Scrapy框架详解:爬虫工作流程与组成部分
需积分: 18 185 浏览量
更新于2024-09-11
收藏 1014KB PDF 举报
Scrapy框架精讲是一份深入解析Scrapy爬虫框架的工作流程和技术细节的教程。首先,它回顾了爬虫的基本原理,明确了爬虫的本质是定位网页元素并获取数据,其一般工作流程包括分析需求、确定目标网站、分析URL结构、构建请求列表、通过网络抓取、解析数据以及数据入库。其中,数据可以分为结构化数据如二维表格形式(如CSV)和非结构化数据,后者难以用传统表格逻辑表示。
Scrapy的优势在于它提供了一种高效的方式来编写爬虫,仅需编写少量代码就能实现大规模数据抓取,这对于爬虫工程师来说是一项基础且重要的技能。Scrapy框架主要由以下几个关键组件构成:
1. 引擎(Engine):作为核心组件,引擎主要负责数据和信号在不同模块之间的传递,但并不处理数据的具体操作,而是起到信息传输的作用。
2. 调度器(Scheduler):它充当了一个请求队列,接收引擎发送的Request对象,确保爬虫按照预定顺序执行。
3. 下载器(Downloader):负责发送请求到目标服务器并获取响应,然后将响应传递给引擎,是网络请求的实际执行者。
4. 爬虫(Spider):处理引擎返回的Response,提取所需数据,构造新的请求,并将它们返回给引擎。这是爬虫的核心逻辑部分。
5. 管道(Pipeline):对引擎传递的数据进行进一步处理,例如清洗、转换格式或存储到数据库等,提供了灵活的数据处理能力。
6. 下载中间件(Downloader Middleware):允许用户自定义下载过程,如设置代理IP,增加了爬虫的灵活性和可扩展性。
7. 爬虫中间件(Spider Middleware):用于过滤和定制请求和响应,提供了更精细的控制,如请求前的预处理和响应后的筛选。
使用Scrapy框架涉及实际操作步骤,首先需要安装Scrapy,可以通过命令`pip install scrapy`完成。然后,创建一个新的Scrapy项目,以便组织和管理爬虫代码。开发者可以在此基础上编写自己的爬虫,根据需求配置不同的中间件和管道,实现高效的网页数据抓取和处理。
Scrapy框架是一个强大的工具,它简化了爬虫开发过程,尤其适合处理大规模、复杂的数据获取任务。通过理解其工作原理和组成部分,开发者能够更好地设计和优化自己的爬虫项目。
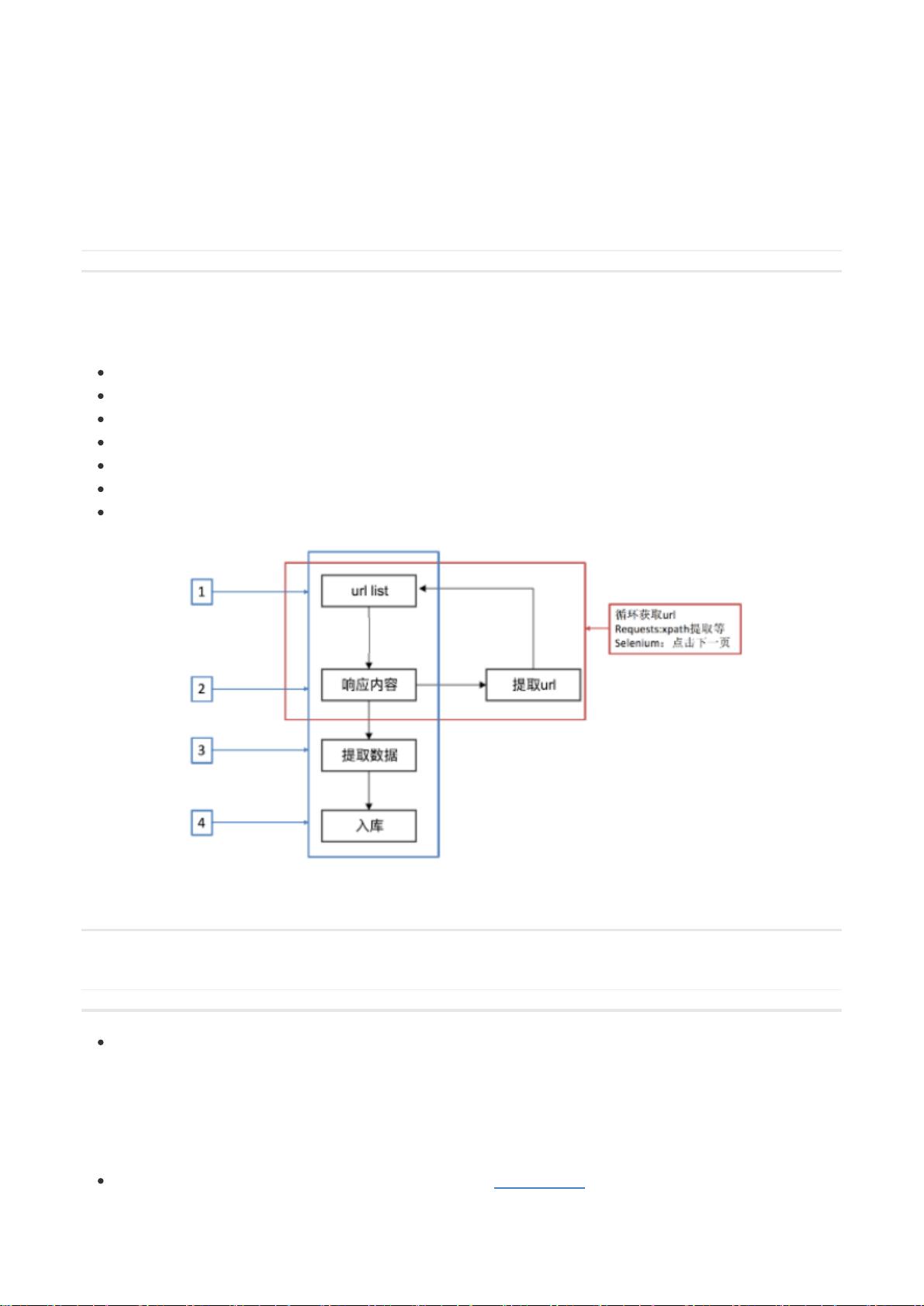
爬虫原理回顾:
1、爬虫的本质:定位元素,获取页面数据
