Flink深度解析:入门到实战文档
需积分: 5 67 浏览量
更新于2024-07-15
收藏 2.64MB PDF 举报
Flink超神文档深入解析了Apache Flink这一强大的流处理和批处理框架。Flink是一款开源的实时数据流处理系统,专为低延迟、高吞吐量和容错性而设计,适用于大规模分布式环境。它支持两种主要的数据流类型:无界流(UnboundedStreams)和有界流(BoundedStreams),前者处理持续不断的数据流,后者处理有限长度的数据集。
在Flink中,stateful computations是关键特性,它允许系统维护状态信息以进行复杂的计算,如窗口操作和迭代处理。Flink的主要用户包括数据科学家、开发者和运维人员,他们可以利用Flink的实时处理能力构建实时分析应用和复杂的工作流。
Flink的安装与部署部分详细介绍了在Standalone集群和Hadoop YARN上运行Flink的方法。Standalone模式适合小规模测试,而YARN模式则适用于大规模生产环境,提供了session和run a Flink job两种运行模式,分别对应不同的资源管理和生命周期管理。
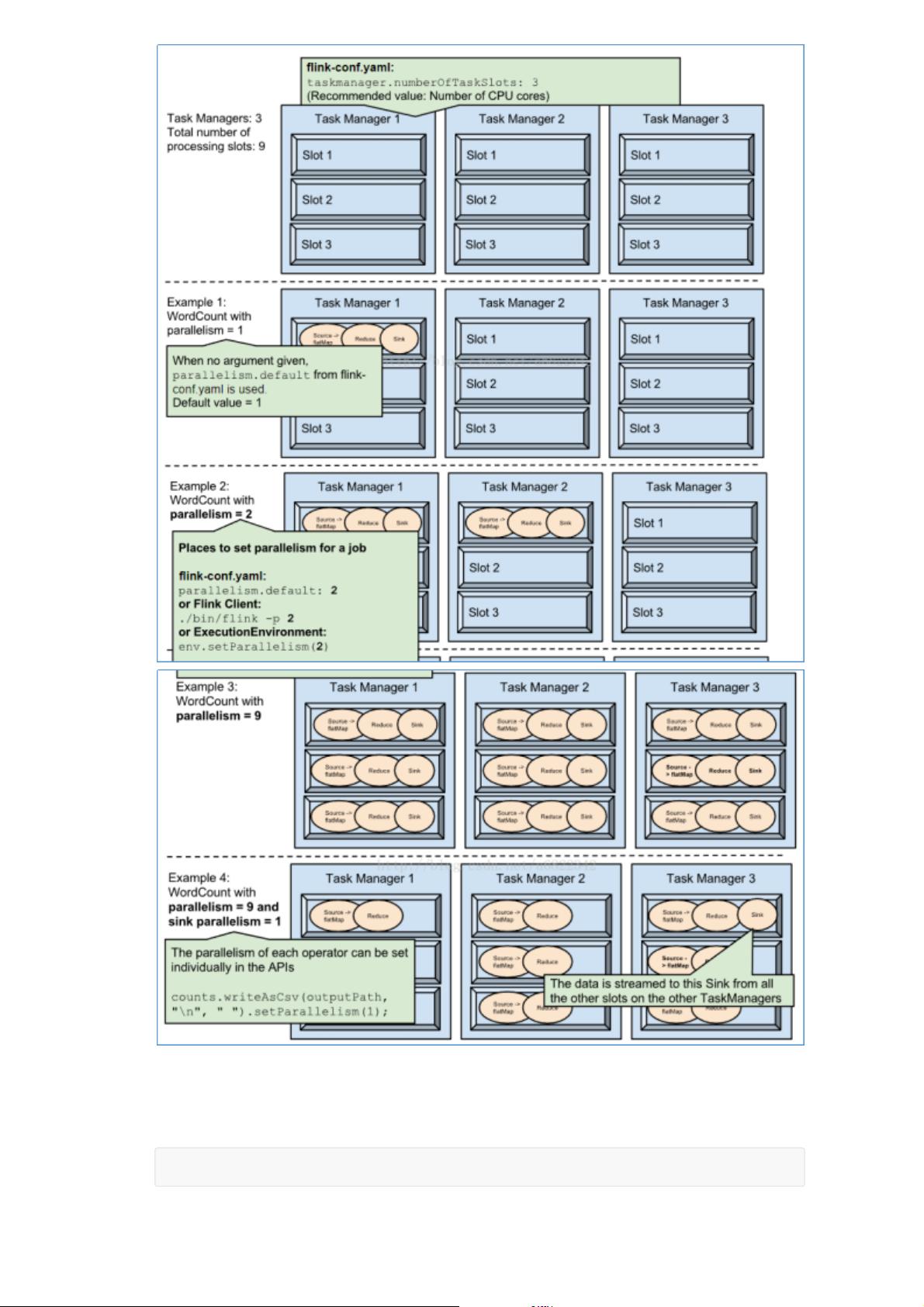
Flink API详解深入浅出,包括Dataflows(数据流图)的概念,以及如何配置开发环境。例如,常见的算子如Map、FlatMap、Filter、KeyBy、Reduce和聚合操作都有所涉及。Flink的任务调度规则和并行度设置是优化性能的重要环节,同时支持各种数据源,如文件、集合、Socket、Kafka和自定义源。
