掌握MySQL查询缓存机制:原理、适用场景与失效规则
38 浏览量
更新于2024-08-30
收藏 321KB PDF 举报
MySQL的查询缓存机制是一种性能优化技术,它通过在内存中存储已执行过的SQL语句及其结果,以提高后续相同查询的执行速度。当服务器接收到一个SQL请求时,首先会在查询缓存中查找是否存在与之匹配的记录。如果找到,服务器直接返回缓存的结果,避免了重新解析和执行SQL;若未找到,则进行正常的SQL执行,并将结果存入缓存供后续使用。
命中条件非常重要,因为SQL的任何字符差异,如空格、注释的变化,都会导致缓存不命中。此外,包含不确定数据(如函数CURRENT_DATE()和NOW())的查询不会被缓存,因为这些值会随时间变化。因此,对于频繁更新的表或包含动态值的查询,查询缓存可能不是最佳选择。
查询缓存的工作流程如下:
1. **缓存查找**:服务器在接收到SQL后,首先尝试使用SQL和特定条件在缓存中查找。
2. **缓存命中**:如果找到缓存,立即返回结果,节省解析和执行时间。
3. **缓存未命中**:如果未找到,执行SQL,执行解析、优化,然后将结果存入缓存。
4. **缓存写入**:每次查询结束后,将结果写入缓存,但可能需要额外性能消耗。
然而,缓存并非在所有情况下都是有益的。当表正在写入数据(如InnoDB的事务修改),或者整个事务期间,缓存可能会失效。这是因为缓存需要确保数据的一致性,不能在写操作期间提供准确的结果。此外,MySQL使用内存管理策略来分配和组织查询缓存,它将一个大的内存区域划分为小的存储块,每块存储查询结果、元数据以及指针,以实现高效的内存利用和访问。
在配置查询缓存时,需要考虑内存限制(query_cache_size)、查询缓存块的最小尺寸(query_cache_min_res_unit)以及表的更新频率。查询缓存对读密集型应用且SQL重复度高的场景非常有用,但对于频繁更新或涉及不确定数据的场景,应谨慎使用或关闭缓存,以避免潜在的数据一致性问题。
MySQL的查询缓存机制基本学习教程的查询缓存机制基本学习教程
MySQL缓存机制简单的说就是缓存sql文本及查询结果,如果运行相同的sql,服务器直接从缓存中取到结果,而不需要再去解析和执行sql。如果表更
改 了,那么使用这个表的所有缓冲查询将不再有效,查询缓存值的相关条目被清空。更改指的是表中任何数据或是结构的改变,包括INSERT、
UPDATE、 DELETE、TRUNCATE、ALTER TABLE、DROP TABLE或DROP DATABASE等,也包括那些映射到改变了的表的使用MERGE表的查
询。显然,这对于频繁更新的表,查询缓存是不适合的,而对于一些不常改变数据且有 大量相同sql查询的表,查询缓存会节约很大的性能。
命中条件命中条件
缓存存在一个hash表中,通过查询SQL,查询数据库,客户端协议等作为key.在判断是否命中前,MySQL不会解析SQL,而是直接使用SQL去查询缓存,SQL
任何字符上的不同,如空格,注释,都会导致缓存不命中.
如果查询中有不确定数据,例如CURRENT_DATE()和NOW()函数,那么查询完毕后则不会被缓存.所以,包含不确定数据的查询是肯定不会找到可用缓存
的
工作流程工作流程
1. 服务器接收SQL,以SQL和一些其他条件为key查找缓存表(额外性能消耗)
2. 如果找到了缓存,则直接返回缓存(性能提升)
3. 如果没有找到缓存,则执行SQL查询,包括原来的SQL解析,优化等.
4. 执行完SQL查询结果以后,将SQL查询结果存入缓存表(额外性能消耗)
缓存失效缓存失效
当某个表正在写入数据,则这个表的缓存(命中检查,缓存写入等)将会处于失效状态.在Innodb中,如果某个事务修改了表,则这个表的缓存在事务提交前都
会处于失效状态,在这个事务提交前,这个表的相关查询都无法被缓存.
缓存的内存管理缓存的内存管理
缓存会在内存中开辟一块内存(query_cache_size)来维护缓存数据,其中有大概40K的空间是用来维护缓存的元数据的,例如空间内存,数据表和查询结果
的映射,SQL和查询结果的映射等.
MySQL将这个大内存块分为小的内存块(query_cache_min_res_unit),每个小块中存储自身的类型,大小和查询结果数据,还有指向前后内存块的指针.
