预训练模型揭示语言隐喻:跨数据集与语言的编码洞察
133 浏览量
更新于2024-06-19
收藏 879KB PDF 举报
预训练语言模型(PLMs)作为当今自然语言处理(NLP)领域的基石,已经在众多应用中展现出强大的表现,包括机器翻译、问答系统、对话管理和情感分析。然而,尽管它们在处理大量文本数据中展现出惊人的能力,但关于它们是否以及如何编码和处理隐喻这一关键的人类思维特征,仍存在研究空白。
隐喻是语言中的核心元素,通过概念隐喻理论(CMT),隐喻被视为认知过程,它在不同概念间建立了非字面的关联。这种关联对于人类理解和创新至关重要,因此在构建能够模仿人类思考的计算系统时,捕捉隐喻至关重要。然而,现有的PLMs是否能有效地捕捉并编码这些隐喻信息,尚未得到充分探究。
本文的主要目标是探索预训练语言模型中隐喻的编码情况,特别是在跨语言和跨文化背景下。研究者选择了英语、西班牙语、俄语和波斯语这四种语言的数据集,通过设计实验来测量PLMs在处理隐喻时的表征能力。实验结果显示,PLMs确实包含了隐喻性知识,尤其是在它们的中间层中,这暗示了模型可能在学习过程中捕捉到了抽象的语义关联。
研究发现,隐喻知识在不同语言和数据集之间具有一定的迁移性,尤其是当训练和测试数据集的注释保持一致时,这种迁移更为显著。这一发现对于认知科学和NLP社区来说,意味着PLMs可能在某种程度上捕捉到了人类认知的共通性,有助于开发更加智能和灵活的NLP系统。
然而,这项工作的局限性在于,它并未深入剖析模型内部的具体机制,也没有提供如何优化模型以更好地捕捉隐喻的指导。未来的研究可能会进一步探讨模型如何处理复杂的隐喻结构,以及如何结合人类语言学理论来改进模型的隐喻理解和生成能力。
总结来说,预训练语言模型中的隐喻探测与概括研究为我们揭示了模型在处理隐喻方面的潜在能力,为理解模型的内部工作原理和提升NLP系统的隐喻理解水平提供了有价值的方向。
+v:mala2277获取更多论
文
hankar等人。(2019a,b)扩展了Conneau等
人的探测任务。(
2018
),其他几种语言。
Pires等人(2019)研究了在执行跨语言下游任
务时跨语言的多语言BERT的在这里,作为我
们 研 究 的 一 部 分 , 我 们 探 讨 了 XLM-R
(
Conneauet al.
,
2020
),一个著名的多语言
PLM
。
分布外泛化。关于隐喻检测中的分布外泛化
现象的研究和评价尚未见报道这种泛化是指测
试和训练集来自不同分布的场 景(Duchi和
Namkoong , 2018; Hendrycks 等 人 ,
2019
)。,
2020a
,
b
)。在这里,我们有测试
和训练数据使用不同语言或域
/
数据集的场
