理解数据挖掘:经典决策树算法详解
需积分: 10 134 浏览量
更新于2024-07-24
1
收藏 1.5MB PDF 举报
"数据挖掘进阶之经典算法"
数据挖掘进阶之经典算法是深入学习数据挖掘领域不可或缺的一部分,其中包含了各种用于分析大量数据并提取有用信息的算法。这些算法是机器学习和数据科学的核心工具,帮助专业人士从海量数据中发现模式、趋势和规律。
决策树算法是数据挖掘中的一个重要组成部分,它是一种基于树形结构进行决策的模型。每个内部节点代表一个特征或属性,每个分支代表该特征的一个可能值,而叶节点则表示一个决策结果。决策树通过不断地分裂数据集,依据各个特征的重要性,直至所有实例都属于同一类别或者达到预设的停止条件。ID3算法是早期的决策树构建算法,它使用信息增益作为特征选择的标准,以最大化类别信息的纯度。在ID3的基础上,后续出现了C4.5和CART等更优化的决策树算法,它们能处理连续数值型特征,并对过大的决策树进行剪枝,以防止过拟合。
在决策树的基础上,随机森林算法进一步提升了分类的准确性和鲁棒性。随机森林是由多棵决策树组成的集成模型,每棵树在训练时都使用了随机选取的特征和样本,这样可以减少模型间的相关性,提高整体预测性能。随机森林不仅可以用于分类,还能进行回归任务,并且能够评估特征的重要性。
数据挖掘的经典算法还包括了其他的模型,如聚类算法(如K-Means、DBSCAN)、关联规则学习(如Apriori、FP-Growth)以及回归分析(如线性回归、逻辑回归)。这些算法在实际应用中各有优势,例如,聚类用于发现数据的自然群体,关联规则用于发现项集之间的频繁模式,回归分析则用于预测连续的输出变量。
决策树工作时,会根据信息熵、基尼不纯度等标准来选择最优的特征进行划分。生成的规则易于理解和解释,这对于业务决策和非技术人员来说特别有价值。然而,决策树可能会过于复杂或过于简单,导致过拟合或欠拟合,因此需要调整模型参数和使用正则化技术。
数据挖掘进阶之经典算法涉及一系列复杂而强大的工具,它们是数据科学家在处理复杂问题时的有力武器。通过理解并熟练运用这些算法,可以在大量数据中挖掘出宝贵的知识,为业务决策提供数据支持,推动科学研究和技术创新。无论是决策树、随机森林还是其他算法,都需要通过实践和不断的优化来提高模型的性能和实用性。
人工神经网络研究的局限性:
研究受到脑科学研究成果的限制;
缺少一个完整、成熟的理论体系;
研究带有浓厚的策略和经验色彩;
与传统技术的接口不成熟。
一般而言, ANN 与经典计算方法相比并非优越, 只有当常规方法解决不了或效果不佳
时 ANN 方法才能显示出其优越性。尤其对问题的机理不甚了解或不能用数学模型表示的系