MySQL需要设置单个小存储块的大小,在SQL查询开始(还未得到结果)时就去申请一块空间,所以即使你的缓存数据没有达到这个大小,也需要用这个大小
的数据块去存(这点跟Linux文件系统的Block一样).如果结果超出这个内存块的大小,则需要再去申请一个内存块.当查询完成发现申请的内存块有富余,则
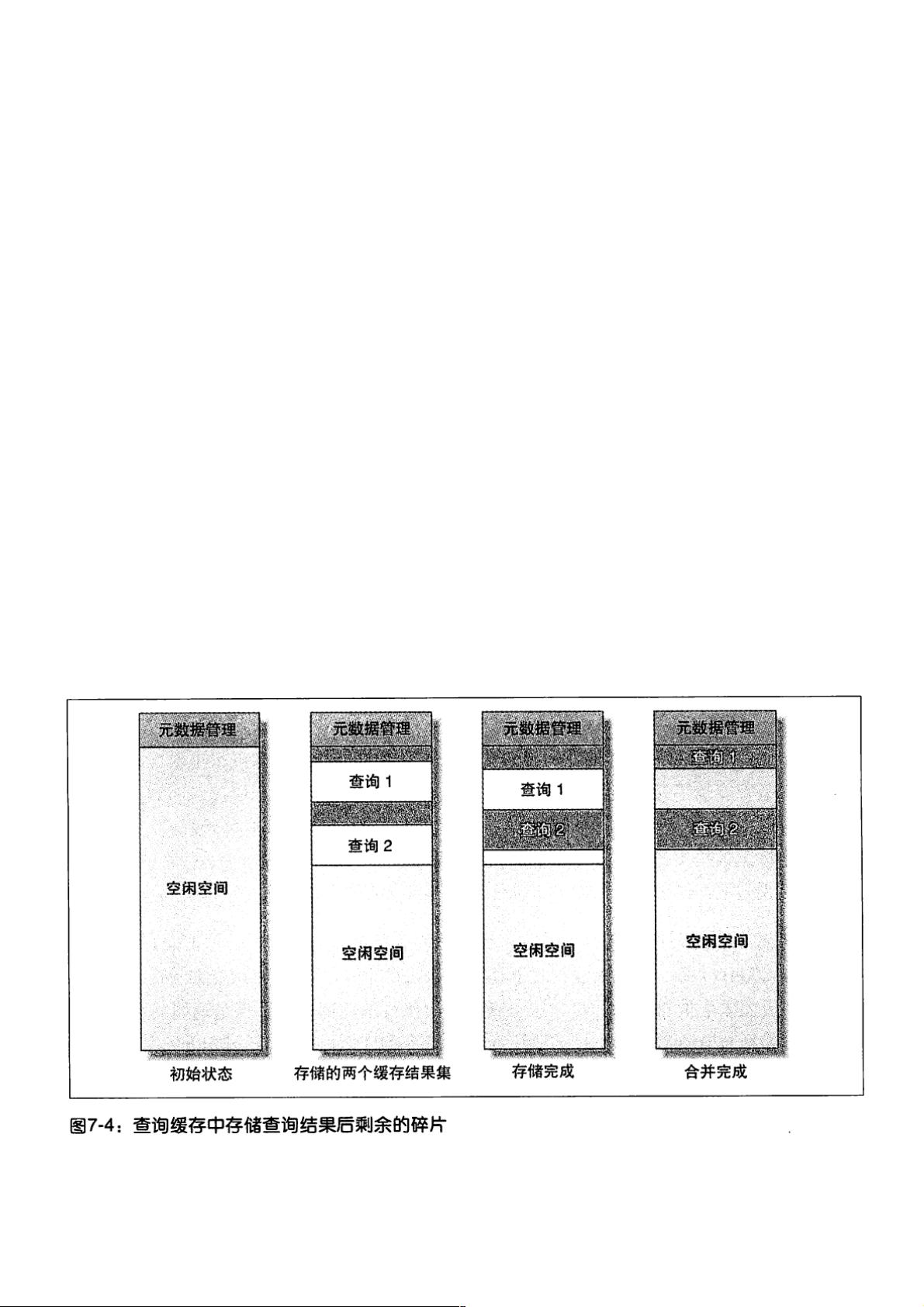
会将富余的空间释放掉,这就会造成内存碎片问题,见下图
此处查询1和查询2之间的空白部分就是内存碎片,这部分空闲内存是有查询1查询完以后释放的,假设这个空间大小小于MySQL设定的内存块大小,则无法
再被使用,造成碎片问题
在查询开始时申请分配内存Block需要锁住整个空闲内存区,所以分配内存块是非常消耗资源的.注意这里所说的分配内存是在MySQL初始化时就开辟的
那块内存上分配的.
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2010-12-09 上传
2016-11-18 上传
2018-07-31 上传
2024-05-30 上传
2010-02-02 上传
2005-07-28 上传

weixin_38653602
- 粉丝: 6
- 资源: 936
 我的内容管理
展开
我的内容管理
展开







最新资源
- 操作员:高效,可移动的操作员库
- android-EventBus
- 油漆:w JS
- Matchy
- Acquire-code:该项目旨在通过划分设备的内部硬盘驱动器,然后使用Xfinity Hot Spots插入代码使(现在的犯罪分子)成为“超级用户”,来识别和了解不断增加的被盗手机事件。 绝对可以访问内部和外部驱动器上的任何数据。 最终结果是“ VICTIM”,所有隐私,此特定的MalwareSpywareVirus还访问了“零号患者”联系人的讨厌的驱动器。 我在马萨诸塞州剑桥市的一个小型办公室工作。 我的办公室就在MIT和HARVARD之间。 在这1英里长的MASS AVE中。 它影响了最近从当前正
- VassoD.github.io
- valor-style-guides:公司共享的风格指南和做法
- 用户汽车满意度预测.zip
- rogue.vim:为Vim移植Rogue-clone II
- ChatKit
- My-Drinking-Duo:拉姆哈克
- prog-1:1 UFSC-Joinville的课程资料库
- MCU-Font-Release,好用的LVGL的多语言转换工具!
- java_basics
- Deep-Forest:Deep Forest 2021.2.1的实现
- Mathematics Libraries-开源
