SparkSQL1.1.0深度解析:从基础到进阶
需积分: 24 199 浏览量
更新于2024-07-20
收藏 3.92MB DOCX 举报
"Spark学习总结,作者何成俭,涵盖了Spark 1.1.0版本的更新内容,尤其是Spark SQL的增强,包括JDBC/ODBC Server、JSON和Parquet文件支持、UDF注册以及动态字节码生成技术。文章分为十个部分,详细介绍了Spark SQL的架构、使用、组件解析、运行机制、测试环境搭建、基础应用、ThriftServer与CLI、综合应用等。"
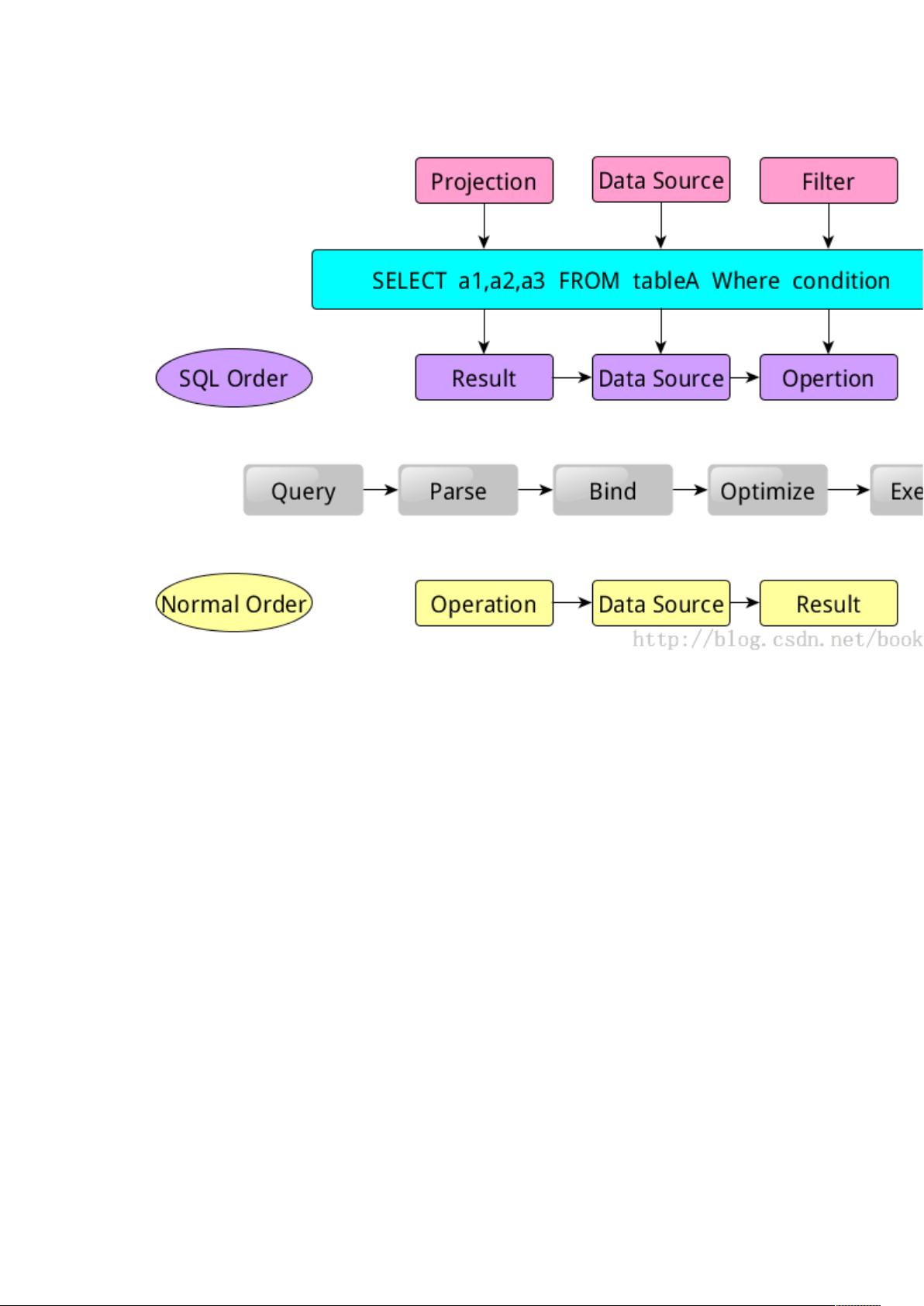
在大数据处理领域,Spark以其高效、易用的特点,成为了众多开发者和数据科学家的首选工具。Spark的核心在于它的弹性分布式数据集(RDD),它提供了容错性和并行计算的能力。SparkContext是Spark程序的入口点,它负责连接到集群并创建RDD。在Spark 1.1.0版本中,Spark SQL的引入极大地增强了Spark处理结构化数据的能力。
Spark SQL的更新点包括:
1. **JDBC/ODBC Server(ThriftServer)**: 这使得用户可以通过标准的JDBC或ODBC协议直接连接到Spark SQL,从而在任何支持这些协议的工具中使用Spark SQL的数据。
2. **JSON支持**: Spark SQL增加了对JSON文件的读取和写入,方便了非结构化数据的处理。
3. **Parquet优化**: Parquet是一种列式存储格式,Spark 1.1.0增强了对Parquet文件的本地优化,提高了读取和写入速度。
4. **UDF注册**: 用户现在可以将Python、Scala、Java的lambda函数注册为用户定义函数(UDF),并在SQL查询中直接调用。
5. **动态字节码生成(CG)**: 通过引入动态字节码生成技术,Spark SQL显著提升了复杂表达式的执行速度。
文章将Spark SQL的介绍分为十个章节,逐步深入:
- **第一部分**:概述Spark SQL的发展和性能优势。
- **第二部分**:介绍Catalyst优化器,以及sqlContext和hiveContext的架构和差异。
- **第三部分**:深入讨论Spark SQL的组件,如解析器、优化器和执行器。
- **第四部分**:通过示例展示Spark SQL的执行计划生成过程。
- **第五部分**:介绍测试环境的搭建和测试数据准备。
- **第六部分**:基础应用教程,涵盖RDD、JSON和Parquet数据的处理,以及与Hive的集成。
- **第七部分**:讲解ThriftServer和命令行接口(CLI)的使用,以及通过JDBC访问Spark SQL数据的方法。
- **第八部分**:探讨Spark SQL与其他组件如MLlib、GraphX的综合应用。
通过这篇总结,读者将能够全面了解Spark SQL在1.1.0版本中的新特性,以及如何在实践中应用这些特性,进行高效的数据处理和分析。


2019-09-14 上传
2018-04-27 上传
2017-11-06 上传
2022-09-24 上传
2017-12-05 上传
2021-11-19 上传
2021-02-26 上传

loveothersasself
- 粉丝: 226
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







