深度优化网络爬虫:基于Python的数据采集程序
需积分: 1 41 浏览量
更新于2024-09-05
收藏 188KB DOCX 举报
"基于网络爬虫技术的数据采集程序设计,利用Python进行深度优化,解决等待时间、信息重叠和信息不完整等问题,适用于物联网时代的数据获取。"
在物联网和电子信息时代,网络信息资源的快速增长带来了对高效数据采集、存储、分析的需求。本文针对这一挑战,提出了一种基于网络爬虫技术的优化数据获取程序,该程序使用Python编程语言进行开发。Python因其丰富的库支持和简洁的语法,成为了网络爬虫开发的常用工具。
网络爬虫是一种自动浏览和提取网页内容的程序,通常从一组初始URL(种子)开始,逐步遍历网页并将其内容抓取下来。在设计过程中,本文特别关注了几个关键问题:等待时间管理、信息重叠处理和信息完整性保证。等待时间管理确保爬虫不会过于频繁地访问同一网站,避免对服务器造成过大的负担;信息重叠处理则解决了爬取过程中可能出现的重复数据问题,提高了数据收集的效率;信息完整性检查则确保了收集到的数据是完整的,没有缺失的部分。
在爬虫结构设计方面,本文采用了深度优先策略。这种策略允许爬虫深入挖掘特定领域的内容,尽管可能会忽视一些其他链接,但它更有利于物联网环境下特定目标信息的获取。与广度优先策略相比,深度优先策略在数据实时性和系统资源利用上具有优势,尤其适合于处理大量但相对集中的数据源。
考虑到物联网的动态性和多样性,传统的通用网络爬虫可能无法满足所有需求。因此,本文提出的优化爬虫程序引入了去复制功能,确保数据采集的独特性和完整性,这对于物联网环境中的数据分析和决策至关重要。同时,该程序设计还考虑到了系统的实时性、可靠性、健壮性和可扩展性,使其能够适应未来可能出现的新需求和技术变革。
总结来说,本文介绍的网络爬虫程序通过Python编程语言实现,结合深度优先策略,解决了物联网时代数据采集的挑战,提高了数据处理的效率和质量。这种方法为大数据分析、信息检索以及物联网应用提供了有力的技术支持,有助于我们更好地管理和利用海量的网络信息资源。
2018 年国际信息、电子和通信工程会议(iec2018)国际标准书号:978-1-60595-
585-8
基于网络爬虫技术的数据采集程序设计
桂林电子科技大学电子工程与自动化学院,中国关键词:网络爬虫,数据采集,物联网,编
程,Python。
摘要。随着物联网时代的到来和电子信息时代的蓬勃发展,网络信息资源呈指数级增长。面对
获取有用信息的需求,本文在通用网络爬虫技术的基础上,利用 Python 软件设计了一个深度
优化的网络爬虫数据获取程序。该爬虫程序能有效地解决等待时间、信息重叠和信息不完整等
一系列问题,使爬虫具有良好的性能。