2、爬虫的一般工作流程:
分析需求
确定目标网站
分析目标网站的url组成规则
将需要爬取的目标页面组建成url列表
通过循环不断地提取url,让目标服务器不断地给我们响应
解析数据、提取数据
数据入库
补充拓展:
结构化数据:行数据,可以用二维表结构来逻辑表达实现的数据。
包括csv文件等等
1997,Ford,E350,"ac, abs, moon",3000.00 1999,Chevy,"Venture ","Extended Edition",4900.00
1999,Chevy,"Venture ","Extended Edition, Very Large",5000.00 1996,Jeep,Grand Cherokee,"MUST
SELL!"
非结构化数据:不方便用二维逻辑表来表现的数据即称为非结构化数据,
下载后可阅读完整内容,剩余6页未读,立即下载
2021-12-01 上传
2023-03-14 上传
2020-04-03 上传
2021-11-06 上传
2022-02-05 上传

MrHe96
- 粉丝: 3
- 资源: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- katarina
- conflict-practice-debbiev123:让我们解决一些冲突
- warrio:warr.io 的投资组合网站
- Amplifyapp
- Kaue-G:关于我
- conflict-practice-arnitha-b:让我们解决一些冲突
- 行业文档-设计装置-一种切纸机高精度定位装置.zip
- CordovaIonicMobileFirst:我的演示文稿的回购-等待-Cordova和Ionic和MobileFirst
- 基于Mixare,使用OpenGL重写了Mixare的算法。.zip
- STM32编程实现直流有刷电机位置速度电流三闭环PID控制.zip
- decimal-to-roman-converter
- trailer-marvel:Aqui se passa a ordem dos filmes da marvel e junto os预告片
- 前端基础在线2021年1月
- 移远4G网络模块开发设计资料
- ngtrumbitta-services-lodash:将Lodash注入任何Angular应用程序中,并通过旧的_处理程序使用它
- 基于react+parcel和vue+webpack的通用领卷系统.zip