景。这些都是具有挑战性的评估方案的编码信
息的泛化(隐喻在我们的情况下)。
3
PLM中隐喻知识的检验
隐喻在我们的日常语言中被频繁使用语言学和
认知科学都有相关的理论根据语言学理论,隐
喻性主要采用隐喻识别程序(MIP)进行标注.
MIP
识别一个词在给定的上下文中作为隐喻,
如果它有一个基础, 与其上下文相反的原文
或 字 面 意 义 。基 于 概 念 隐 喻 理 论 (CMT )
(Lakoff和Johnson,2008),一个目标域(例
如 , ARGUMENT ) 使 用 源 域 ( 例 如 ,
WAR
)。源域通常更具体或物理,而目标域
则更抽象.联系这两个理论,隐喻是在语言中
表达连接两个对立的领域。例如,在
“
我们赢
得了争论”中“赢”这个词在同样的单词隐喻检
测的任务就是对
“
字面
”
和
“
隐喻
”
进行分类
因此,当设计隐喻检测系统时,为了弄清楚
标记在特定上下文中是否是隐喻,我们假设遵
循如下过程:(i)查找标记是否具有多个含
义,
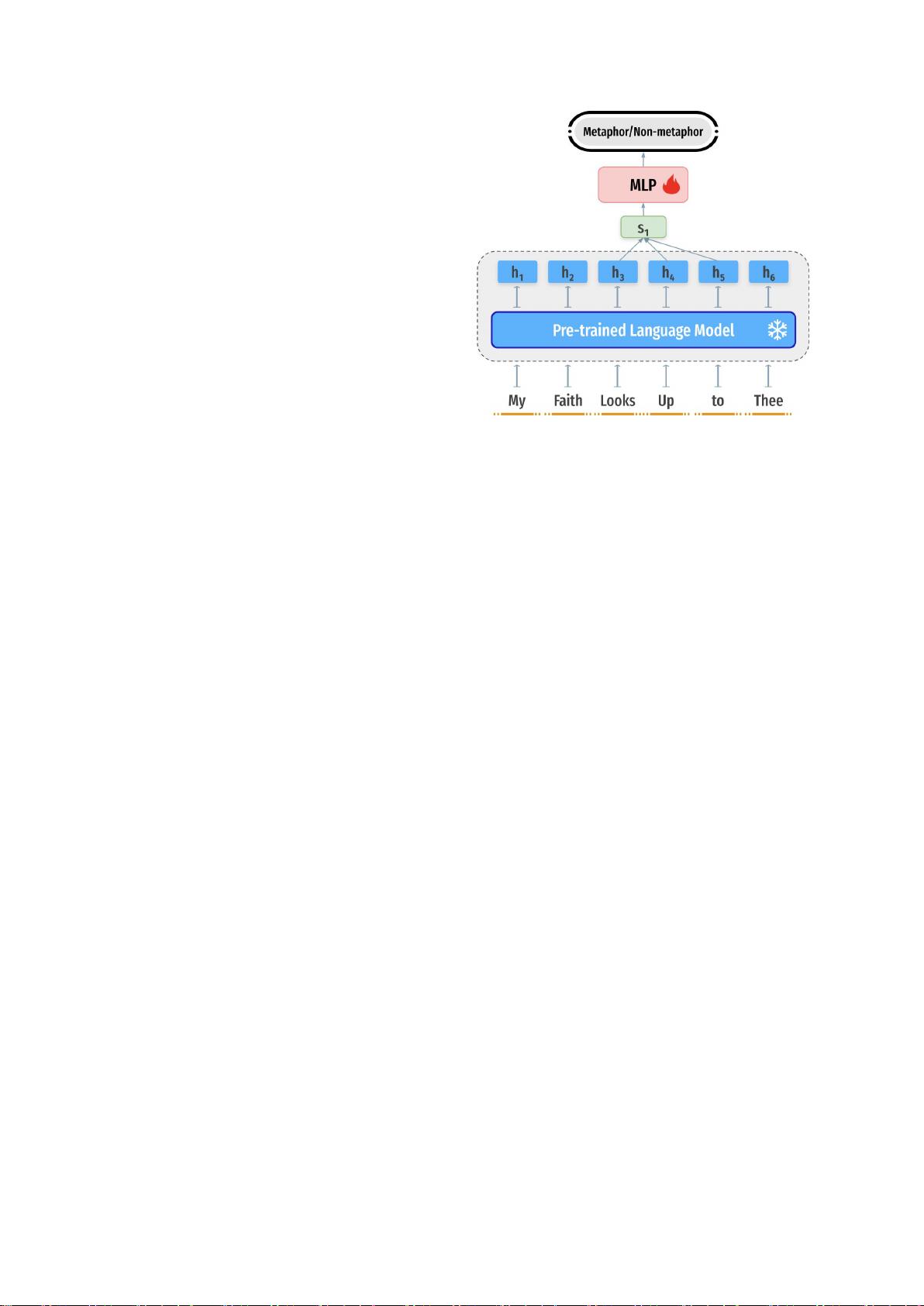
图2:边缘探测和MDL探测中使用的隐喻的探测架
构
在不同的领域,包括一个更基本的,具体的,
或身体相关的意义。例如,
(ii)查找令牌的源域是否与目标域相矛盾。 在
这里,对比是重要的,找到确切的域可能是不
必要的。其字面/基本含义所在的源域是一个
非上下文属性,而目标域主要是使用上下文线
索 找 到 的 ( 在 上 面 的 例 子 中 ,
WAR
和
ARGUMENT代表
在这里,我们使用基于这些理论注释的隐喻
检测数据集,并分析
PLM
表示,看看它们是
否编码隐喻知识,以及编码是否可推广。要做
到这一点,我们首先探测PLM的隐喻信息,
一般也跨层。这给了我们关于隐喻编码的直
觉,以及它的局部性或语境性。 然后,我们
测试, 如果多语言PLM能够捕捉到这一点,
那么隐喻检测的能力就可以跨语言转移。最
后,检查跨数据集的隐喻知识的泛化,以查看
不同数据集遵循的理论和注释是否一致,以及
PLM
是否学习可泛化的知识而不是数据集工
件。
3.1
探测
在这里,我们的目标是回答有关隐喻在PLM
中的一般性问题:做PLM编码隐喻的信息,
如果是这样,它是如何分布在他们的层。我们
并不追求最好的
剩余14页未读,继续阅读
2022-03-18 上传
2022-07-22 上传
2021-07-15 上传
2024-10-31 上传
2023-02-06 上传
2023-05-05 上传
2023-05-05 上传
2023-04-07 上传
2023-08-27 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