引言
一般搜索引擎处理互联网网页,目前可以索引的网页数量至少有 217 亿页[1]。如何设计一个
有效的下载系统来在本地传输如此大量的网页数据,从而在互联网上创建一个镜像备份网页?
虽然网络爬虫技术可以发挥这样的作用,但随着物联网的不断发展,传统的通用网络爬虫技术
已经不能满足物联网的不断变化和人们的多样化追求。本文利用具有去复制功能的深度网络爬
虫技术,对大型杂物进行快速有效的数据采集,实现数据采集的不可重复性和完整性。
网络爬虫的结构设计
Webcrawler[2]是一个自动抓取网页并提取其内容的程序。如果设置了一个或多个统一资源定位
符 URL 种子集,则从种子网页收集数据。在获取网页内容的过程中,新的 URL 不断地被放入
URL 队列中,以便被抓取,直到满足某些条件为止。停止条件包括爬网队列为空且达到指定数
量的爬网的情况。
根据文献[3],主要的爬行策略有:1)宽度偏好和便利策略,2)深度优先的便利策略,3)反向连
接的数量,4)部分网页排名,5)OPIC,6)主站优先策略等。广度优先的便利策略易于实现,但
可能导致拒绝服务攻击等不良后果。深度优先的便利策略可以很容易地爬行到类似目标的地
方,但是您需要设置深度,否则可能无法找到解决方案。反向链接的数量会根据网页的重要性
而被抓取,缺点是在效果不够的情况下数据量不够大。部分 PageRank 将选择计算的 UR L 作为
爬行的优先级,但存在计算量大和响应速度慢的问题。Opic 的优点与反向链接的数量相同,但
缺点是部分 Pag eRank。虽然站优先策略具有较高的爬行效率,但是以往爬行数据的效果并不
明显。
为了使数据获取具有实时性、可靠性、健壮性和可扩展性,选择了一种通用网络爬虫体系结
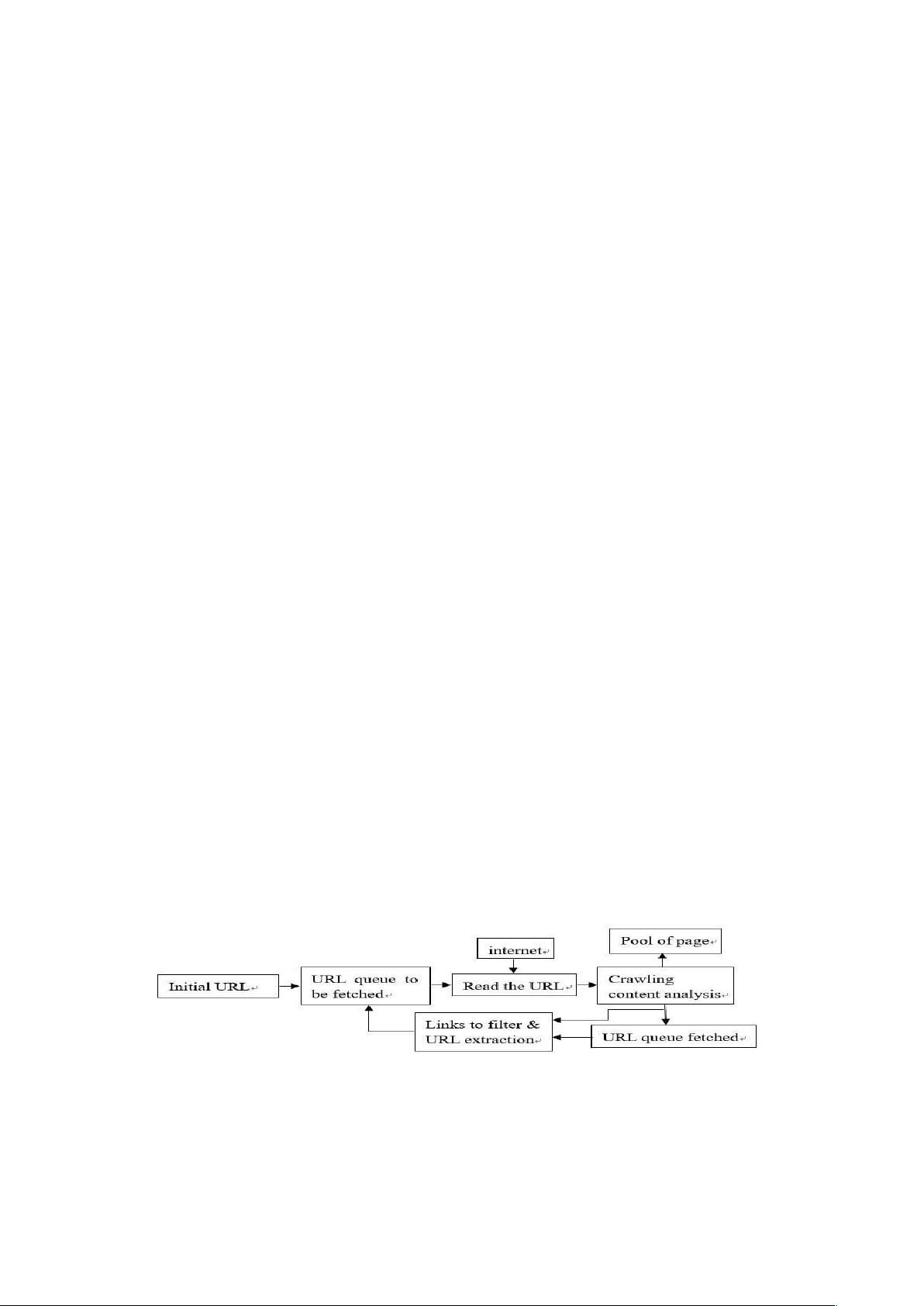
构的深度优先级策略进行数据获取[4]。它的一般网络爬虫架构如图 1 所示。
图 1.
通用网络爬虫系统结构图。
从图 1 可以看出,深度优先搜索/服务策略的工作路径从一个设置的种子 URL 开始,然后输
入和分析选定网页中的其他 URL。通过选择最佳匹配 URL 搜索和分析您输入的网页。这个循
环跟踪更深层的网址和网页内容。
基于 PageRank 值的网络爬虫优化及编程优化方案
218
下载后可阅读完整内容,剩余3页未读,立即下载
2022-09-21 上传
2022-09-24 上传
2021-09-30 上传
2021-04-13 上传
2022-09-14 上传
2022-02-28 上传
2022-02-20 上传

qq_40555115
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
