Apache Hive性能优化指南-HDP3.1.0
需积分: 10 164 浏览量
更新于2024-07-09
收藏 805KB PDF 举报
"Apache Hive Performance Tuning - HDP 3.1.0"
在Apache Hive Performance Tuning中,针对HDP 3.1.0版本,本文档提供了优化Hive数据仓库性能的策略和技巧。Hive是大数据处理领域的一个重要组件,常用于执行SQL查询在Hadoop上存储的数据。以下是一些关键点:
1. **LLAP (Live Long and Process) 配置**:
- LLAP(Live Long and Process)是Hive的一种新架构,它实现了查询的快速响应,通过缓存部分计算结果来提高交互性。
- 在开始调优前,确保对LLAP的基本概念和工作原理有深入理解。
- 设置LLAP端口,这包括HiveServer Interactive和LLAP Daemon的端口配置,以确保服务正常运行。
2. **性能调优准备**:
- 在进行性能调优前,需要对环境进行评估,了解硬件资源、网络状况以及现有工作负载。
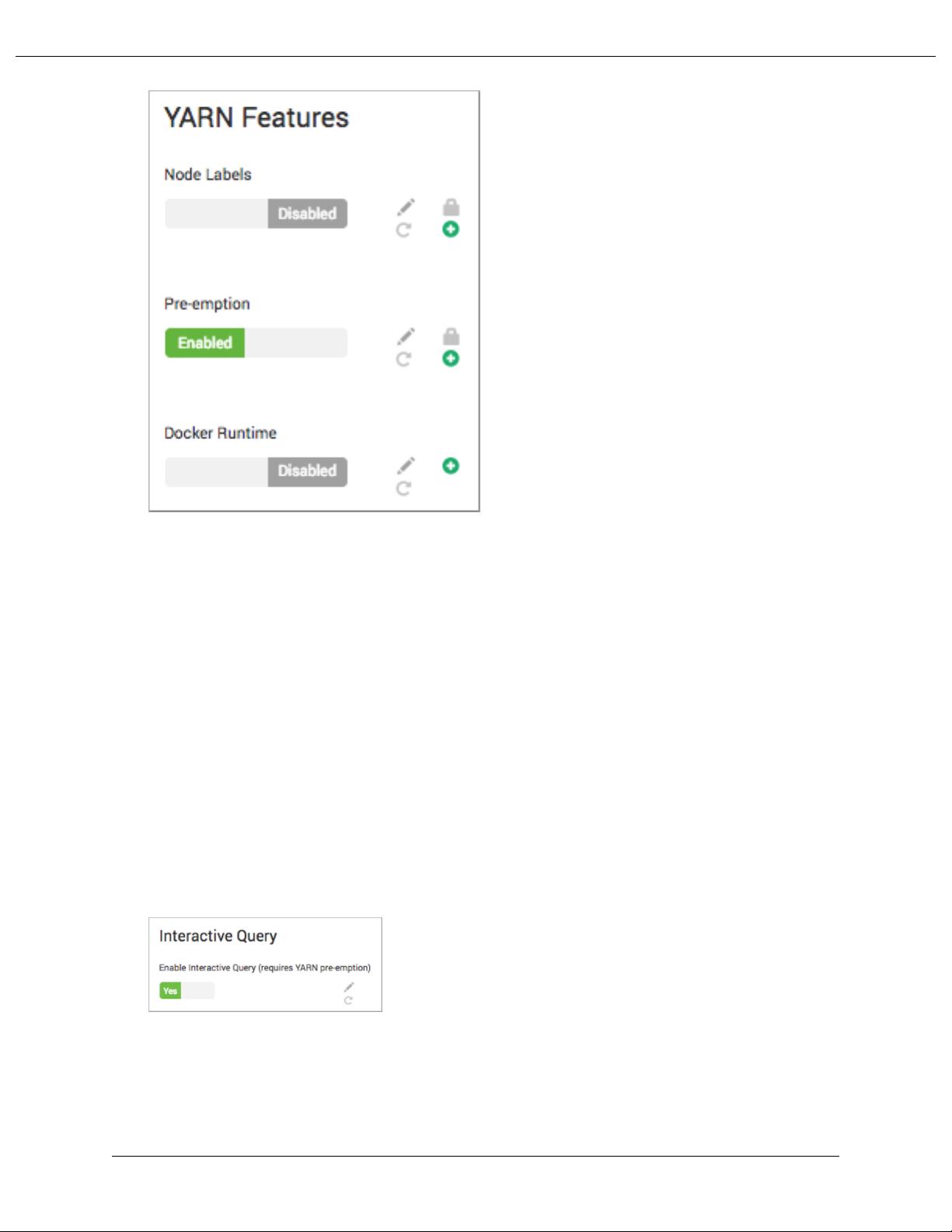
- 启用YARN预占,允许高优先级任务抢占低优先级任务的资源,提高交互式查询响应时间。
3. **设置LLAP**:
- 启用YARN的交互式查询模式,使Hive更适合处理即时查询需求。
- 设置多个HiveServer Interactive实例以实现高可用性,确保服务不会因单点故障而中断。
- 配置LLAP队列,根据工作负载类型分配合适的资源。
- 设置Hive代理,允许用户通过HiveServer2进行安全访问。
4. **其他LLAP属性**:
- 配置LLAP相关的其他属性,如内存分配、线程池大小等,以优化LLAP Daemon的行为。
- 调整HiveServer的堆大小,确保足够的内存供查询处理使用。
5. **保存并重启服务**:
- 一旦所有配置完成,记得保存设置并重启相关服务以应用更改。
- 运行一个交互式查询,验证性能是否有所改善。
6. **使用HiveServer Interactive UI和JDBC客户端**:
- 通过HiveServer Interactive UI监控查询性能,并进行故障排查。
- 使用JDBC客户端连接到LLAP,以便于开发和测试。
7. **YARN队列配置**:
- 针对批处理和交互式查询,分别配置不同的YARN队列,确保资源合理分配。
- 创建自定义LLAP队列,进一步精细化资源管理。
8. **Hive仓库处理的关键组件**:
- 查询结果缓存和元数据缓存可显著提高查询速度,减少不必要的数据读取。
- Tez执行引擎的属性配置也对性能有直接影响。
9. **监控Hive性能**:
- 监控LLAP资源,包括内存使用、CPU利用率和队列状态,以便及时发现和解决问题。
- 使用Hadoop的监控工具(如Ambari)来跟踪Hive和YARN的性能指标。
10. **最大化存储资源使用ORC**:
- ORC(Optimized Row Columnar)是Hive的一种高效存储格式,可以压缩数据,提高读写速度。
- 配置高级ORC属性,如压缩级别、 stripe大小等,以优化存储和I/O性能。
11. **利用分区提升性能**:
- 数据分区是提高查询性能的有效方法,通过将数据划分为更小、更易管理的部分,可以加速特定条件的查询。