Flink的数据流处理还支持高级特性,如迭代处理(Iterate)和函数类,包括ProcessFunction API,这些为复杂业务逻辑提供了丰富的表达能力。此外,数据流的分区策略是确保数据分布均匀和性能优化的关键,如shuffle、rebalance、rescale等策略。
FlinkState管理是Flink的核心,它包括CheckPoint和SavePoint两种持久化机制,以及不同的状态后端选项,如内存存储。CheckPoint用于定期保存状态,SavePoint则是在特定时间点进行保存,而MemoryStateBackend适用于内存容量充足的场景。
Flink超神文档全面覆盖了Flink的基础概念、安装部署、API使用、高级特性和状态管理,为理解和运用Flink提供了详尽的指南,无论你是初次接触还是资深开发者,都能从中受益匪浅。
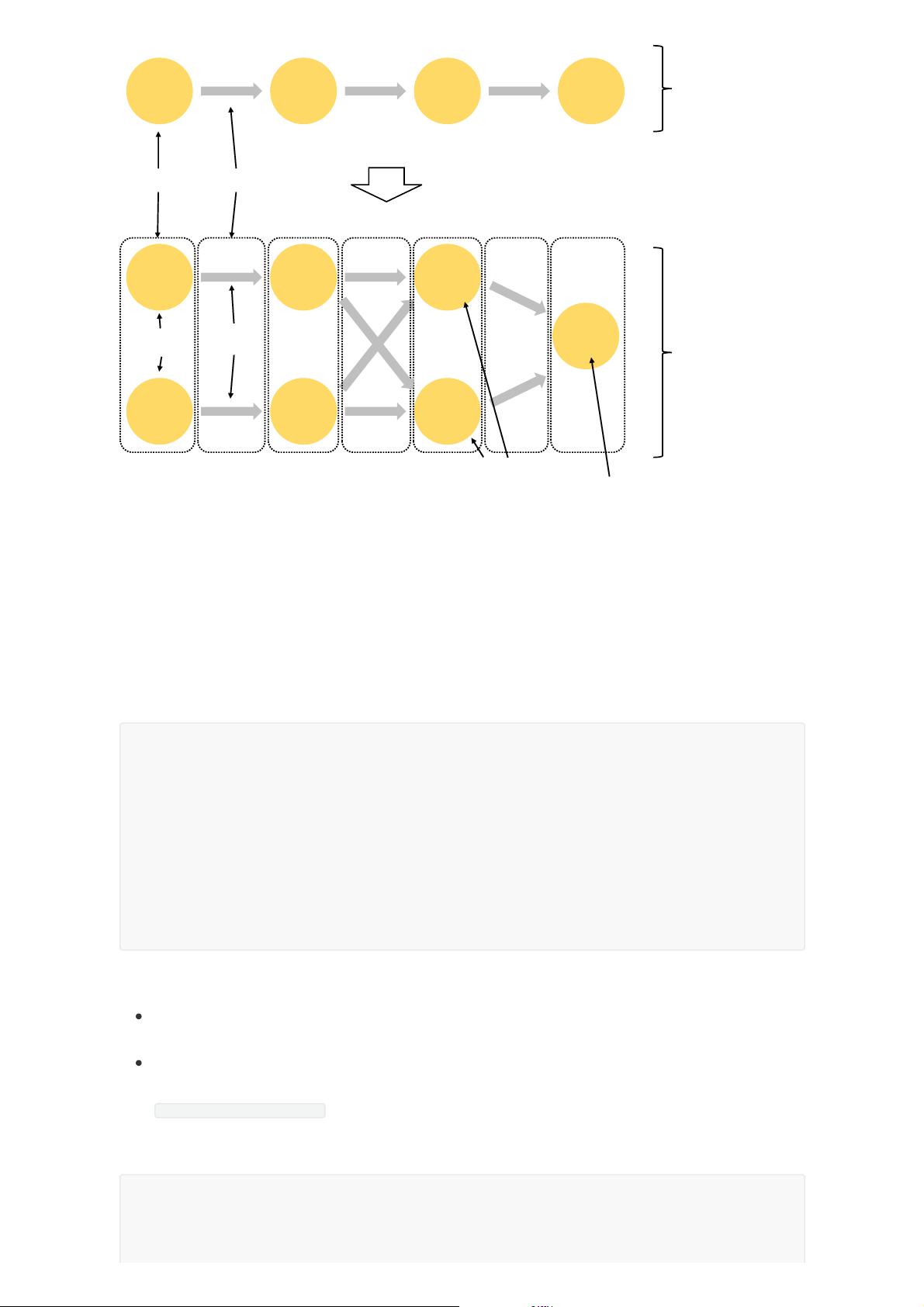
Source map()
keyBy()/
window()/
apply()
Sink
Operator
Subtask
Source
[1]
map()
[1]
keyBy()/
window()/
apply()
[1]
Sink
[1]
Source
[2]
map()
[2]
keyBy()/
window()/
apply()
[2]
Stream
Partition
Operator Stream
Streaming Dataflow
(parallelized view)
Streaming Dataflow
(condensed view)
parallelism = 1
parallelism = 2
配置开发环境
每个 Flink 应用都需要依赖一组 Flink 类库。Flink 应用至少需要依赖 Flink APIs。许多应用还会额外依
赖连接器类库(比如 Kafka、Cassandra 等)。 当用户运行 Flink 应用时(无论是在 IDEA 环境下进行测
试,还是部署在分布式环境下),运行时类库都必须可用
开发工具:IntelliJ IDEA
配置开发Maven依赖:
注意点:
如果要将程序打包提交到集群运行,打包的时候不需要包含这些依赖,因为集群环境已经包含了这
些依赖,此时依赖的作用域应该设置为provided provided
Flink 应用在 IntelliJ IDEA 中运行,这些 Flink 核心依赖的作用域需要设置为 compile 而不是
provided 。 否则 IntelliJ 不会添加这些依赖到 classpath,会导致应用运行时抛出
NoClassDefFountError 异常
添加打包插件:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<build>
<plugins>
<plugin>
剩余86页未读,继续阅读
2019-10-25 上传
2022-03-02 上传
2022-08-16 上传
2023-06-02 上传
2019-05-21 上传
2022-01-18 上传
2023-03-21 上传
132 浏览量

柯南721
- 粉丝: 54
- 资源: 37
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
