Zookeeper:分布式协调系统的基石
需积分: 7 102 浏览量
更新于2024-09-08
收藏 648KB DOCX 举报
"Zookeeper是Apache的一个开源项目,它是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现。Zookeeper设计的目标是封装那些复杂易出错的关键服务,提供简单易用的接口和高性能、高可用、功能稳定的服务。在Hadoop生态系统中,Zookeeper扮演了基础组件的角色,被广泛应用于如HDFS、YARN、Storm、HBase、Flume和Dubbo等系统中。"
Zookeeper的特点决定了其在分布式环境中的重要地位:
1. 最终一致性:客户端无论连接到哪个服务器,最终都能看到相同的数据视图。
2. 可靠性:一旦消息被一个服务器接受,它会被所有服务器接受,确保数据的可靠性。
3. 实时性:虽然不能保证实时获取最新数据,但可以通过sync()接口来获取。
4. 等待无关:快速客户端的请求不会受到慢速客户端的影响。
5. 原子性:更新操作要么完全成功,要么完全失败,不存在中间状态。
6. 顺序性:在所有服务器上,同一消息的发布顺序是一致的。
Zookeeper的基本工作原理涉及几个关键概念:
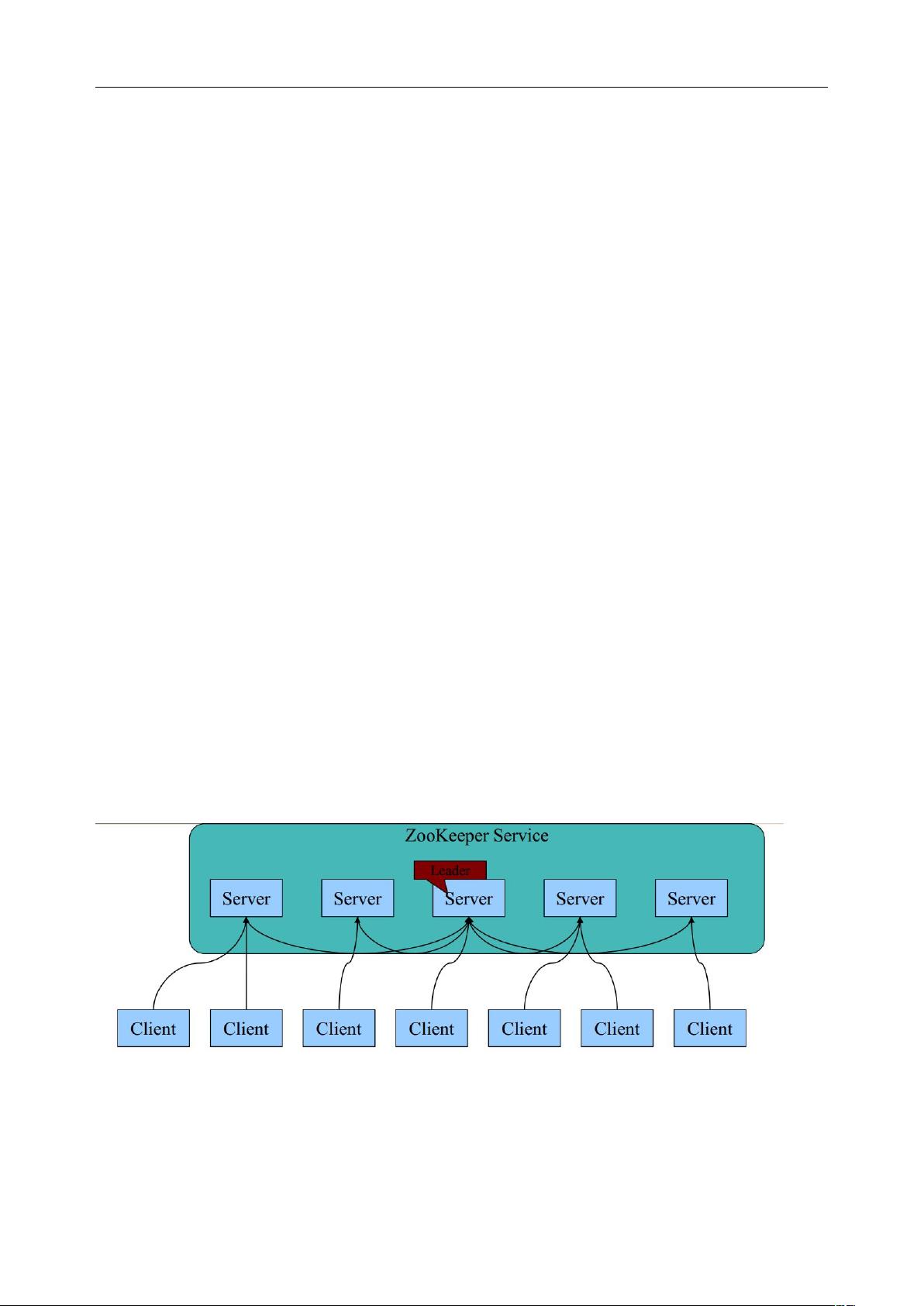
- 每个Zookeeper服务器都在内存中保存一份数据副本。
- 在启动时,通过Paxos算法选举出一个领导者(Leader),领导者负责处理所有数据更新操作。
- ZAB(Zookeeper Atomic Broadcast)协议用于确保更新操作的原子性和一致性。只有当大多数服务器在内存中成功更新数据时,更新才被视为成功。
- 从3.3.0版本开始,Zookeeper引入了Observer角色,Observer不参与投票过程,只转发写请求给Leader,从而提高了系统的伸缩性和吞吐率。
- 为了保证高可用性和强一致性,Zookeeper服务器通常设置为奇数个,如3、5或7,这样可以容忍一定数量的服务器故障。
Zookeeper的数据写入流程包括以下步骤:
1. 客户端向任意一个Zookeeper服务器发起写请求。
2. 如果该服务器是Follower,它会将请求转发给Leader。
3. Leader接收到请求后,发起一次提案(Proposal)并广播给所有Follower。
4. Follower接收到提案后,执行请求并回复确认信息。
5. 当Leader接收到超过半数Follower的确认后,更新操作完成,并广播结果给所有Follower和Observer。
6. Follower和Observer收到更新后,将数据同步到客户端。
Zookeeper的数据模型是层次化的目录结构,类似于文件系统的路径命名,例如"/app/config",使得数据管理和访问更为直观和方便。此外,Zookeeper还提供了watch机制,允许客户端对特定数据节点进行监听,一旦节点数据发生变化,客户端可以接收到通知,从而实现动态配置管理和事件驱动。Zookeeper为分布式系统提供了强大而可靠的协调能力,是构建大规模分布式应用不可或缺的工具。