统,如故障诊断、特征提取和预测等问题,ANN 往往是最有利的工具。另一方面, ANN 对处理
大量原始数据而不能用规则或公式描述的问题, 表现出极大的灵活性和自适应性。
8.1 BP 网络
人工神经网络以其具有自学习、自组织、较好的容错性和优良的非线性逼近能力,受到
众多领域学者的关注。在实际应用中,80%~90%的人工神经网络模型是采用误差反传算法
或其变化形式的网络模型(简称 BP 网络),目前主要应用于函数逼近、模式识别、分类和
数据压缩或数据挖掘。
(1)BP 网络建模特点:
非线性映照能力:神经网络能以任意精度逼近任何非线性连续函数。在建模过程中
的许多问题正是具有高度的非线性。
并行分布处理方式:在神经网络中信息是分布储存和并行处理的,这使它具有很
强的容错性和很快的处理速度。
自学习和自适应能力:神经网络在训练时,能从输入、输出的数据中提取出规律
性的知识,记忆于网络的权值中,并具有泛化能力,即将这组权值应用于一般情形
的能力。神经网络的学习也可以在线进行。
数据融合的能力:神经网络可以同时处理定量信息和定性信息,因此它可以利用传
统的工程技术(数值运算)和人工智能技术(符号处理)。
多变量系统:神经网络的输入和输出变量的数目是任意的,对单变量系统与多变量
系统提供了一种通用的描述方式,不必考虑各子系统间的解耦问题。
(2)样本数据的收集和整理分组:
采用 BP 神经网络方法建模的首要和前提条件是有足够多典型性好和精度高的样本。而
且,为监控训练(学习)过程使之不发生“过拟合”和评价建立的网络模型的性能和泛化能力,
必须将收集到的数据随机分成训练样本、检验样本(10%以上)和测试样本(10%以上)3
部分。此外,数据分组时还应尽可能考虑样本模式间的平衡。
由于传统的误差反传 BP 算法较为成熟,且应用广泛,因此努力提高该方法的学习速度
具有较高的实用价值。BP 算法中有几个常用的参数,包括学习率η,动量因子α,形状因
子λ及收敛误差界值 E 等。这些参数对训练速度的影响最为关键。
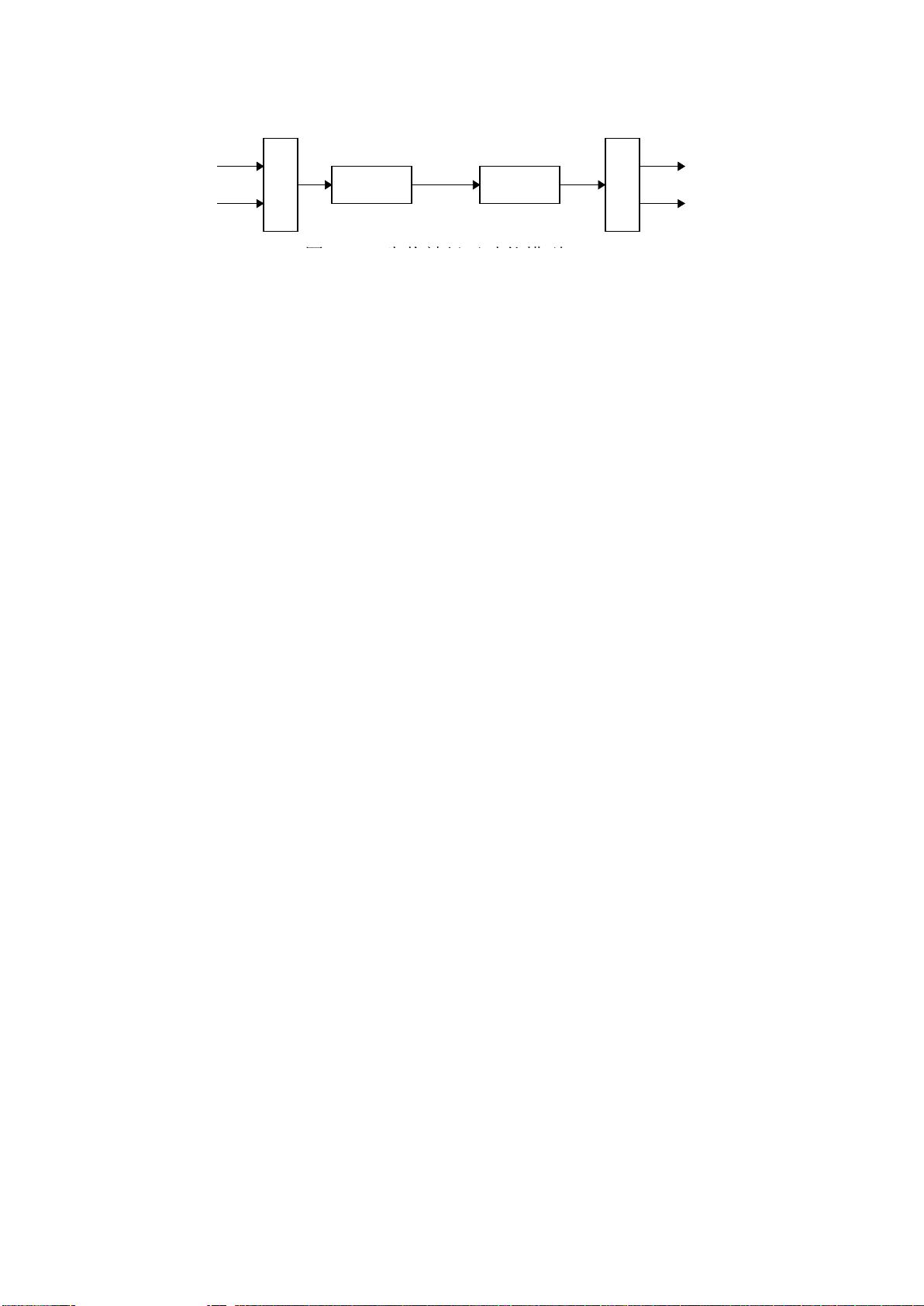
9 Fisher 分类器
细胞体
突
触
轴突
树
突
图
生物神经元功能模型
输
入
输
出
信息处理
电脉冲
形成
传输
神经网络基本模型

剩余51页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-07-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

狂奔在大雨中
- 粉丝: 2
- 资源: 27
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
