预训练新篇章:XLNet与无监督学习的未来
需积分: 5 67 浏览量
更新于2024-07-06
收藏 5.99MB PDF 举报
“XLNet and Beyond——一种利用无监督学习提升自然语言处理性能的方法”
在自然语言处理(NLP)领域,XLNet是一种由杨植麟等人在NeurIPS 2019大会上提出的创新模型,它在预训练阶段利用了丰富的无标签数据,旨在提高模型的监督学习能力。XLNet是继词嵌入模型(如word2vec和GloVe)、半监督序列学习(如Semi-supervised sequence learning)、以及自注意力机制的先驱——BERT之后的又一里程碑式工作。
传统的预训练技术,如受限玻尔兹曼机(RBMs)、自编码器(Autoencoders)、拼图任务(Jigsaw)和生成对抗网络(GANs),以及词向量模型(如word2vec和GloVe),主要关注无监督学习,通过学习数据的内在结构来提升模型的表示能力。然而,这些方法在处理语言理解时,往往无法充分利用上下文信息。
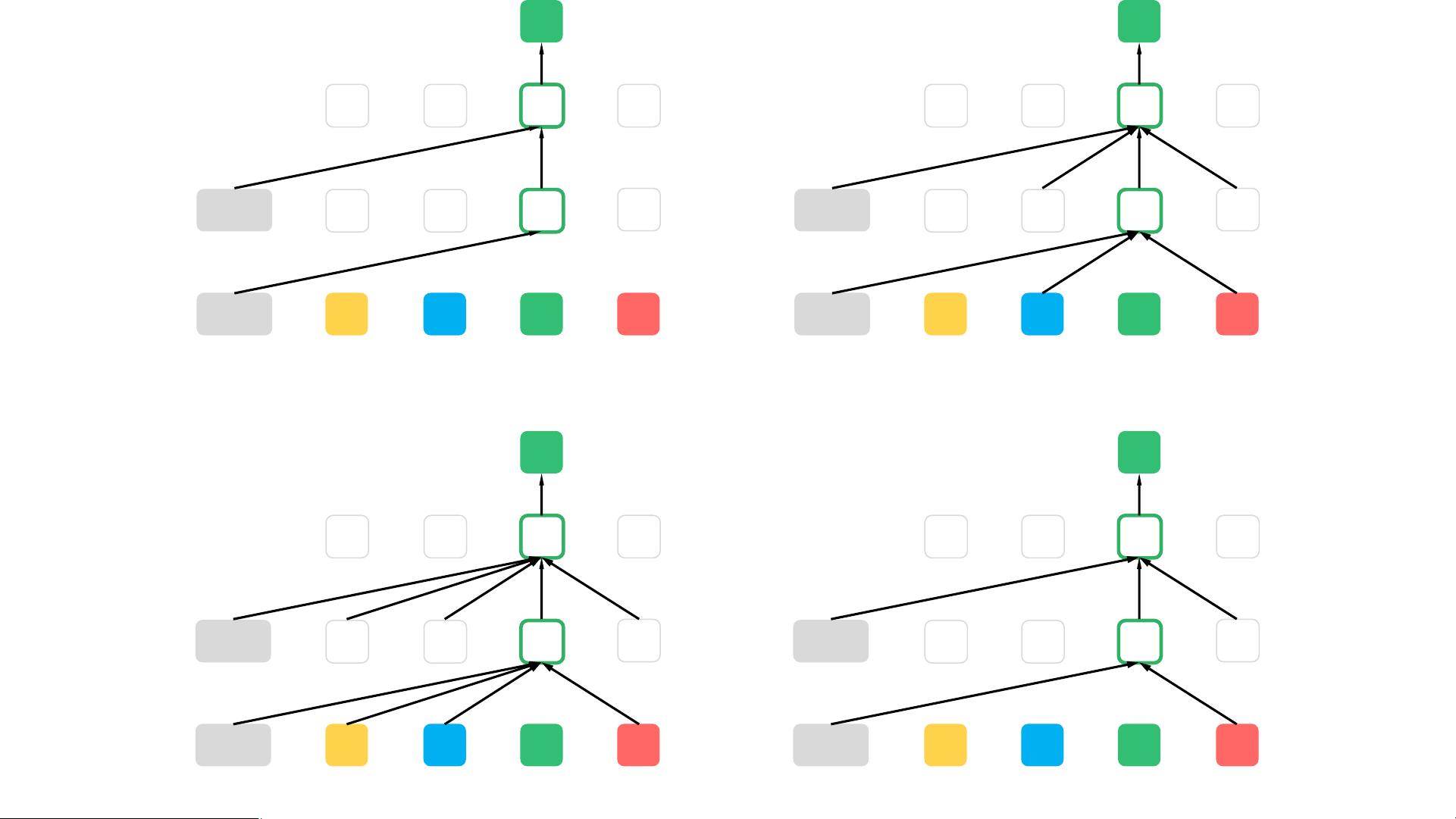
XLNet引入了一种新的预训练目标——“Permutation Language Modeling”(PLM),解决了BERT在双向上下文建模上的局限性。BERT采用的是填充掩码(Masked Language Modeling, MLM)策略,即随机遮蔽一部分输入序列中的词汇,然后让模型预测被遮蔽的词汇,但这种方法限制了模型对完整序列的双向理解,因为被遮蔽的词不能依赖于其后的信息进行预测。
XLNet则采用自回归(Auto-regressive)和自编码(Auto-encoding)两种目标的结合,它基于Transformer架构,通过循环处理输入序列的不同子集,允许模型在预测每个位置的词汇时考虑其前后的上下文信息。这种方法称为“Transformer-XL”,它克服了BERT的单向预测限制,实现了真正的双向上下文建模。
此外,XLNet还引入了“Denoising Auto-encoding”(去噪自编码),即在预训练阶段引入噪声,如随机替换、删除或插入一些词汇,使模型在恢复原始序列的同时学习更强大的语言结构和语义信息。这一策略进一步增强了模型的鲁棒性和泛化能力。
在预训练完成后,XLNet可以像BERT一样进行微调,适应各种下游NLP任务,如问答、文本分类、情感分析等。实验证明,XLNet在多项NLP基准测试上取得了超越BERT的性能,展示了无监督预训练在提升模型性能方面的巨大潜力。
“XLNet and Beyond”不仅代表了XLNet模型本身的技术突破,也预示着未来NLP研究将继续探索如何更好地利用无监督学习,挖掘大规模无标签数据的潜在价值,以推动自然语言处理技术的持续发展。

Examples
P(New York is a city)
= P(New) * P(York | New) * P(is | New York) * P(a | New York is) * P(city | New York is a)
Factorization order: New York is a city
Factorization order: city a is New York
P(New York is a city)
= P(city) * P(a | city) * P(is | city a) * P(New | city a is) * P(York | city a is New)
Sequence order is not shuffled.
Attention masks are changed to reflect factorization order.
剩余49页未读,继续阅读
2019-09-19 上传
2020-09-29 上传
2021-05-24 上传
2021-02-03 上传
2022-08-03 上传
2021-03-14 上传
2021-05-15 上传
2021-02-03 上传

yao0jc
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
