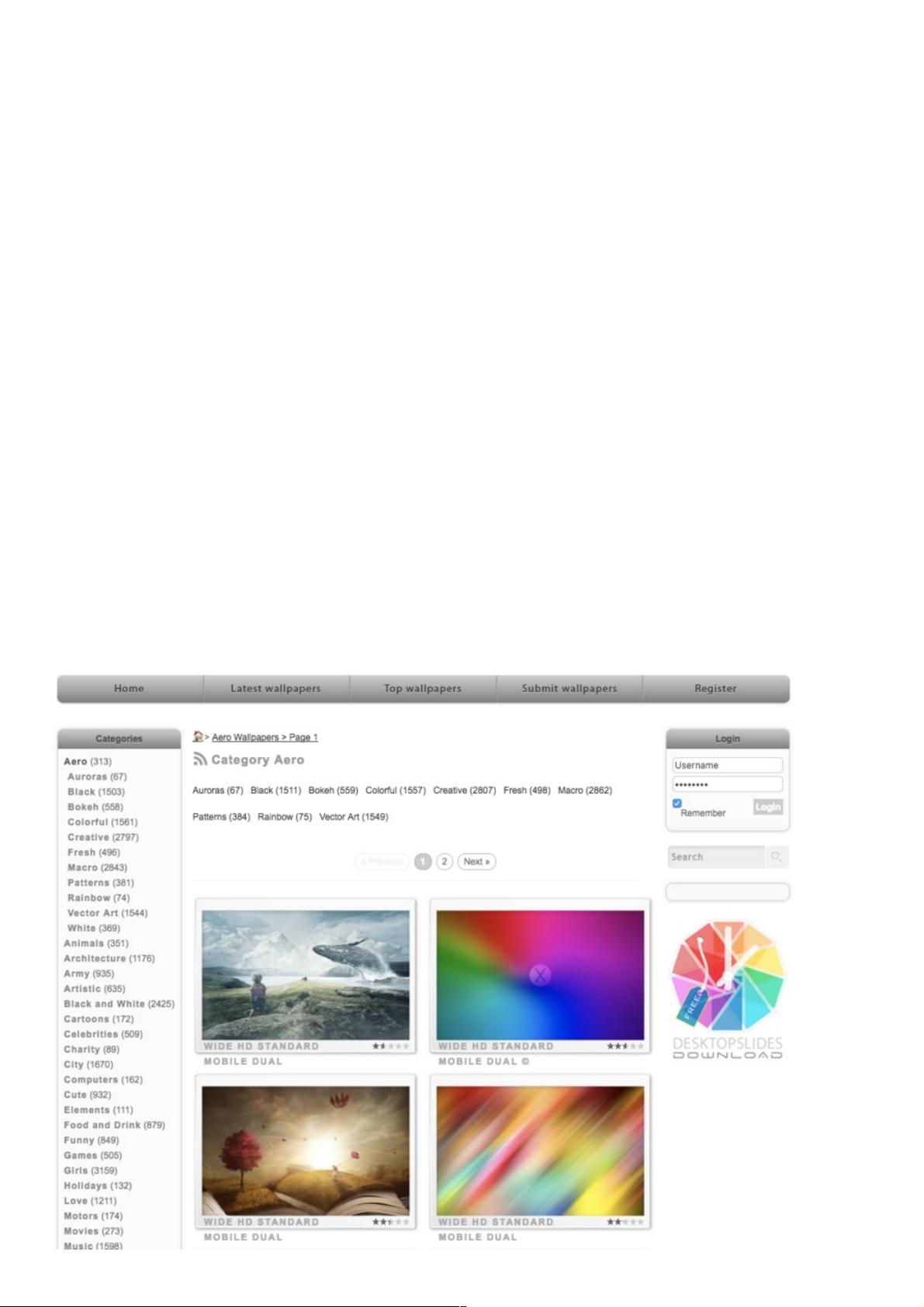
1. 访问壁纸列表页,例如`http://wallpaperswide.com/aero...`,抓取每张壁纸的缩略图链接。
2. 针对每个缩略图链接,进一步访问壁纸详情页,寻找高清壁纸的下载链接。
3. 识别并提取高清壁纸的URL,通常是根据页面元素的特性(如文件大小或分辨率标签)来判断。
4. 下载高清壁纸,通常使用`requests`库的`get`方法,将响应的二进制内容保存到本地文件。
在`download.py`文件中,作者定义了`visit_page`函数,用于发送HTTP GET请求并获取页面内容。这个函数通常会设置`User-Agent`头以模仿浏览器行为,避免被网站服务器识别为爬虫并阻止。
完整的爬虫程序还会包含解析HTML、提取链接、处理下载逻辑等其他功能。在实际的代码中,作者可能会使用`BeautifulSoup`解析返回的HTML,找到所有壁纸的详细页面链接,然后对每个链接调用`visit_page`,再次解析详情页以找到高清壁纸的下载链接。最后,通过`requests`库的`get`方法下载图片,并将其保存到本地的指定文件夹。
这个项目是一个很好的Python爬虫实践示例,适合初学者学习网络爬虫的基础知识,同时也展示了如何使用Python来处理Web数据和自动化下载任务。需要注意的是,进行网络爬虫时应遵守网站的robots.txt文件规定,尊重版权,并确保合法合规使用数据。
python实现壁纸批量下载代码实例实现壁纸批量下载代码实例
项目地址:https://github.com/jrainlau/wallpaper-downloader
前言
好久没有写文章了,因为最近都在适应新的岗位,以及利用闲暇时间学习python。这篇文章是最近的一个python学习阶段性总
结,开发了一个爬虫批量下载某壁纸网站的高清壁纸。
注意:本文所属项目仅用于python学习,严禁作为其他用途使用!
初始化项目
项目使用了virtualenv来创建一个虚拟环境,避免污染全局。使用pip3直接下载即可:
pip3 install virtualenv
然后在合适的地方新建一个wallpaper-downloader目录,使用virtualenv创建名为venv的虚拟环境:
virtualenv venv
. venv/bin/activate
接下来创建依赖目录:
echo bs4 lxml requests > requirements.txt
最后yun下载安装依赖即可:
pip3 install -r requirements.txt
分析爬虫工作步骤
为了简单起见,我们直接进入分类为“aero”的壁纸列表页:http://wallpaperswide.com/aer…。
下载后可阅读完整内容,剩余4页未读,立即下载
2022-04-28 上传
2020-09-19 上传
点击了解资源详情
2020-12-17 上传
2020-09-18 上传
2020-09-17 上传
2020-09-18 上传
2020-09-20 上传
2020-09-21 上传

weixin_38643127
- 粉丝: 8
- 资源: 921
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