- 避免过度分区,以免增加元数据负担和复杂性。
12. **处理大表和倾斜表**:
- 对于大数据量的表,可能需要考虑分桶、索引或使用MapReduce优化。
- 处理倾斜表时,需采取特殊策略,如倾斜键处理,以避免某些分区或节点过载。
这些是优化Hive性能的关键步骤,通过综合应用这些技术和策略,可以在HDP 3.1.0环境中显著提高Hive数据仓库的性能和响应速度。
Data Access Setting up LLAP
3.
Save the settings.
Enable interactive query
You need to enable interactive query to take advantage of low-latency analytical processing (LLAP) of Hive queries.
When you enable interactive query, you select a host for HiveServer Interactive.
About this task
The Interactive Query control displays a range of values for default Maximum Total Concurrent Queries based on the
number of nodes that you select for LLAP processing and the number of CPUs in the Hive LLAP cluster. The Ambari
wizard typically calculates appropriate values for LLAP properties in Interactive Query, so accept the defaults or
change the values to suit your environment.
When you enable Interactive Query, the Run as end user and Hive user security settings have no effect. These
controls affect batch-processing mode.
Procedure
1.
In Ambari, select Services > Hive > Configs > Settings.
2.
In Interactive Query, set Enable Interactive Query to Yes:
3.
In Select HiveServer Interactive Host, accept the default server to host HiveServer Interactive, or from the drop-
down, select a different host.
6

剩余32页未读,继续阅读
2022-06-23 上传
2019-06-06 上传
2024-09-16 上传
2024-09-16 上传
2024-09-16 上传
2024-09-16 上传
2021-04-29 上传
2024-09-16 上传

啊彪123
- 粉丝: 23
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