文档编号:ESB004_PRJ700011(04)_0000
ESB4.0
1. ZooKeeper 是什么
是一个针对大型分布式系统的可靠协调系统;
提供的功能包括:配置维护、名字服务、分布式同步、组服务等;
目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户;
Zookeeper 已经成为 Hadoop 生态系统中的基础组件。
Zookeeper 特点
最终一致性:为客户端展示同一视图,这是 zookeeper 最重要的功能。
可靠性:如果消息被到一台服务器接受,那么它将被所有的服务器接受。
实时性: Zookeeper 不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据
之前调用 sync()接口。
等待无关( wait-free):慢的或者失效的 client 不干预快速的 client 的请求。
原子性:更新只能成功或者失败,没有中间状态。
顺序性:所有 Server,同一消息发布顺序一致。
哪些系统用到了 Zookeeper
HDFS
YARN
Storm
HBase
Flume
Dubbo(阿里巴巴)
metaq 阿里巴巴)
2. ZooKeeper 基本原理
每个 Server 在内存中存储了一份数据;
Zookeeper 启动时,将从实例中选举一个 leader( Paxos 协议);
Leader 负责处理数据更新等操作( Zab 协议);
第 1 页(共 9 页)
下载后可阅读完整内容,剩余8页未读,立即下载
106 浏览量
2022-08-03 上传
2020-08-26 上传
2019-08-09 上传
2021-10-15 上传
2021-10-15 上传
2022-05-21 上传
2018-07-21 上传

commanager
- 粉丝: 8
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- NIST REFPROP问题反馈与解决方案存储库
- 掌握LeetCode习题的系统开源答案
- ctop:实现汉字按首字母拼音分类排序的PHP工具
- 微信小程序课程学习——投资融资类产品说明
- Matlab犯罪模拟器开发:探索《当蛮力失败》犯罪惩罚模型
- Java网上招聘系统实战项目源码及部署教程
- OneSky APIPHP5库:PHP5.1及以上版本的API集成
- 实时监控MySQL导入进度的bash脚本技巧
- 使用MATLAB开发交流电压脉冲生成控制系统
- ESP32安全OTA更新:原生API与WebSocket加密传输
- Sonic-Sharp: 基于《刺猬索尼克》的开源C#游戏引擎
- Java文章发布系统源码及部署教程
- CQUPT Python课程代码资源完整分享
- 易语言实现获取目录尺寸的Scripting.FileSystemObject对象方法
- Excel宾果卡生成器:自定义和打印多张卡片
- 使用HALCON实现图像二维码自动读取与解码
